 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Seismic Wavefield Common Task Framework
Dec 22, 2025Seismology faces fundamental challenges in state forecasting and reconstruction (e.g., earthquake early warning and ground motion prediction) and managing the parametric variability of source locations, mechanisms, and Earth models (e.g., subsurface structure and topography effects). Addressing these with simulations is hindered by their massive scale, both in synthetic data volumes and numerical complexity, while real-data efforts are constrained by models that inadequately reflect the Earth's complexity and by sparse sensor measurements from the field. Recent machine learning (ML) efforts offer promise, but progress is obscured by a lack of proper characterization, fair reporting, and rigorous comparisons. To address this, we introduce a Common Task Framework (CTF) for ML for seismic wavefields, starting with three distinct wavefield datasets. Our CTF features a curated set of datasets at various scales (global, crustal, and local) and task-specific metrics spanning forecasting, reconstruction, and generalization under realistic constraints such as noise and limited data. Inspired by CTFs in fields like natural language processing, this framework provides a structured and rigorous foundation for head-to-head algorithm evaluation. We illustrate the evaluation procedure with scores reported for two of the datasets, showcasing the performance of various methods and foundation models for reconstructing seismic wavefields from both simulated and real-world sensor measurements. The CTF scores reveal the strengths, limitations, and suitability for specific problem classes. Our vision is to replace ad hoc comparisons with standardized evaluations on hidden test sets, raising the bar for rigor and reproducibility in scientific ML.
Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
Nov 19, 2025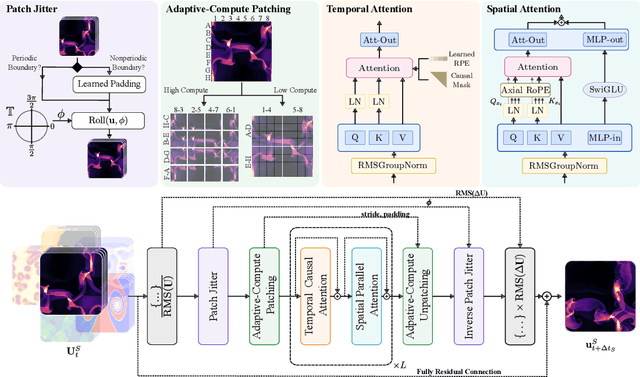


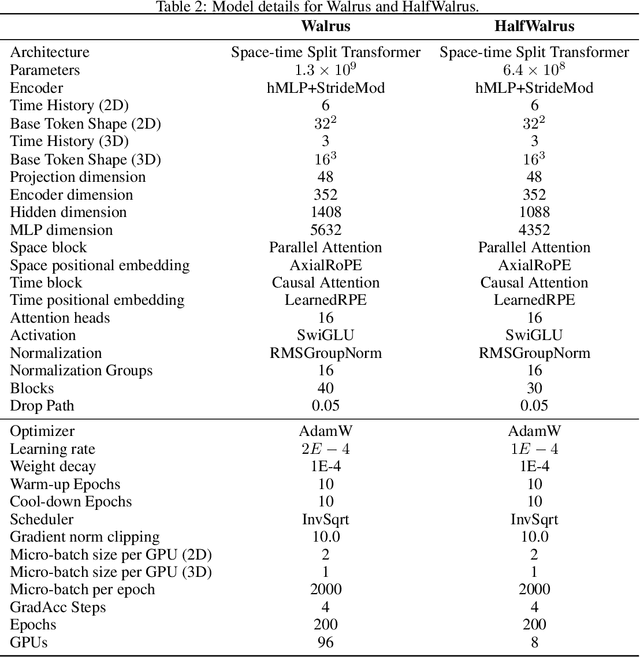
Foundation models have transformed machine learning for language and vision, but achieving comparable impact in physical simulation remains a challenge. Data heterogeneity and unstable long-term dynamics inhibit learning from sufficiently diverse dynamics, while varying resolutions and dimensionalities challenge efficient training on modern hardware. Through empirical and theoretical analysis, we incorporate new approaches to mitigate these obstacles, including a harmonic-analysis-based stabilization method, load-balanced distributed 2D and 3D training strategies, and compute-adaptive tokenization. Using these tools, we develop Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics. Walrus is pretrained on nineteen diverse scenarios spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids. Experiments show that Walrus outperforms prior foundation models on both short and long term prediction horizons on downstream tasks and across the breadth of pretraining data, while ablation studies confirm the value of our contributions to forecast stability, training throughput, and transfer performance over conventional approaches. Code and weights are released for community use.
The Denario project: Deep knowledge AI agents for scientific discovery
Oct 30, 2025We present Denario, an AI multi-agent system designed to serve as a scientific research assistant. Denario can perform many different tasks, such as generating ideas, checking the literature, developing research plans, writing and executing code, making plots, and drafting and reviewing a scientific paper. The system has a modular architecture, allowing it to handle specific tasks, such as generating an idea, or carrying out end-to-end scientific analysis using Cmbagent as a deep-research backend. In this work, we describe in detail Denario and its modules, and illustrate its capabilities by presenting multiple AI-generated papers generated by it in many different scientific disciplines such as astrophysics, biology, biophysics, biomedical informatics, chemistry, material science, mathematical physics, medicine, neuroscience and planetary science. Denario also excels at combining ideas from different disciplines, and we illustrate this by showing a paper that applies methods from quantum physics and machine learning to astrophysical data. We report the evaluations performed on these papers by domain experts, who provided both numerical scores and review-like feedback. We then highlight the strengths, weaknesses, and limitations of the current system. Finally, we discuss the ethical implications of AI-driven research and reflect on how such technology relates to the philosophy of science. We publicly release the code at https://github.com/AstroPilot-AI/Denario. A Denario demo can also be run directly on the web at https://huggingface.co/spaces/astropilot-ai/Denario, and the full app will be deployed on the cloud.
Open Source Planning & Control System with Language Agents for Autonomous Scientific Discovery
Jul 09, 2025We present a multi-agent system for automation of scientific research tasks, cmbagent. The system is formed by about 30 Large Language Model (LLM) agents and implements a Planning & Control strategy to orchestrate the agentic workflow, with no human-in-the-loop at any point. Each agent specializes in a different task (performing retrieval on scientific papers and codebases, writing code, interpreting results, critiquing the output of other agents) and the system is able to execute code locally. We successfully apply cmbagent to carry out a PhD level cosmology task (the measurement of cosmological parameters using supernova data) and evaluate its performance on two benchmark sets, finding superior performance over state-of-the-art LLMs. The source code is available on GitHub, demonstration videos are also available, and the system is deployed on HuggingFace and will be available on the cloud.
Call for Action: towards the next generation of symbolic regression benchmark
May 06, 2025


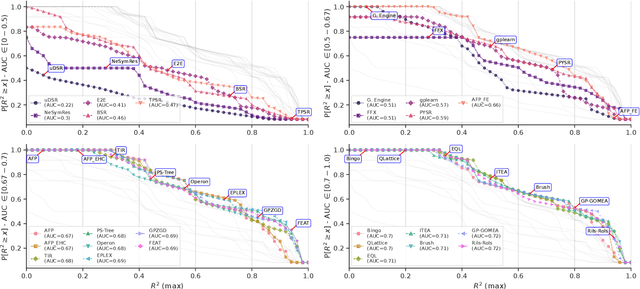
Symbolic Regression (SR) is a powerful technique for discovering interpretable mathematical expressions. However, benchmarking SR methods remains challenging due to the diversity of algorithms, datasets, and evaluation criteria. In this work, we present an updated version of SRBench. Our benchmark expands the previous one by nearly doubling the number of evaluated methods, refining evaluation metrics, and using improved visualizations of the results to understand the performances. Additionally, we analyze trade-offs between model complexity, accuracy, and energy consumption. Our results show that no single algorithm dominates across all datasets. We propose a call for action from SR community in maintaining and evolving SRBench as a living benchmark that reflects the state-of-the-art in symbolic regression, by standardizing hyperparameter tuning, execution constraints, and computational resource allocation. We also propose deprecation criteria to maintain the benchmark's relevance and discuss best practices for improving SR algorithms, such as adaptive hyperparameter tuning and energy-efficient implementations.
The Well: a Large-Scale Collection of Diverse Physics Simulations for Machine Learning
Nov 30, 2024



Machine learning based surrogate models offer researchers powerful tools for accelerating simulation-based workflows. However, as standard datasets in this space often cover small classes of physical behavior, it can be difficult to evaluate the efficacy of new approaches. To address this gap, we introduce the Well: a large-scale collection of datasets containing numerical simulations of a wide variety of spatiotemporal physical systems. The Well draws from domain experts and numerical software developers to provide 15TB of data across 16 datasets covering diverse domains such as biological systems, fluid dynamics, acoustic scattering, as well as magneto-hydrodynamic simulations of extra-galactic fluids or supernova explosions. These datasets can be used individually or as part of a broader benchmark suite. To facilitate usage of the Well, we provide a unified PyTorch interface for training and evaluating models. We demonstrate the function of this library by introducing example baselines that highlight the new challenges posed by the complex dynamics of the Well. The code and data is available at https://github.com/PolymathicAI/the_well.
SymbolFit: Automatic Parametric Modeling with Symbolic Regression
Nov 15, 2024



We introduce SymbolFit, a framework that automates parametric modeling by using symbolic regression to perform a machine-search for functions that fit the data, while simultaneously providing uncertainty estimates in a single run. Traditionally, constructing a parametric model to accurately describe binned data has been a manual and iterative process, requiring an adequate functional form to be determined before the fit can be performed. The main challenge arises when the appropriate functional forms cannot be derived from first principles, especially when there is no underlying true closed-form function for the distribution. In this work, we address this problem by utilizing symbolic regression, a machine learning technique that explores a vast space of candidate functions without needing a predefined functional form, treating the functional form itself as a trainable parameter. Our approach is demonstrated in data analysis applications in high-energy physics experiments at the CERN Large Hadron Collider (LHC). We demonstrate its effectiveness and efficiency using five real proton-proton collision datasets from new physics searches at the LHC, namely the background modeling in resonance searches for high-mass dijet, trijet, paired-dijet, diphoton, and dimuon events. We also validate the framework using several toy datasets with one and more variables.
Symbolic Regression with a Learned Concept Library
Sep 14, 2024


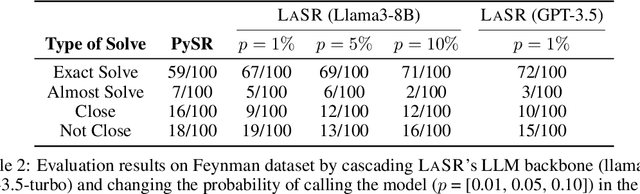
We present a novel method for symbolic regression (SR), the task of searching for compact programmatic hypotheses that best explain a dataset. The problem is commonly solved using genetic algorithms; we show that we can enhance such methods by inducing a library of abstract textual concepts. Our algorithm, called LaSR, uses zero-shot queries to a large language model (LLM) to discover and evolve concepts occurring in known high-performing hypotheses. We discover new hypotheses using a mix of standard evolutionary steps and LLM-guided steps (obtained through zero-shot LLM queries) conditioned on discovered concepts. Once discovered, hypotheses are used in a new round of concept abstraction and evolution. We validate LaSR on the Feynman equations, a popular SR benchmark, as well as a set of synthetic tasks. On these benchmarks, LaSR substantially outperforms a variety of state-of-the-art SR approaches based on deep learning and evolutionary algorithms. Moreover, we show that LaSR can be used to discover a novel and powerful scaling law for LLMs.
Machine Learning with Physics Knowledge for Prediction: A Survey
Aug 19, 2024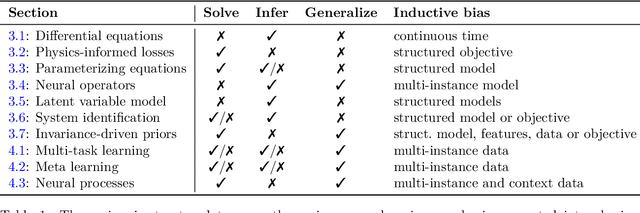
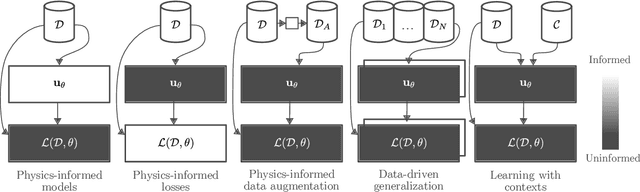
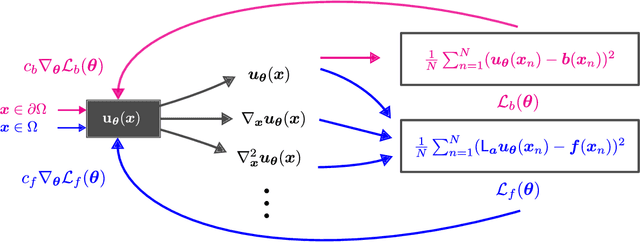
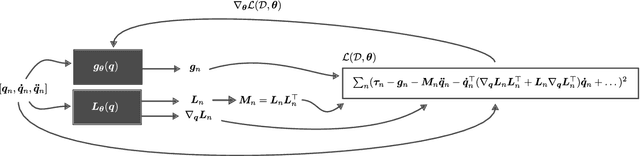
This survey examines the broad suite of methods and models for combining machine learning with physics knowledge for prediction and forecast, with a focus on partial differential equations. These methods have attracted significant interest due to their potential impact on advancing scientific research and industrial practices by improving predictive models with small- or large-scale datasets and expressive predictive models with useful inductive biases. The survey has two parts. The first considers incorporating physics knowledge on an architectural level through objective functions, structured predictive models, and data augmentation. The second considers data as physics knowledge, which motivates looking at multi-task, meta, and contextual learning as an alternative approach to incorporating physics knowledge in a data-driven fashion. Finally, we also provide an industrial perspective on the application of these methods and a survey of the open-source ecosystem for physics-informed machine learning.
Accelerating Giant Impact Simulations with Machine Learning
Aug 16, 2024



Constraining planet formation models based on the observed exoplanet population requires generating large samples of synthetic planetary systems, which can be computationally prohibitive. A significant bottleneck is simulating the giant impact phase, during which planetary embryos evolve gravitationally and combine to form planets, which may themselves experience later collisions. To accelerate giant impact simulations, we present a machine learning (ML) approach to predicting collisional outcomes in multiplanet systems. Trained on more than 500,000 $N$-body simulations of three-planet systems, we develop an ML model that can accurately predict which two planets will experience a collision, along with the state of the post-collision planets, from a short integration of the system's initial conditions. Our model greatly improves on non-ML baselines that rely on metrics from dynamics theory, which struggle to accurately predict which pair of planets will experience a collision. By combining with a model for predicting long-term stability, we create an efficient ML-based giant impact emulator, which can predict the outcomes of giant impact simulations with a speedup of up to four orders of magnitude. We expect our model to enable analyses that would not otherwise be computationally feasible. As such, we release our full training code, along with an easy-to-use API for our collision outcome model and giant impact emulator.