 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUNICORN on RAINBOW: A Universal Commonsense Reasoning Model on a New Multitask Benchmark
Paper and Code
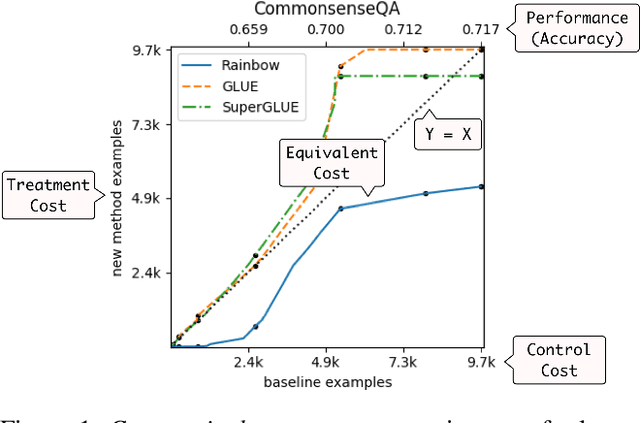

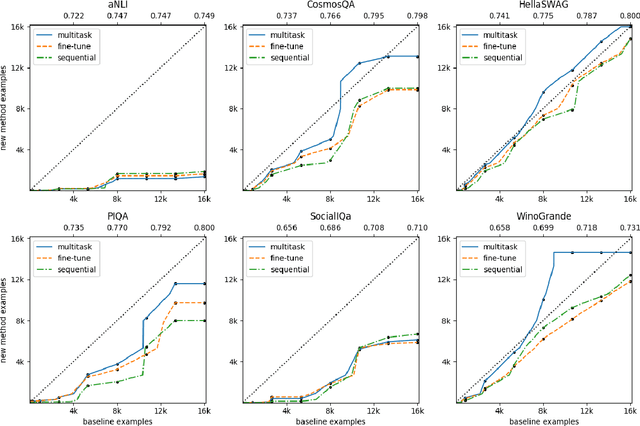

Commonsense AI has long been seen as a near impossible goal -- until recently. Now, research interest has sharply increased with an influx of new benchmarks and models. We propose two new ways to evaluate commonsense models, emphasizing their generality on new tasks and building on diverse, recently introduced benchmarks. First, we propose a new multitask benchmark, RAINBOW, to promote research on commonsense models that generalize well over multiple tasks and datasets. Second, we propose a novel evaluation, the cost equivalent curve, that sheds new insight on how the choice of source datasets, pretrained language models, and transfer learning methods impacts performance and data efficiency. We perform extensive experiments -- over 200 experiments encompassing 4800 models -- and report multiple valuable and sometimes surprising findings, e.g., that transfer almost always leads to better or equivalent performance if following a particular recipe, that QA-based commonsense datasets transfer well with each other, while commonsense knowledge graphs do not, and that perhaps counter-intuitively, larger models benefit more from transfer than smaller ones. Last but not least, we introduce a new universal commonsense reasoning model, UNICORN, that establishes new state-of-the-art performance across 8 popular commonsense benchmarks, aNLI (87.3%), CosmosQA (91.8%), HellaSWAG (93.9%), PIQA (90.1%), SocialIQa (83.2%), WinoGrande (86.6%), CycIC (94.0%) and CommonsenseQA (79.3%).