 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Neural Scaling Laws
Jan 27, 2026Neural scaling laws predict how language model performance improves with increased compute. While aggregate metrics like validation loss can follow smooth power-law curves, individual downstream tasks exhibit diverse scaling behaviors: some improve monotonically, others plateau, and some even degrade with scale. We argue that predicting downstream performance from validation perplexity suffers from two limitations: averaging token-level losses obscures signal, and no simple parametric family can capture the full spectrum of scaling behaviors. To address this, we propose Neural Neural Scaling Laws (NeuNeu), a neural network that frames scaling law prediction as time-series extrapolation. NeuNeu combines temporal context from observed accuracy trajectories with token-level validation losses, learning to predict future performance without assuming any bottleneck or functional form. Trained entirely on open-source model checkpoints from HuggingFace, NeuNeu achieves 2.04% mean absolute error in predicting model accuracy on 66 downstream tasks -- a 38% reduction compared to logistic scaling laws (3.29% MAE). Furthermore, NeuNeu generalizes zero-shot to unseen model families, parameter counts, and downstream tasks. Our work suggests that predicting downstream scaling laws directly from data outperforms parametric alternatives.
Scaling Laws Are Unreliable for Downstream Tasks: A Reality Check
Jul 01, 2025Downstream scaling laws aim to predict task performance at larger scales from pretraining losses at smaller scales. Whether this prediction should be possible is unclear: some works demonstrate that task performance follows clear linear scaling trends under transformation, whereas others point out fundamental challenges to downstream scaling laws, such as emergence and inverse scaling. In this work, we conduct a meta-analysis of existing data on downstream scaling laws, finding that close fit to linear scaling laws only occurs in a minority of cases: 39% of the time. Furthermore, seemingly benign changes to the experimental setting can completely change the scaling trend. Our analysis underscores the need to understand the conditions under which scaling laws succeed. To fully model the relationship between pretraining loss and downstream task performance, we must embrace the cases in which scaling behavior deviates from linear trends.
What's In Your Field? Mapping Scientific Research with Knowledge Graphs and Large Language Models
Mar 12, 2025


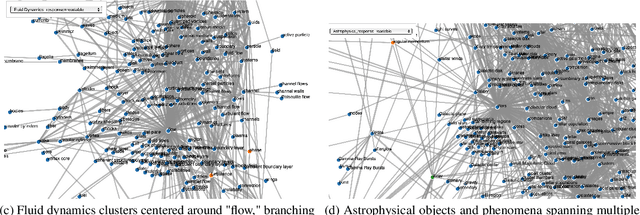
The scientific literature's exponential growth makes it increasingly challenging to navigate and synthesize knowledge across disciplines. Large language models (LLMs) are powerful tools for understanding scientific text, but they fail to capture detailed relationships across large bodies of work. Unstructured approaches, like retrieval augmented generation, can sift through such corpora to recall relevant facts; however, when millions of facts influence the answer, unstructured approaches become cost prohibitive. Structured representations offer a natural complement -- enabling systematic analysis across the whole corpus. Recent work enhances LLMs with unstructured or semistructured representations of scientific concepts; to complement this, we try extracting structured representations using LLMs. By combining LLMs' semantic understanding with a schema of scientific concepts, we prototype a system that answers precise questions about the literature as a whole. Our schema applies across scientific fields and we extract concepts from it using only 20 manually annotated abstracts. To demonstrate the system, we extract concepts from 30,000 papers on arXiv spanning astrophysics, fluid dynamics, and evolutionary biology. The resulting database highlights emerging trends and, by visualizing the knowledge graph, offers new ways to explore the ever-growing landscape of scientific knowledge. Demo: abby101/surveyor-0 on HF Spaces. Code: https://github.com/chiral-carbon/kg-for-science.
Aioli: A Unified Optimization Framework for Language Model Data Mixing
Nov 08, 2024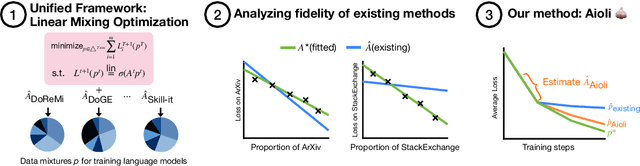



Language model performance depends on identifying the optimal mixture of data groups to train on (e.g., law, code, math). Prior work has proposed a diverse set of methods to efficiently learn mixture proportions, ranging from fitting regression models over training runs to dynamically updating proportions throughout training. Surprisingly, we find that no existing method consistently outperforms a simple stratified sampling baseline in terms of average test perplexity per group. In this paper, we study the cause of this inconsistency by unifying existing methods into a standard optimization framework. We show that all methods set proportions to minimize total loss, subject to a method-specific mixing law -- an assumption on how loss is a function of mixture proportions. We find that existing parameterizations of mixing laws can express the true loss-proportion relationship empirically, but the methods themselves often set the mixing law parameters inaccurately, resulting in poor and inconsistent performance. Finally, we leverage the insights from our framework to derive a new online method named Aioli, which directly estimates the mixing law parameters throughout training and uses them to dynamically adjust proportions. Empirically, Aioli outperforms stratified sampling on 6 out of 6 datasets by an average of 0.28 test perplexity points, whereas existing methods fail to consistently beat stratified sampling, doing up to 6.9 points worse. Moreover, in a practical setting where proportions are learned on shorter runs due to computational constraints, Aioli can dynamically adjust these proportions over the full training run, consistently improving performance over existing methods by up to 12.01 test perplexity points.
Contextual Counting: A Mechanistic Study of Transformers on a Quantitative Task
May 30, 2024Transformers have revolutionized machine learning across diverse domains, yet understanding their behavior remains crucial, particularly in high-stakes applications. This paper introduces the contextual counting task, a novel toy problem aimed at enhancing our understanding of Transformers in quantitative and scientific contexts. This task requires precise localization and computation within datasets, akin to object detection or region-based scientific analysis. We present theoretical and empirical analysis using both causal and non-causal Transformer architectures, investigating the influence of various positional encodings on performance and interpretability. In particular, we find that causal attention is much better suited for the task, and that no positional embeddings lead to the best accuracy, though rotary embeddings are competitive and easier to train. We also show that out of distribution performance is tightly linked to which tokens it uses as a bias term.
Show Your Work with Confidence: Confidence Bands for Tuning Curves
Nov 16, 2023



The choice of hyperparameters greatly impacts performance in natural language processing. Often, it is hard to tell if a method is better than another or just better tuned. Tuning curves fix this ambiguity by accounting for tuning effort. Specifically, they plot validation performance as a function of the number of hyperparameter choices tried so far. While several estimators exist for these curves, it is common to use point estimates, which we show fail silently and give contradictory results when given too little data. Beyond point estimates, confidence bands are necessary to rigorously establish the relationship between different approaches. We present the first method to construct valid confidence bands for tuning curves. The bands are exact, simultaneous, and distribution-free, thus they provide a robust basis for comparing methods. Empirical analysis shows that while bootstrap confidence bands, which serve as a baseline, fail to approximate their target confidence, ours achieve it exactly. We validate our design with ablations, analyze the effect of sample size, and provide guidance on comparing models with our method. To promote confident comparisons in future work, we release a library implementing the method at https://github.com/nalourie/opda .
UNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark
Mar 24, 2021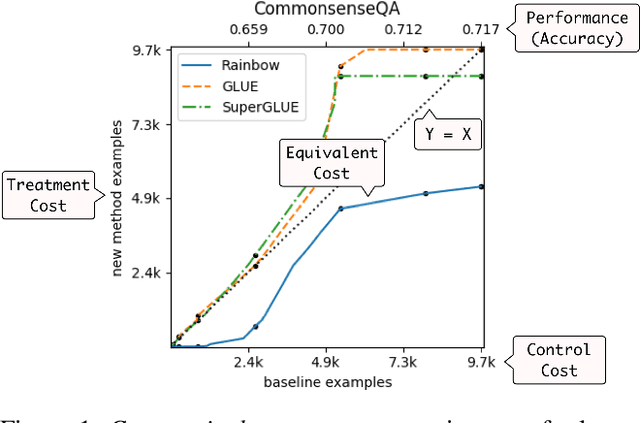

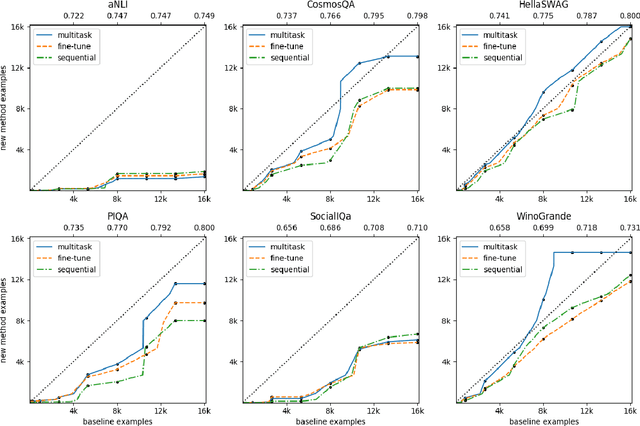

Commonsense AI has long been seen as a near impossible goal -- until recently. Now, research interest has sharply increased with an influx of new benchmarks and models. We propose two new ways to evaluate commonsense models, emphasizing their generality on new tasks and building on diverse, recently introduced benchmarks. First, we propose a new multitask benchmark, RAINBOW, to promote research on commonsense models that generalize well over multiple tasks and datasets. Second, we propose a novel evaluation, the cost equivalent curve, that sheds new insight on how the choice of source datasets, pretrained language models, and transfer learning methods impacts performance and data efficiency. We perform extensive experiments -- over 200 experiments encompassing 4800 models -- and report multiple valuable and sometimes surprising findings, e.g., that transfer almost always leads to better or equivalent performance if following a particular recipe, that QA-based commonsense datasets transfer well with each other, while commonsense knowledge graphs do not, and that perhaps counter-intuitively, larger models benefit more from transfer than smaller ones. Last but not least, we introduce a new universal commonsense reasoning model, UNICORN, that establishes new state-of-the-art performance across 8 popular commonsense benchmarks, aNLI (87.3%), CosmosQA (91.8%), HellaSWAG (93.9%), PIQA (90.1%), SocialIQa (83.2%), WinoGrande (86.6%), CycIC (94.0%) and CommonsenseQA (79.3%).
GENIE: A Leaderboard for Human-in-the-Loop Evaluation of Text Generation
Jan 17, 2021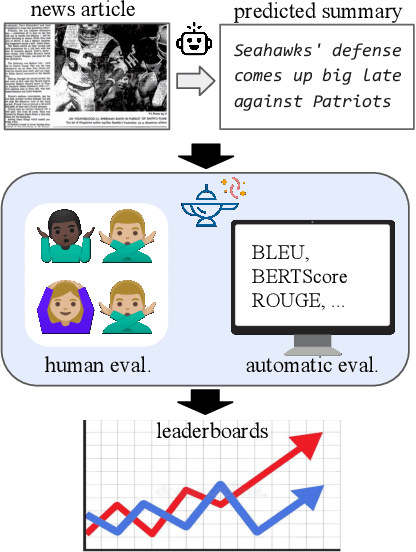

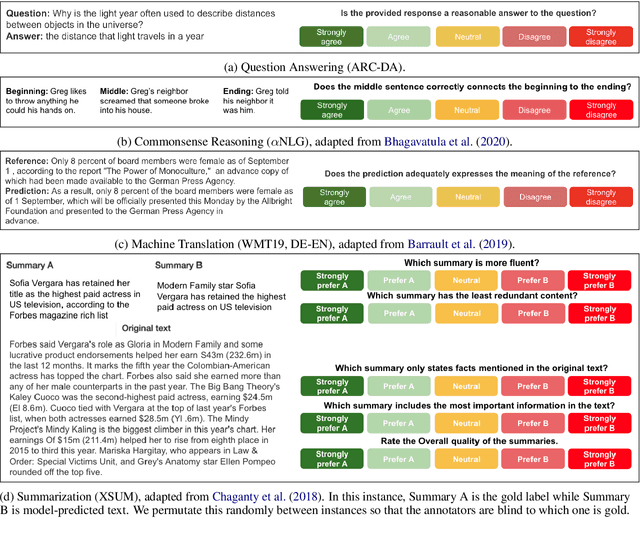
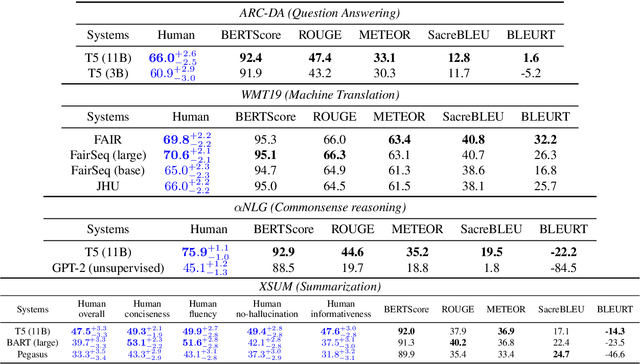
Leaderboards have eased model development for many NLP datasets by standardizing their evaluation and delegating it to an independent external repository. Their adoption, however, is so far limited to tasks that can be reliably evaluated in an automatic manner. This work introduces GENIE, an extensible human evaluation leaderboard, which brings the ease of leaderboards to text generation tasks. GENIE automatically posts leaderboard submissions to crowdsourcing platforms asking human annotators to evaluate them on various axes (e.g., correctness, conciseness, fluency) and compares their answers to various automatic metrics. We introduce several datasets in English to GENIE, representing four core challenges in text generation: machine translation, summarization, commonsense reasoning, and machine comprehension. We provide formal granular evaluation metrics and identify areas for future research. We make GENIE publicly available and hope that it will spur progress in language generation models as well as their automatic and manual evaluation.
Learning from Task Descriptions
Nov 16, 2020


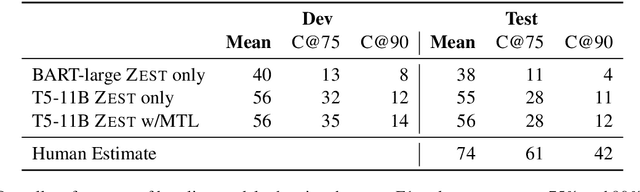
Typically, machine learning systems solve new tasks by training on thousands of examples. In contrast, humans can solve new tasks by reading some instructions, with perhaps an example or two. To take a step toward closing this gap, we introduce a framework for developing NLP systems that solve new tasks after reading their descriptions, synthesizing prior work in this area. We instantiate this framework with a new English language dataset, ZEST, structured for task-oriented evaluation on unseen tasks. Formulating task descriptions as questions, we ensure each is general enough to apply to many possible inputs, thus comprehensively evaluating a model's ability to solve each task. Moreover, the dataset's structure tests specific types of systematic generalization. We find that the state-of-the-art T5 model achieves a score of 12% on ZEST, leaving a significant challenge for NLP researchers.
Dataset Cartography: Mapping and Diagnosing Datasets with Training Dynamics
Oct 15, 2020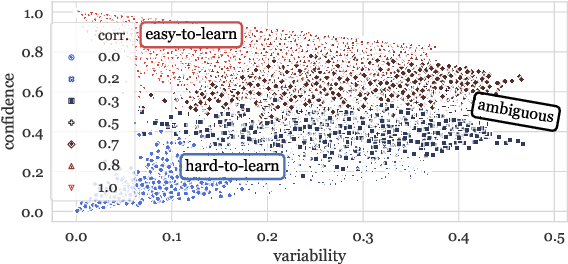
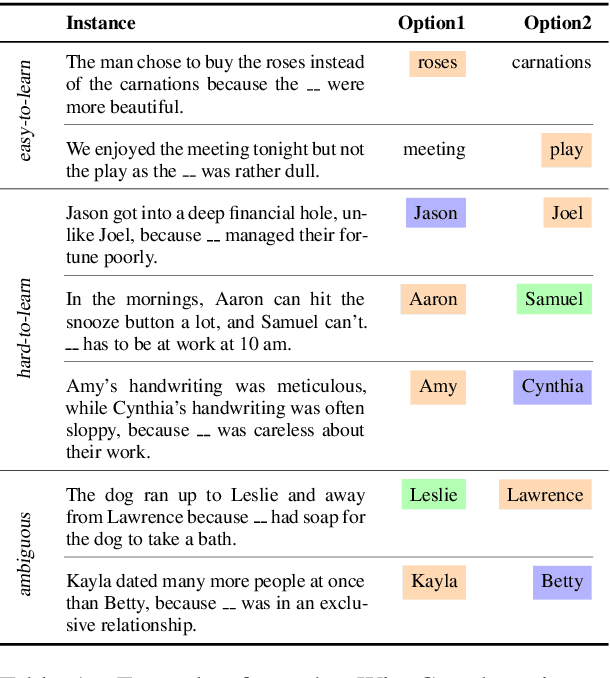
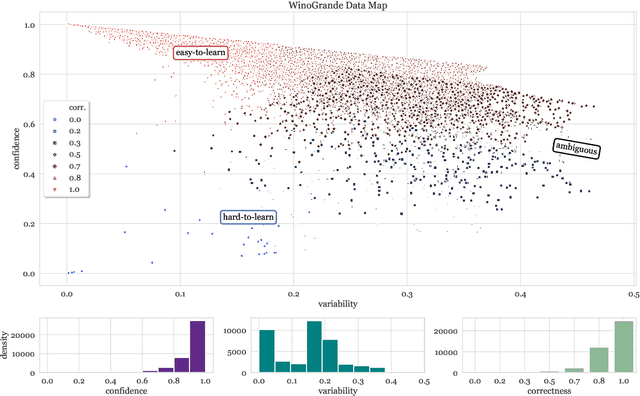

Large datasets have become commonplace in NLP research. However, the increased emphasis on data quantity has made it challenging to assess the quality of data. We introduce Data Maps---a model-based tool to characterize and diagnose datasets. We leverage a largely ignored source of information: the behavior of the model on individual instances during training (training dynamics) for building data maps. This yields two intuitive measures for each example---the model's confidence in the true class, and the variability of this confidence across epochs---obtained in a single run of training. Experiments across four datasets show that these model-dependent measures reveal three distinct regions in the data map, each with pronounced characteristics. First, our data maps show the presence of "ambiguous" regions with respect to the model, which contribute the most towards out-of-distribution generalization. Second, the most populous regions in the data are "easy to learn" for the model, and play an important role in model optimization. Finally, data maps uncover a region with instances that the model finds "hard to learn"; these often correspond to labeling errors. Our results indicate that a shift in focus from quantity to quality of data could lead to robust models and improved out-of-distribution generalization.