 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Capacity Scaling of Spectral Optimizers in Learning Associative Memory
Mar 27, 2026Spectral optimizers such as Muon have recently shown strong empirical performance in large-scale language model training, but the source and extent of their advantage remain poorly understood. We study this question through the linear associative memory problem, a tractable model for factual recall in transformer-based models. In particular, we go beyond orthogonal embeddings and consider Gaussian inputs and outputs, which allows the number of stored associations to greatly exceed the embedding dimension. Our main result sharply characterizes the recovery rates of one step of Muon and SGD on the logistic regression loss under a power law frequency distribution. We show that the storage capacity of Muon significantly exceeds that of SGD, and moreover Muon saturates at a larger critical batch size. We further analyze the multi-step dynamics under a thresholded gradient approximation and show that Muon achieves a substantially faster initial recovery rate than SGD, while both methods eventually converge to the information-theoretic limit at comparable speeds. Experiments on synthetic tasks validate the predicted scaling laws. Our analysis provides a quantitative understanding of the signal amplification of Muon and lays the groundwork for establishing scaling laws across more practical language modeling tasks and optimizers.
Understanding Contextual Recall in Transformers: How Finetuning Enables In-Context Reasoning over Pretraining Knowledge
Mar 21, 2026Transformer-based language models excel at in-context learning (ICL), where they can adapt to new tasks based on contextual examples, without parameter updates. In a specific form of ICL, which we refer to as \textit{contextual recall}, models pretrained on open-ended text leverage pairwise examples to recall specific facts in novel prompt formats. We investigate whether contextual recall emerges from pretraining alone, what finetuning is required, and what mechanisms drive the necessary representations. For this, we introduce a controlled synthetic framework where pretraining sequences consist of subject-grammar-attribute tuples, with attribute types tied to grammar statistics. We demonstrate that while such pretraining successfully yields factual knowledge, it is insufficient for contextual recall: models fail to implicitly infer attribute types when the grammar statistics are removed in ICL prompts. However, we show that finetuning on tasks requiring implicit inference, distinct from the ICL evaluation, using a subset of subjects, triggers the emergence of contextual recall across all subjects. This transition is accompanied by the formation of low-dimensional latent encodings of the shared attribute type. For mechanistic insight, we derive a construction for an attention-only transformer that replicates the transition from factual to contextual recall, corroborated by empirical validation.
Protein Design with Agent Rosetta: A Case Study for Specialized Scientific Agents
Mar 16, 2026Large language models (LLMs) are capable of emulating reasoning and using tools, creating opportunities for autonomous agents that execute complex scientific tasks. Protein design provides a natural testbed: although machine learning (ML) methods achieve strong results, these are largely restricted to canonical amino acids and narrow objectives, leaving unfilled need for a generalist tool for broad design pipelines. We introduce Agent Rosetta, an LLM agent paired with a structured environment for operating Rosetta, the leading physics-based heteropolymer design software, capable of modeling non-canonical building blocks and geometries. Agent Rosetta iteratively refines designs to achieve user-defined objectives, combining LLM reasoning with Rosetta's generality. We evaluate Agent Rosetta on design with canonical amino acids, matching specialized models and expert baselines, and with non-canonical residues -- where ML approaches fail -- achieving comparable performance. Critically, prompt engineering alone often fails to generate Rosetta actions, demonstrating that environment design is essential for integrating LLM agents with specialized software. Our results show that properly designed environments enable LLM agents to make scientific software accessible while matching specialized tools and human experts.
Learning to Recall with Transformers Beyond Orthogonal Embeddings
Mar 16, 2026Modern large language models (LLMs) excel at tasks that require storing and retrieving knowledge, such as factual recall and question answering. Transformers are central to this capability because they can encode information during training and retrieve it at inference. Existing theoretical analyses typically study transformers under idealized assumptions such as infinite data or orthogonal embeddings. In realistic settings, however, models are trained on finite datasets with non-orthogonal (random) embeddings. We address this gap by analyzing a single-layer transformer with random embeddings trained with (empirical) gradient descent on a simple token-retrieval task, where the model must identify an informative token within a length-$L$ sequence and learn a one-to-one mapping from tokens to labels. Our analysis tracks the ``early phase'' of gradient descent and yields explicit formulas for the model's storage capacity -- revealing a multiplicative dependence between sample size $N$, embedding dimension $d$, and sequence length $L$. We validate these scalings numerically and further complement them with a lower bound for the underlying statistical problem, demonstrating that this multiplicative scaling is intrinsic under non-orthogonal embeddings.
Representation Learning for Spatiotemporal Physical Systems
Mar 13, 2026Machine learning approaches to spatiotemporal physical systems have primarily focused on next-frame prediction, with the goal of learning an accurate emulator for the system's evolution in time. However, these emulators are computationally expensive to train and are subject to performance pitfalls, such as compounding errors during autoregressive rollout. In this work, we take a different perspective and look at scientific tasks further downstream of predicting the next frame, such as estimation of a system's governing physical parameters. Accuracy on these tasks offers a uniquely quantifiable glimpse into the physical relevance of the representations of these models. We evaluate the effectiveness of general-purpose self-supervised methods in learning physics-grounded representations that are useful for downstream scientific tasks. Surprisingly, we find that not all methods designed for physical modeling outperform generic self-supervised learning methods on these tasks, and methods that learn in the latent space (e.g., joint embedding predictive architectures, or JEPAs) outperform those optimizing pixel-level prediction objectives. Code is available at https://github.com/helenqu/physical-representation-learning.
Understanding the Mechanisms of Fast Hyperparameter Transfer
Dec 28, 2025The growing scale of deep learning models has rendered standard hyperparameter (HP) optimization prohibitively expensive. A promising solution is the use of scale-aware hyperparameters, which can enable direct transfer of optimal HPs from small-scale grid searches to large models with minimal performance loss. To understand the principles governing such transfer strategy, we develop a general conceptual framework for reasoning about HP transfer across scale, characterizing transfer as fast when the suboptimality it induces vanishes asymptotically faster than the finite-scale performance gap. We show formally that fast transfer is equivalent to useful transfer for compute-optimal grid search, meaning that transfer is asymptotically more compute-efficient than direct tuning. While empirical work has found that the Maximal Update Parameterization ($μ$P) exhibits fast transfer when scaling model width, the mechanisms remain poorly understood. We show that this property depends critically on problem structure by presenting synthetic settings where transfer either offers provable computational advantage or fails to outperform direct tuning even under $μ$P. To explain the fast transfer observed in practice, we conjecture that decomposing the optimization trajectory reveals two contributions to loss reduction: (1) a width-stable component that determines the optimal HPs, and (2) a width-sensitive component that improves with width but weakly perturbs the HP optimum. We present empirical evidence for this hypothesis across various settings, including large language model pretraining.
From Shortcut to Induction Head: How Data Diversity Shapes Algorithm Selection in Transformers
Dec 21, 2025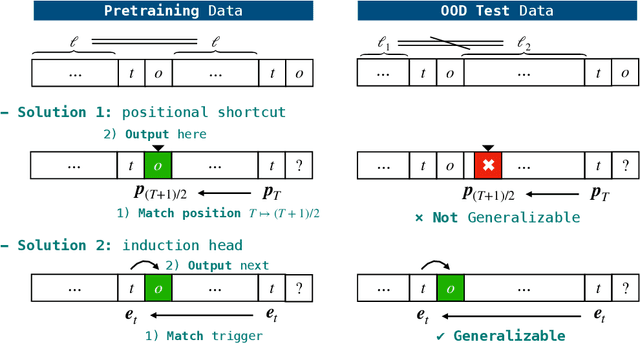
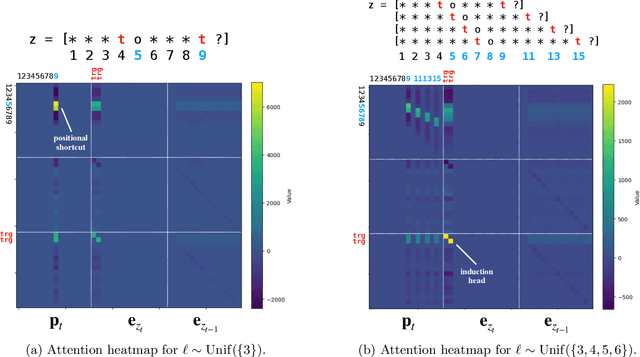
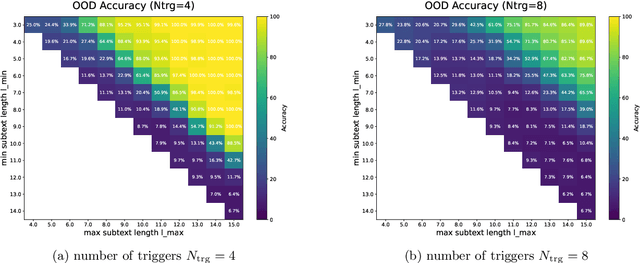
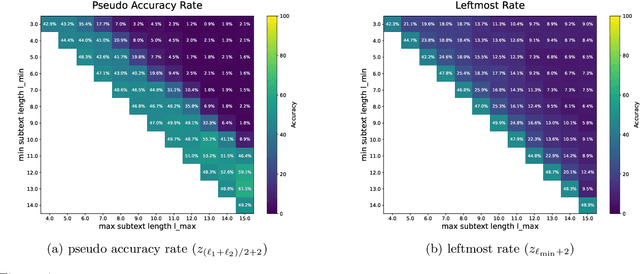
Transformers can implement both generalizable algorithms (e.g., induction heads) and simple positional shortcuts (e.g., memorizing fixed output positions). In this work, we study how the choice of pretraining data distribution steers a shallow transformer toward one behavior or the other. Focusing on a minimal trigger-output prediction task -- copying the token immediately following a special trigger upon its second occurrence -- we present a rigorous analysis of gradient-based training of a single-layer transformer. In both the infinite and finite sample regimes, we prove a transition in the learned mechanism: if input sequences exhibit sufficient diversity, measured by a low ``max-sum'' ratio of trigger-to-trigger distances, the trained model implements an induction head and generalizes to unseen contexts; by contrast, when this ratio is large, the model resorts to a positional shortcut and fails to generalize out-of-distribution (OOD). We also reveal a trade-off between the pretraining context length and OOD generalization, and derive the optimal pretraining distribution that minimizes computational cost per sample. Finally, we validate our theoretical predictions with controlled synthetic experiments, demonstrating that broadening context distributions robustly induces induction heads and enables OOD generalization. Our results shed light on the algorithmic biases of pretrained transformers and offer conceptual guidelines for data-driven control of their learned behaviors.
Walrus: A Cross-Domain Foundation Model for Continuum Dynamics
Nov 19, 2025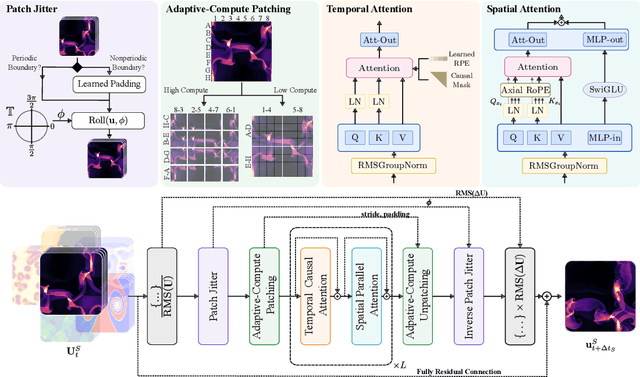


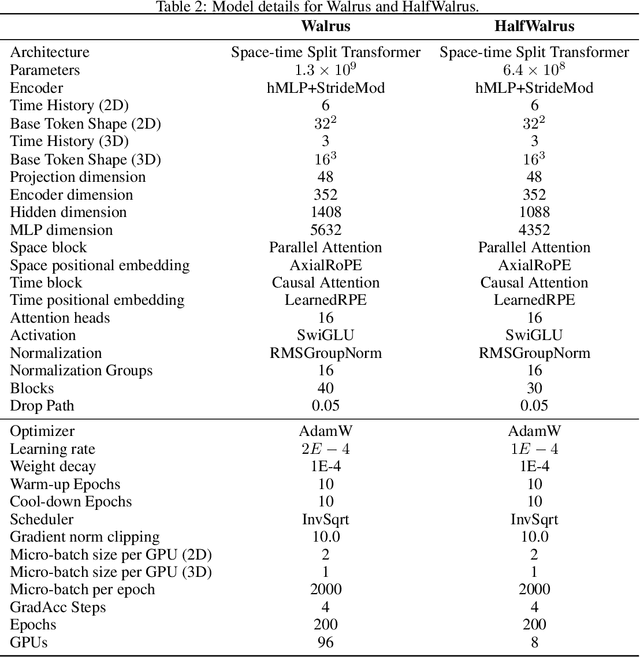
Foundation models have transformed machine learning for language and vision, but achieving comparable impact in physical simulation remains a challenge. Data heterogeneity and unstable long-term dynamics inhibit learning from sufficiently diverse dynamics, while varying resolutions and dimensionalities challenge efficient training on modern hardware. Through empirical and theoretical analysis, we incorporate new approaches to mitigate these obstacles, including a harmonic-analysis-based stabilization method, load-balanced distributed 2D and 3D training strategies, and compute-adaptive tokenization. Using these tools, we develop Walrus, a transformer-based foundation model developed primarily for fluid-like continuum dynamics. Walrus is pretrained on nineteen diverse scenarios spanning astrophysics, geoscience, rheology, plasma physics, acoustics, and classical fluids. Experiments show that Walrus outperforms prior foundation models on both short and long term prediction horizons on downstream tasks and across the breadth of pretraining data, while ablation studies confirm the value of our contributions to forecast stability, training throughput, and transfer performance over conventional approaches. Code and weights are released for community use.
GSM-Agent: Understanding Agentic Reasoning Using Controllable Environments
Sep 26, 2025



As LLMs are increasingly deployed as agents, agentic reasoning - the ability to combine tool use, especially search, and reasoning - becomes a critical skill. However, it is hard to disentangle agentic reasoning when evaluated in complex environments and tasks. Current agent benchmarks often mix agentic reasoning with challenging math reasoning, expert-level knowledge, and other advanced capabilities. To fill this gap, we build a novel benchmark, GSM-Agent, where an LLM agent is required to solve grade-school-level reasoning problems, but is only presented with the question in the prompt without the premises that contain the necessary information to solve the task, and needs to proactively collect that information using tools. Although the original tasks are grade-school math problems, we observe that even frontier models like GPT-5 only achieve 67% accuracy. To understand and analyze the agentic reasoning patterns, we propose the concept of agentic reasoning graph: cluster the environment's document embeddings into nodes, and map each tool call to its nearest node to build a reasoning path. Surprisingly, we identify that the ability to revisit a previously visited node, widely taken as a crucial pattern in static reasoning, is often missing for agentic reasoning for many models. Based on the insight, we propose a tool-augmented test-time scaling method to improve LLM's agentic reasoning performance by adding tools to encourage models to revisit. We expect our benchmark and the agentic reasoning framework to aid future studies of understanding and pushing the boundaries of agentic reasoning.
Learning Compositional Functions with Transformers from Easy-to-Hard Data
May 29, 2025Transformer-based language models have demonstrated impressive capabilities across a range of complex reasoning tasks. Prior theoretical work exploring the expressive power of transformers has shown that they can efficiently perform multi-step reasoning tasks involving parallelizable computations. However, the learnability of such constructions, particularly the conditions on the data distribution that enable efficient learning via gradient-based optimization, remains an open question. Towards answering this question, in this work we study the learnability of the $k$-fold composition task, which requires computing an interleaved composition of $k$ input permutations and $k$ hidden permutations, and can be expressed by a transformer with $O(\log k)$ layers. On the negative front, we prove a Statistical Query (SQ) lower bound showing that any SQ learner that makes only polynomially-many queries to an SQ oracle for the $k$-fold composition task distribution must have sample size exponential in $k$, thus establishing a statistical-computational gap. On the other hand, we show that this function class can be efficiently learned, with runtime and sample complexity polynomial in $k$, by gradient descent on an $O(\log k)$-depth transformer via two different curriculum learning strategies: one in which data consists of $k'$-fold composition functions with $k' \le k$ presented in increasing difficulty, and another in which all such data is presented simultaneously. Our work sheds light on the necessity and sufficiency of having both easy and hard examples in the data distribution for transformers to learn complex compositional tasks.