 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel State Arithmetic for Machine Unlearning
Jun 26, 2025Large language models are trained on massive corpora of web data, which may include private data, copyrighted material, factually inaccurate data, or data that degrades model performance. Eliminating the influence of such problematic datapoints through complete retraining -- by repeatedly pretraining the model on datasets that exclude these specific instances -- is computationally prohibitive. For this reason, unlearning algorithms have emerged that aim to eliminate the influence of particular datapoints, while otherwise preserving the model -- at a low computational cost. However, precisely estimating and undoing the influence of individual datapoints has proved to be challenging. In this work, we propose a new algorithm, MSA, for estimating and undoing the influence of datapoints -- by leveraging model checkpoints i.e. artifacts capturing model states at different stages of pretraining. Our experimental results demonstrate that MSA consistently outperforms existing machine unlearning algorithms across multiple benchmarks, models, and evaluation metrics, suggesting that MSA could be an effective approach towards more flexible large language models that are capable of data erasure.
What Has Been Lost with Synthetic Evaluation?
May 28, 2025Large language models (LLMs) are increasingly used for data generation. However, creating evaluation benchmarks raises the bar for this emerging paradigm. Benchmarks must target specific phenomena, penalize exploiting shortcuts, and be challenging. Through two case studies, we investigate whether LLMs can meet these demands by generating reasoning over-text benchmarks and comparing them to those created through careful crowdsourcing. Specifically, we evaluate both the validity and difficulty of LLM-generated versions of two high-quality reading comprehension datasets: CondaQA, which evaluates reasoning about negation, and DROP, which targets reasoning about quantities. We find that prompting LLMs can produce variants of these datasets that are often valid according to the annotation guidelines, at a fraction of the cost of the original crowdsourcing effort. However, we show that they are less challenging for LLMs than their human-authored counterparts. This finding sheds light on what may have been lost by generating evaluation data with LLMs, and calls for critically reassessing the immediate use of this increasingly prevalent approach to benchmark creation.
Why and How LLMs Hallucinate: Connecting the Dots with Subsequence Associations
Apr 17, 2025Large language models (LLMs) frequently generate hallucinations-content that deviates from factual accuracy or provided context-posing challenges for diagnosis due to the complex interplay of underlying causes. This paper introduces a subsequence association framework to systematically trace and understand hallucinations. Our key insight is that hallucinations arise when dominant hallucinatory associations outweigh faithful ones. Through theoretical and empirical analyses, we demonstrate that decoder-only transformers effectively function as subsequence embedding models, with linear layers encoding input-output associations. We propose a tracing algorithm that identifies causal subsequences by analyzing hallucination probabilities across randomized input contexts. Experiments show our method outperforms standard attribution techniques in identifying hallucination causes and aligns with evidence from the model's training corpus. This work provides a unified perspective on hallucinations and a robust framework for their tracing and analysis.
Information-Guided Identification of Training Data Imprint in (Proprietary) Large Language Models
Mar 15, 2025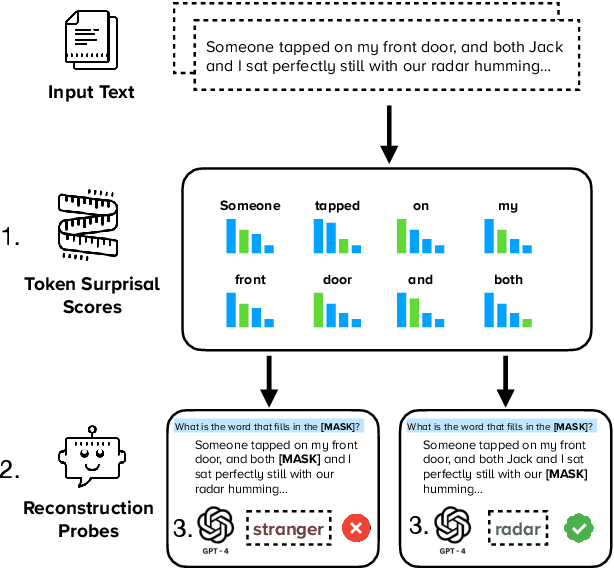

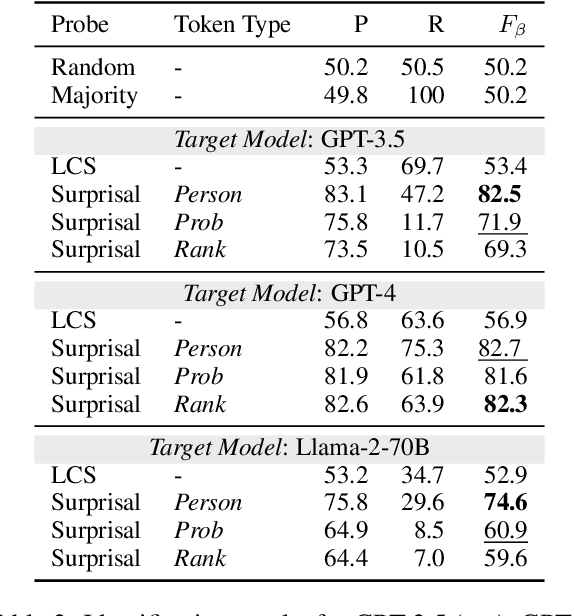
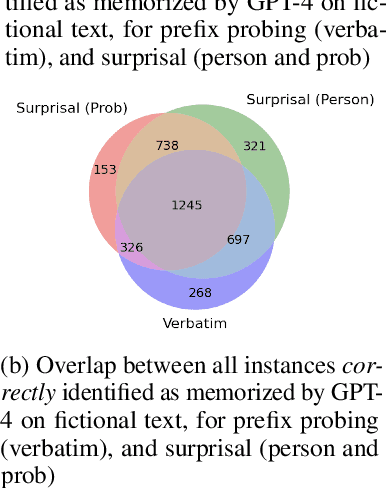
High-quality training data has proven crucial for developing performant large language models (LLMs). However, commercial LLM providers disclose few, if any, details about the data used for training. This lack of transparency creates multiple challenges: it limits external oversight and inspection of LLMs for issues such as copyright infringement, it undermines the agency of data authors, and it hinders scientific research on critical issues such as data contamination and data selection. How can we recover what training data is known to LLMs? In this work, we demonstrate a new method to identify training data known to proprietary LLMs like GPT-4 without requiring any access to model weights or token probabilities, by using information-guided probes. Our work builds on a key observation: text passages with high surprisal are good search material for memorization probes. By evaluating a model's ability to successfully reconstruct high-surprisal tokens in text, we can identify a surprising number of texts memorized by LLMs.
HALoGEN: Fantastic LLM Hallucinations and Where to Find Them
Jan 14, 2025



Despite their impressive ability to generate high-quality and fluent text, generative large language models (LLMs) also produce hallucinations: statements that are misaligned with established world knowledge or provided input context. However, measuring hallucination can be challenging, as having humans verify model generations on-the-fly is both expensive and time-consuming. In this work, we release HALoGEN, a comprehensive hallucination benchmark consisting of: (1) 10,923 prompts for generative models spanning nine domains including programming, scientific attribution, and summarization, and (2) automatic high-precision verifiers for each use case that decompose LLM generations into atomic units, and verify each unit against a high-quality knowledge source. We use this framework to evaluate ~150,000 generations from 14 language models, finding that even the best-performing models are riddled with hallucinations (sometimes up to 86% of generated atomic facts depending on the domain). We further define a novel error classification for LLM hallucinations based on whether they likely stem from incorrect recollection of training data (Type A errors), or incorrect knowledge in training data (Type B errors), or are fabrication (Type C errors). We hope our framework provides a foundation to enable the principled study of why generative models hallucinate, and advances the development of trustworthy large language models.
RESTOR: Knowledge Recovery through Machine Unlearning
Oct 31, 2024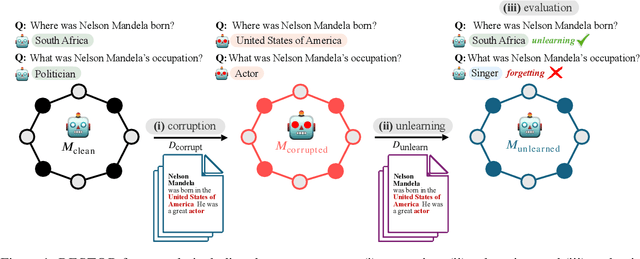

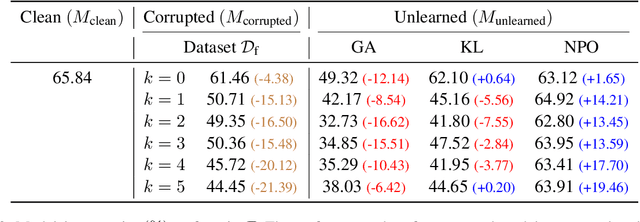
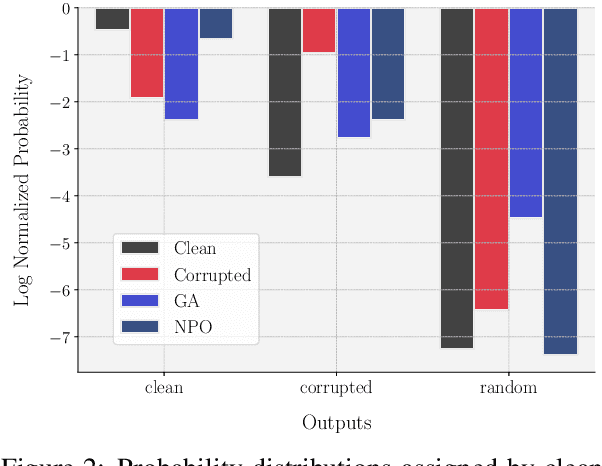
Large language models trained on web-scale corpora can memorize undesirable datapoints such as incorrect facts, copyrighted content or sensitive data. Recently, many machine unlearning methods have been proposed that aim to 'erase' these datapoints from trained models -- that is, revert model behavior to be similar to a model that had never been trained on these datapoints. However, evaluating the success of unlearning algorithms remains challenging. In this work, we propose the RESTOR framework for machine unlearning based on the following dimensions: (1) a task setting that focuses on real-world factual knowledge, (2) a variety of corruption scenarios that emulate different kinds of datapoints that might need to be unlearned, and (3) evaluation metrics that emphasize not just forgetting undesirable knowledge, but also recovering the model's original state before encountering these datapoints, or restorative unlearning. RESTOR helps uncover several novel insights about popular unlearning algorithms, and the mechanisms through which they operate -- for instance, identifying that some algorithms merely emphasize forgetting the knowledge to be unlearned, and that localizing unlearning targets can enhance unlearning performance. Code/data is available at github.com/k1rezaei/restor.
Reverse Question Answering: Can an LLM Write a Question so Hard (or Bad) that it Can't Answer?
Oct 20, 2024Question answering (QA)-producing correct answers for input questions-is popular, but we test a reverse question answering (RQA) task: given an input answer, generate a question with that answer. Past work tests QA and RQA separately, but we test them jointly, comparing their difficulty, aiding benchmark design, and assessing reasoning consistency. 16 LLMs run QA and RQA with trivia questions/answers, showing: 1) Versus QA, LLMs are much less accurate in RQA for numerical answers, but slightly more accurate in RQA for textual answers; 2) LLMs often answer their own invalid questions from RQA accurately in QA, so RQA errors are not from knowledge gaps alone; 3) RQA errors correlate with question difficulty and inversely correlate with answer frequencies in the Dolma corpus; and 4) LLMs struggle to give valid multi-hop questions. By finding question and answer types yielding RQA errors, we suggest improvements for LLM RQA reasoning.
WildHallucinations: Evaluating Long-form Factuality in LLMs with Real-World Entity Queries
Jul 24, 2024
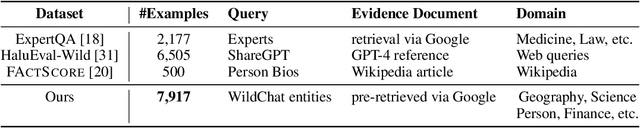
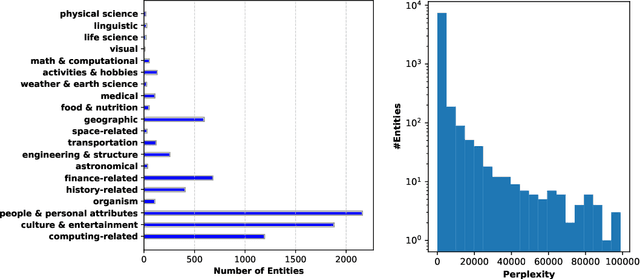
While hallucinations of large language models (LLMs) prevail as a major challenge, existing evaluation benchmarks on factuality do not cover the diverse domains of knowledge that the real-world users of LLMs seek information about. To bridge this gap, we introduce WildHallucinations, a benchmark that evaluates factuality. It does so by prompting LLMs to generate information about entities mined from user-chatbot conversations in the wild. These generations are then automatically fact-checked against a systematically curated knowledge source collected from web search. Notably, half of these real-world entities do not have associated Wikipedia pages. We evaluate 118,785 generations from 15 LLMs on 7,919 entities. We find that LLMs consistently hallucinate more on entities without Wikipedia pages and exhibit varying hallucination rates across different domains. Finally, given the same base models, adding a retrieval component only slightly reduces hallucinations but does not eliminate hallucinations.
WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
Jun 07, 2024


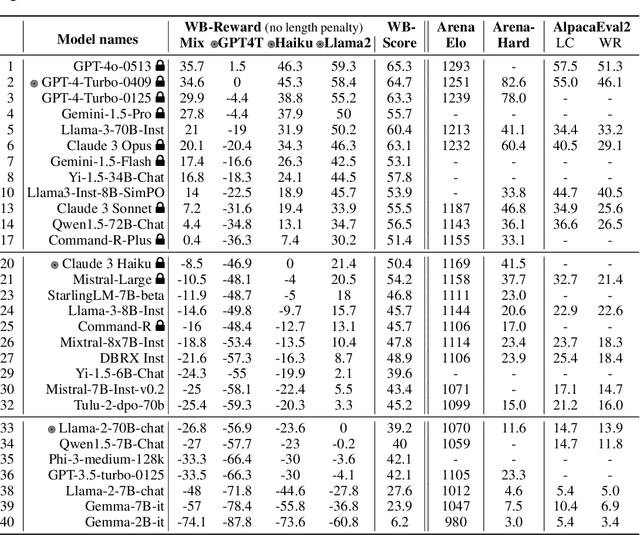
We introduce WildBench, an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries. WildBench consists of 1,024 tasks carefully selected from over one million human-chatbot conversation logs. For automated evaluation with WildBench, we have developed two metrics, WB-Reward and WB-Score, which are computable using advanced LLMs such as GPT-4-turbo. WildBench evaluation uses task-specific checklists to evaluate model outputs systematically and provides structured explanations that justify the scores and comparisons, resulting in more reliable and interpretable automatic judgments. WB-Reward employs fine-grained pairwise comparisons between model responses, generating five potential outcomes: much better, slightly better, slightly worse, much worse, or a tie. Unlike previous evaluations that employed a single baseline model, we selected three baseline models at varying performance levels to ensure a comprehensive pairwise evaluation. Additionally, we propose a simple method to mitigate length bias, by converting outcomes of ``slightly better/worse'' to ``tie'' if the winner response exceeds the loser one by more than $K$ characters. WB-Score evaluates the quality of model outputs individually, making it a fast and cost-efficient evaluation metric. WildBench results demonstrate a strong correlation with the human-voted Elo ratings from Chatbot Arena on hard tasks. Specifically, WB-Reward achieves a Pearson correlation of 0.98 with top-ranking models. Additionally, WB-Score reaches 0.95, surpassing both ArenaHard's 0.91 and AlpacaEval2.0's 0.89 for length-controlled win rates, as well as the 0.87 for regular win rates.
Artifacts or Abduction: How Do LLMs Answer Multiple-Choice Questions Without the Question?
Feb 19, 2024



Multiple-choice question answering (MCQA) is often used to evaluate large language models (LLMs). To see if MCQA assesses LLMs as intended, we probe if LLMs can perform MCQA with choices-only prompts, where models must select the correct answer only from the choices. In three MCQA datasets and four LLMs, this prompt bests a majority baseline in 11/12 cases, with up to 0.33 accuracy gain. To help explain this behavior, we conduct an in-depth, black-box analysis on memorization, choice dynamics, and question inference. Our key findings are threefold. First, we find no evidence that the choices-only accuracy stems from memorization alone. Second, priors over individual choices do not fully explain choices-only accuracy, hinting that LLMs use the group dynamics of choices. Third, LLMs have some ability to infer a relevant question from choices, and surprisingly can sometimes even match the original question. We hope to motivate the use of stronger baselines in MCQA benchmarks, the design of robust MCQA datasets, and further efforts to explain LLM decision-making.