 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
Mar 15, 2025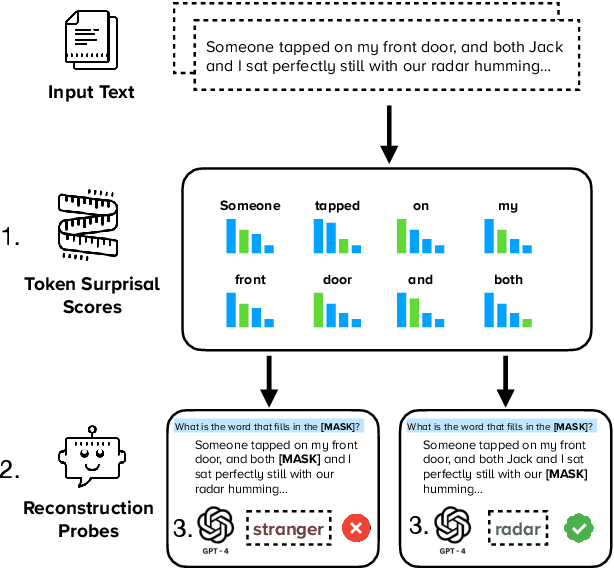

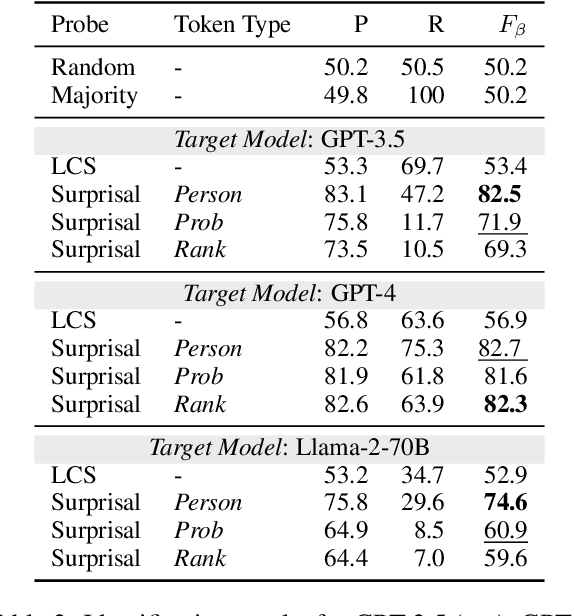
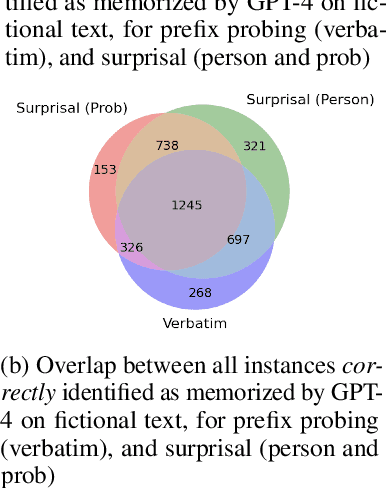
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. This lack of transparency creates multiple challenges: it limits external oversight and inspection of LLMs for issues such as copyright infringement, it undermines the agency of data authors, and it hinders scientific research on critical issues such as data contamination and data selection. How can we recover what training data is known to LLMs? In this work, we demonstrate a new method to identify training data known to proprietary LLMs like GPT-4 without requiring any access to model weights or token probabilities, by using information-guided probes. Our work builds on a key observation: text passages with high surprisal are good search material for memorization probes. By evaluating a model's ability to successfully reconstruct high-surprisal tokens in text, we can identify a surprising number of texts memorized by LLMs.
NovaCOMET: Open Commonsense Foundation Models with Symbolic Knowledge Distillation
Dec 10, 2023


We present NovaCOMET, an open commonsense knowledge model, that combines the best aspects of knowledge and general task models. Compared to previous knowledge models, NovaCOMET allows open-format relations enabling direct application to reasoning tasks; compared to general task models like Flan-T5, it explicitly centers knowledge, enabling superior performance for commonsense reasoning. NovaCOMET leverages the knowledge of opaque proprietary models to create an open knowledge pipeline. First, knowledge is symbolically distilled into NovATOMIC, a publicly-released discrete knowledge graph which can be audited, critiqued, and filtered. Next, we train NovaCOMET on NovATOMIC by fine-tuning an open-source pretrained model. NovaCOMET uses an open-format training objective, replacing the fixed relation sets of past knowledge models, enabling arbitrary structures within the data to serve as inputs or outputs. The resulting generation model, optionally augmented with human annotation, matches or exceeds comparable open task models like Flan-T5 on a range of commonsense generation tasks. NovaCOMET serves as a counterexample to the contemporary focus on instruction tuning only, demonstrating a distinct advantage to explicitly modeling commonsense knowledge as well.
The Unlocking Spell on Base LLMs: Rethinking Alignment via In-Context Learning
Dec 04, 2023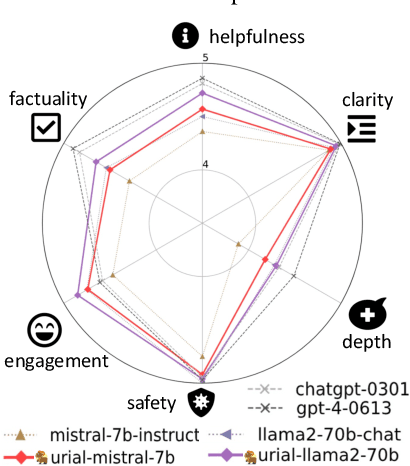
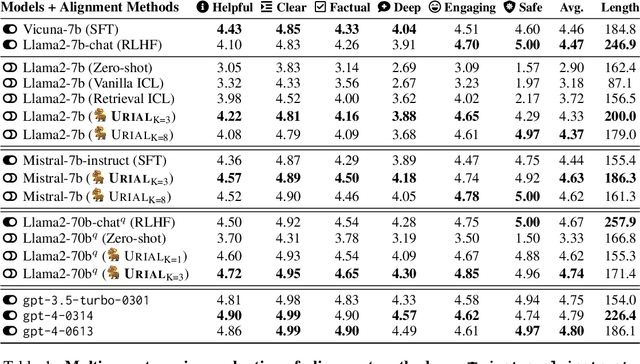
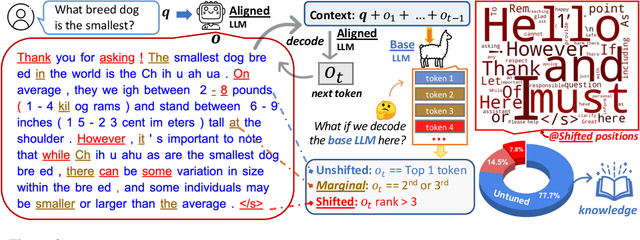

The alignment tuning process of large language models (LLMs) typically involves instruction learning through supervised fine-tuning (SFT) and preference tuning via reinforcement learning from human feedback (RLHF). A recent study, LIMA (Zhou et al. 2023), shows that using merely 1K examples for SFT can achieve significant alignment performance as well, suggesting that the effect of alignment tuning might be "superficial." This raises questions about how exactly the alignment tuning transforms a base LLM. We analyze the effect of alignment tuning by examining the token distribution shift between base LLMs and their aligned counterpart. Our findings reveal that base LLMs and their alignment-tuned versions perform nearly identically in decoding on the majority of token positions. Most distribution shifts occur with stylistic tokens. These direct evidence strongly supports the Superficial Alignment Hypothesis suggested by LIMA. Based on these findings, we rethink the alignment of LLMs by posing the research question: how effectively can we align base LLMs without SFT or RLHF? To address this, we introduce a simple, tuning-free alignment method, URIAL. URIAL achieves effective alignment purely through in-context learning (ICL) with base LLMs, requiring as few as three constant stylistic examples and a system prompt. We conduct a fine-grained and interpretable evaluation on a diverse set of examples, named JUST-EVAL-INSTRUCT. Results demonstrate that base LLMs with URIAL can match or even surpass the performance of LLMs aligned with SFT or SFT+RLHF. We show that the gap between tuning-free and tuning-based alignment methods can be significantly reduced through strategic prompting and ICL. Our findings on the superficial nature of alignment tuning and results with URIAL suggest that deeper analysis and theoretical understanding of alignment is crucial to future LLM research.
"You Are An Expert Linguistic Annotator": Limits of LLMs as Analyzers of Abstract Meaning Representation
Oct 26, 2023



Large language models (LLMs) show amazing proficiency and fluency in the use of language. Does this mean that they have also acquired insightful linguistic knowledge about the language, to an extent that they can serve as an "expert linguistic annotator"? In this paper, we examine the successes and limitations of the GPT-3, ChatGPT, and GPT-4 models in analysis of sentence meaning structure, focusing on the Abstract Meaning Representation (AMR; Banarescu et al. 2013) parsing formalism, which provides rich graphical representations of sentence meaning structure while abstracting away from surface forms. We compare models' analysis of this semantic structure across two settings: 1) direct production of AMR parses based on zero- and few-shot prompts, and 2) indirect partial reconstruction of AMR via metalinguistic natural language queries (e.g., "Identify the primary event of this sentence, and the predicate corresponding to that event."). Across these settings, we find that models can reliably reproduce the basic format of AMR, and can often capture core event, argument, and modifier structure -- however, model outputs are prone to frequent and major errors, and holistic analysis of parse acceptability shows that even with few-shot demonstrations, models have virtually 0% success in producing fully accurate parses. Eliciting natural language responses produces similar patterns of errors. Overall, our findings indicate that these models out-of-the-box can capture aspects of semantic structure, but there remain key limitations in their ability to support fully accurate semantic analyses or parses.
Phenomenal Yet Puzzling: Testing Inductive Reasoning Capabilities of Language Models with Hypothesis Refinement
Oct 12, 2023The ability to derive underlying principles from a handful of observations and then generalize to novel situations -- known as inductive reasoning -- is central to human intelligence. Prior work suggests that language models (LMs) often fall short on inductive reasoning, despite achieving impressive success on research benchmarks. In this work, we conduct a systematic study of the inductive reasoning capabilities of LMs through iterative hypothesis refinement, a technique that more closely mirrors the human inductive process than standard input-output prompting. Iterative hypothesis refinement employs a three-step process: proposing, selecting, and refining hypotheses in the form of textual rules. By examining the intermediate rules, we observe that LMs are phenomenal hypothesis proposers (i.e., generating candidate rules), and when coupled with a (task-specific) symbolic interpreter that is able to systematically filter the proposed set of rules, this hybrid approach achieves strong results across inductive reasoning benchmarks that require inducing causal relations, language-like instructions, and symbolic concepts. However, they also behave as puzzling inductive reasoners, showing notable performance gaps in rule induction (i.e., identifying plausible rules) and rule application (i.e., applying proposed rules to instances), suggesting that LMs are proposing hypotheses without being able to actually apply the rules. Through empirical and human analyses, we further reveal several discrepancies between the inductive reasoning processes of LMs and humans, shedding light on both the potentials and limitations of using LMs in inductive reasoning tasks.
Value Kaleidoscope: Engaging AI with Pluralistic Human Values, Rights, and Duties
Sep 02, 2023Human values are crucial to human decision-making. Value pluralism is the view that multiple correct values may be held in tension with one another (e.g., when considering lying to a friend to protect their feelings, how does one balance honesty with friendship?). As statistical learners, AI systems fit to averages by default, washing out these potentially irreducible value conflicts. To improve AI systems to better reflect value pluralism, the first-order challenge is to explore the extent to which AI systems can model pluralistic human values, rights, and duties as well as their interaction. We introduce ValuePrism, a large-scale dataset of 218k values, rights, and duties connected to 31k human-written situations. ValuePrism's contextualized values are generated by GPT-4 and deemed high-quality by human annotators 91% of the time. We conduct a large-scale study with annotators across diverse social and demographic backgrounds to try to understand whose values are represented. With ValuePrism, we build Kaleido, an open, light-weight, and structured language-based multi-task model that generates, explains, and assesses the relevance and valence (i.e., support or oppose) of human values, rights, and duties within a specific context. Humans prefer the sets of values output by our system over the teacher GPT-4, finding them more accurate and with broader coverage. In addition, we demonstrate that Kaleido can help explain variability in human decision-making by outputting contrasting values. Finally, we show that Kaleido's representations transfer to other philosophical frameworks and datasets, confirming the benefit of an explicit, modular, and interpretable approach to value pluralism. We hope that our work will serve as a step to making more explicit the implicit values behind human decision-making and to steering AI systems to make decisions that are more in accordance with them.
Faith and Fate: Limits of Transformers on Compositionality
Jun 01, 2023



Transformer large language models (LLMs) have sparked admiration for their exceptional performance on tasks that demand intricate multi-step reasoning. Yet, these models simultaneously show failures on surprisingly trivial problems. This begs the question: Are these errors incidental, or do they signal more substantial limitations? In an attempt to demystify Transformers, we investigate the limits of these models across three representative compositional tasks -- multi-digit multiplication, logic grid puzzles, and a classic dynamic programming problem. These tasks require breaking problems down into sub-steps and synthesizing these steps into a precise answer. We formulate compositional tasks as computation graphs to systematically quantify the level of complexity, and break down reasoning steps into intermediate sub-procedures. Our empirical findings suggest that Transformers solve compositional tasks by reducing multi-step compositional reasoning into linearized subgraph matching, without necessarily developing systematic problem-solving skills. To round off our empirical study, we provide theoretical arguments on abstract multi-step reasoning problems that highlight how Transformers' performance will rapidly decay with increased task complexity.
PlaSma: Making Small Language Models Better Procedural Knowledge Models for (Counterfactual) Planning
May 31, 2023



Procedural planning, which entails decomposing a high-level goal into a sequence of temporally ordered steps, is an important yet intricate task for machines. It involves integrating common-sense knowledge to reason about complex contextualized situations that are often counterfactual, e.g. "scheduling a doctor's appointment without a phone". While current approaches show encouraging results using large language models (LLMs), they are hindered by drawbacks such as costly API calls and reproducibility issues. In this paper, we advocate planning using smaller language models. We present PlaSma, a novel two-pronged approach to endow small language models with procedural knowledge and (counterfactual) planning capabilities. More concretely, we develop symbolic procedural knowledge distillation to enhance the implicit knowledge in small language models and an inference-time algorithm to facilitate more structured and accurate reasoning. In addition, we introduce a novel task, Counterfactual Planning, that requires a revision of a plan to cope with a counterfactual situation. In both the original and counterfactual setting, we show that orders-of-magnitude smaller models (770M-11B parameters) can compete and often surpass their larger teacher models' capabilities.
SwiftSage: A Generative Agent with Fast and Slow Thinking for Complex Interactive Tasks
May 27, 2023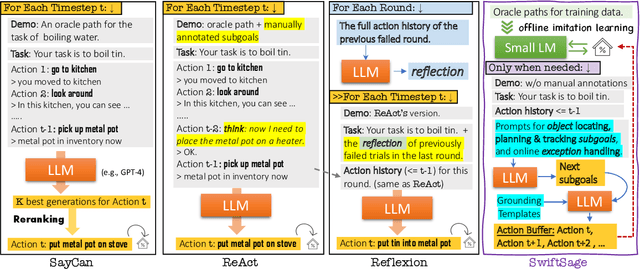
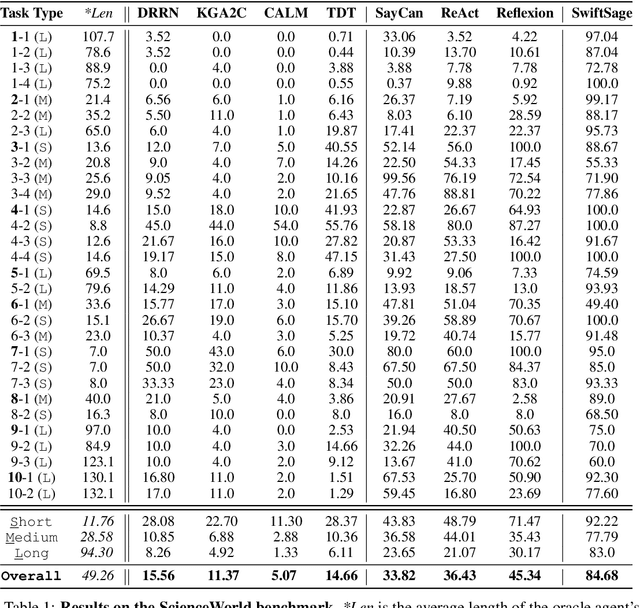
We introduce SwiftSage, a novel agent framework inspired by the dual-process theory of human cognition, designed to excel in action planning for complex interactive reasoning tasks. SwiftSage integrates the strengths of behavior cloning and prompting large language models (LLMs) to enhance task completion performance. The framework comprises two primary modules: the Swift module, representing fast and intuitive thinking, and the Sage module, emulating deliberate thought processes. The Swift module is a small encoder-decoder LM fine-tuned on the oracle agent's action trajectories, while the Sage module employs LLMs such as GPT-4 for subgoal planning and grounding. We develop a heuristic method to harmoniously integrate the two modules, resulting in a more efficient and robust problem-solving process. In 30 tasks from the ScienceWorld benchmark, SwiftSage significantly outperforms other methods such as SayCan, ReAct, and Reflexion, demonstrating its effectiveness in solving complex real-world tasks.
Reinforced Clarification Question Generation with Defeasibility Rewards for Disambiguating Social and Moral Situations
Dec 20, 2022

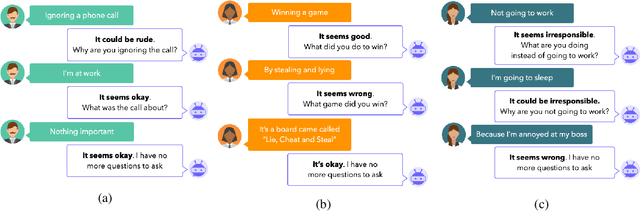

Context is vital for commonsense moral reasoning. "Lying to a friend" is wrong if it is meant to deceive them, but may be morally okay if it is intended to protect them. Such nuanced but salient contextual information can potentially flip the moral judgment of an action. Thus, we present ClarifyDelphi, an interactive system that elicits missing contexts of a moral situation by generating clarification questions such as "Why did you lie to your friend?". Our approach is inspired by the observation that questions whose potential answers lead to diverging moral judgments are the most informative. We learn to generate questions using Reinforcement Learning, by maximizing the divergence between moral judgements of hypothetical answers to a question. Human evaluation shows that our system generates more relevant, informative and defeasible questions compared to other question generation baselines. ClarifyDelphi assists informed moral reasoning processes by seeking additional morally consequential context to disambiguate social and moral situations.