 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecHop: Continuous Speculation for Accelerating Multi-Hop Retrieval Agents
May 21, 2026Large language models increasingly use external tools such as web search and document retrieval to solve information-intensive tasks. However, multi-hop tool use in complex tasks introduces substantial latency, since the model must repeatedly wait for tool observations before continuing. We study how to accelerate such trajectories without changing the final trajectory the model would have taken without acceleration, assuming access to faster but less reliable speculator tools. We develop a theoretical framework for lossless speculation in multi-hop tool-use settings, characterizing the optimal achievable latency gain. We propose SpecHop, a continuous speculation framework that maintains multiple speculative threads, verifies predicted observations asynchronously as target tool outputs arrive, commits correct branches, and rolls back incorrect ones. This preserves accuracy while reducing wall-clock latency. We show that SpecHop can approach oracle latency gains with enough active threads. Empirically, on retrieval-augmented multi-hop tasks, SpecHop closely matches theoretical predictions and reduces latency by up to 40\% in some settings. Code: https://github.com/mehrdadsaberi/spechop
Model-Adaptive Tool Necessity Reveals the Knowing-Doing Gap in LLM Tool Use
May 13, 2026Large language models (LLMs) increasingly act as autonomous agents that must decide when to answer directly vs. when to invoke external tools. Prior work studying adaptive tool use has largely treated tool necessity as a model-agnostic property, annotated by human or LLM judge, and mostly cover cases where the answer is obvious (e.g., fetching the weather vs. paraphrasing text). However, tool necessity in the wild is more nuanced due to the divergence of capability boundaries across models: a problem solvable by a strong model on its own may still require tools for a weaker one. In this work, we introduce a model-adaptive definition of tool-necessity, grounded in each model's empirical performance. Following this definition, we compare the necessity against observed tool-call behavior across four models on arithmetic and factual QA dataset, and find substantial mismatches of 26.5-54.0% and 30.8-41.8%, respectively. To diagnose the failure, we decompose tool use into two stages: an internal cognition stage that reflects whether a model believes a tool is necessary, and an execution stage that determines whether the model actually makes a tool-call action. By probing the LLM hidden states, we find that both signals are often linearly decodable, yet their probe directions become nearly orthogonal in the late-layer, last-token regime that drives the next-token action. By tracing the trajectory of samples in the two-stage process, we further discover that the majority of mismatch is concentrated in the cognition-to-action transition, not in cognition itself. These results reveal a knowing-doing gap in LLM tool-use: improving tool-use reliability requires not only better recognition of when tools are needed, but also better translation of that recognition into action.
Failing to Explore: Language Models on Interactive Tasks
Jan 29, 2026We evaluate language models on their ability to explore interactive environments under a limited interaction budget. We introduce three parametric tasks with controllable exploration difficulty, spanning continuous and discrete environments. Across state-of-the-art models, we find systematic under-exploration and suboptimal solutions, with performance often significantly worse than simple explore--exploit heuristic baselines and scaling weakly as the budget increases. Finally, we study two lightweight interventions: splitting a fixed budget into parallel executions, which surprisingly improves performance despite a no-gain theoretical result for our tasks, and periodically summarizing the interaction history, which preserves key discoveries and further improves exploration.
Model State Arithmetic for Machine Unlearning
Jun 26, 2025


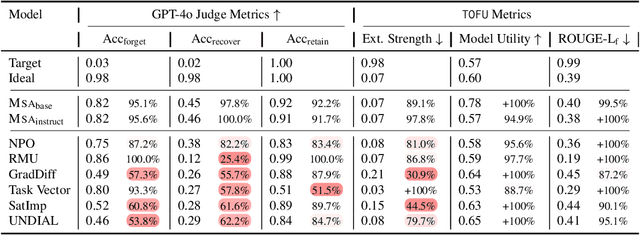
Large language models are trained on massive corpora of web data, which may include private data, copyrighted material, factually inaccurate data, or data that degrades model performance. Eliminating the influence of such problematic datapoints through complete retraining -- by repeatedly pretraining the model on datasets that exclude these specific instances -- is computationally prohibitive. For this reason, unlearning algorithms have emerged that aim to eliminate the influence of particular datapoints, while otherwise preserving the model -- at a low computational cost. However, precisely estimating and undoing the influence of individual datapoints has proved to be challenging. In this work, we propose a new algorithm, MSA, for estimating and undoing the influence of datapoints -- by leveraging model checkpoints i.e. artifacts capturing model states at different stages of pretraining. Our experimental results demonstrate that MSA consistently outperforms existing machine unlearning algorithms across multiple benchmarks, models, and evaluation metrics, suggesting that MSA could be an effective approach towards more flexible large language models that are capable of data erasure.
Localizing Knowledge in Diffusion Transformers
May 24, 2025Understanding how knowledge is distributed across the layers of generative models is crucial for improving interpretability, controllability, and adaptation. While prior work has explored knowledge localization in UNet-based architectures, Diffusion Transformer (DiT)-based models remain underexplored in this context. In this paper, we propose a model- and knowledge-agnostic method to localize where specific types of knowledge are encoded within the DiT blocks. We evaluate our method on state-of-the-art DiT-based models, including PixArt-alpha, FLUX, and SANA, across six diverse knowledge categories. We show that the identified blocks are both interpretable and causally linked to the expression of knowledge in generated outputs. Building on these insights, we apply our localization framework to two key applications: model personalization and knowledge unlearning. In both settings, our localized fine-tuning approach enables efficient and targeted updates, reducing computational cost, improving task-specific performance, and better preserving general model behavior with minimal interference to unrelated or surrounding content. Overall, our findings offer new insights into the internal structure of DiTs and introduce a practical pathway for more interpretable, efficient, and controllable model editing.
RePanda: Pandas-powered Tabular Verification and Reasoning
Mar 14, 2025Fact-checking tabular data is essential for ensuring the accuracy of structured information. However, existing methods often rely on black-box models with opaque reasoning. We introduce RePanda, a structured fact verification approach that translates claims into executable pandas queries, enabling interpretable and verifiable reasoning. To train RePanda, we construct PanTabFact, a structured dataset derived from the TabFact train set, where claims are paired with executable queries generated using DeepSeek-Chat and refined through automated error correction. Fine-tuning DeepSeek-coder-7B-instruct-v1.5 on PanTabFact, RePanda achieves 84.09% accuracy on the TabFact test set. To evaluate Out-of-Distribution (OOD) generalization, we interpret question-answer pairs from WikiTableQuestions as factual claims and refer to this dataset as WikiFact. Without additional fine-tuning, RePanda achieves 84.72% accuracy on WikiFact, significantly outperforming all other baselines and demonstrating strong OOD robustness. Notably, these results closely match the zero-shot performance of DeepSeek-Chat (671B), indicating that our fine-tuning approach effectively distills structured reasoning from a much larger model into a compact, locally executable 7B model. Beyond fact verification, RePanda extends to tabular question answering by generating executable queries that retrieve precise answers. To support this, we introduce PanWiki, a dataset mapping WikiTableQuestions to pandas queries. Fine-tuning on PanWiki, RePanda achieves 75.1% accuracy in direct answer retrieval. These results highlight the effectiveness of structured execution-based reasoning for tabular verification and question answering. We have publicly released the dataset on Hugging Face at datasets/AtoosaChegini/PanTabFact.
A Survey on Mechanistic Interpretability for Multi-Modal Foundation Models
Feb 22, 2025



The rise of foundation models has transformed machine learning research, prompting efforts to uncover their inner workings and develop more efficient and reliable applications for better control. While significant progress has been made in interpreting Large Language Models (LLMs), multimodal foundation models (MMFMs) - such as contrastive vision-language models, generative vision-language models, and text-to-image models - pose unique interpretability challenges beyond unimodal frameworks. Despite initial studies, a substantial gap remains between the interpretability of LLMs and MMFMs. This survey explores two key aspects: (1) the adaptation of LLM interpretability methods to multimodal models and (2) understanding the mechanistic differences between unimodal language models and crossmodal systems. By systematically reviewing current MMFM analysis techniques, we propose a structured taxonomy of interpretability methods, compare insights across unimodal and multimodal architectures, and highlight critical research gaps.
RESTOR: Knowledge Recovery through Machine Unlearning
Oct 31, 2024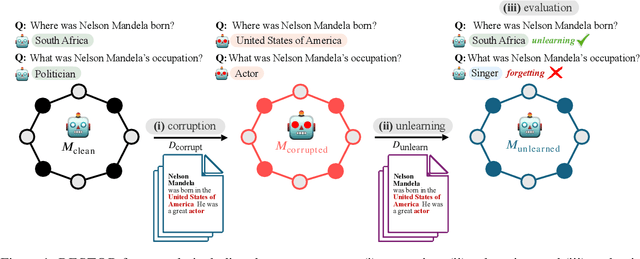

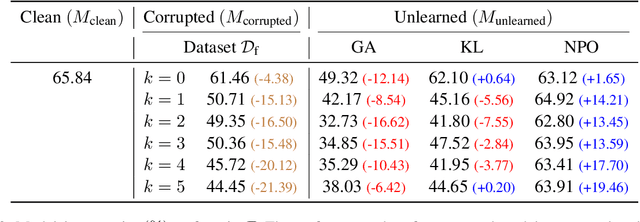
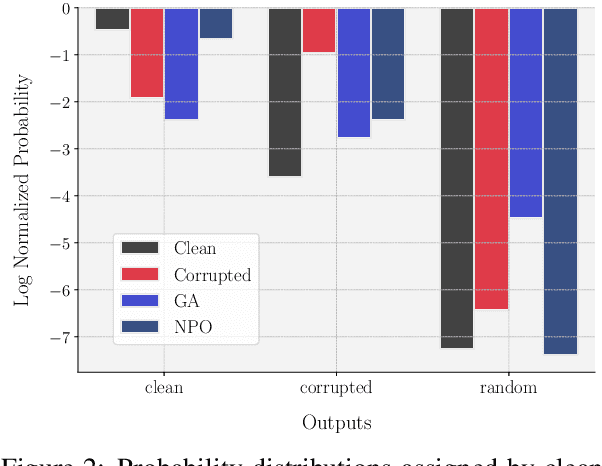
Large language models trained on web-scale corpora can memorize undesirable datapoints such as incorrect facts, copyrighted content or sensitive data. Recently, many machine unlearning methods have been proposed that aim to 'erase' these datapoints from trained models -- that is, revert model behavior to be similar to a model that had never been trained on these datapoints. However, evaluating the success of unlearning algorithms remains challenging. In this work, we propose the RESTOR framework for machine unlearning based on the following dimensions: (1) a task setting that focuses on real-world factual knowledge, (2) a variety of corruption scenarios that emulate different kinds of datapoints that might need to be unlearned, and (3) evaluation metrics that emphasize not just forgetting undesirable knowledge, but also recovering the model's original state before encountering these datapoints, or restorative unlearning. RESTOR helps uncover several novel insights about popular unlearning algorithms, and the mechanisms through which they operate -- for instance, identifying that some algorithms merely emphasize forgetting the knowledge to be unlearned, and that localizing unlearning targets can enhance unlearning performance. Code/data is available at github.com/k1rezaei/restor.
Understanding and Mitigating Compositional Issues in Text-to-Image Generative Models
Jun 12, 2024



Recent text-to-image diffusion-based generative models have the stunning ability to generate highly detailed and photo-realistic images and achieve state-of-the-art low FID scores on challenging image generation benchmarks. However, one of the primary failure modes of these text-to-image generative models is in composing attributes, objects, and their associated relationships accurately into an image. In our paper, we investigate this compositionality-based failure mode and highlight that imperfect text conditioning with CLIP text-encoder is one of the primary reasons behind the inability of these models to generate high-fidelity compositional scenes. In particular, we show that (i) there exists an optimal text-embedding space that can generate highly coherent compositional scenes which shows that the output space of the CLIP text-encoder is sub-optimal, and (ii) we observe that the final token embeddings in CLIP are erroneous as they often include attention contributions from unrelated tokens in compositional prompts. Our main finding shows that the best compositional improvements can be achieved (without harming the model's FID scores) by fine-tuning {\it only} a simple linear projection on CLIP's representation space in Stable-Diffusion variants using a small set of compositional image-text pairs. This result demonstrates that the sub-optimality of the CLIP's output space is a major error source. We also show that re-weighting the erroneous attention contributions in CLIP can also lead to improved compositional performances, however these improvements are often less significant than those achieved by solely learning a linear projection head, highlighting erroneous attentions to be only a minor error source.
Ad Auctions for LLMs via Retrieval Augmented Generation
Jun 12, 2024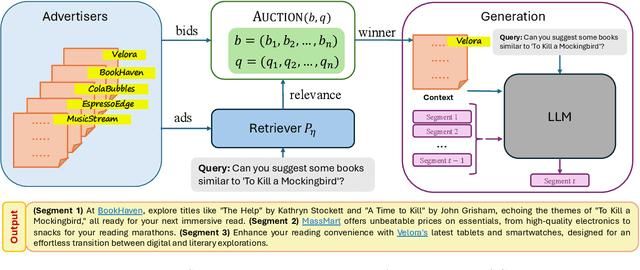



In the field of computational advertising, the integration of ads into the outputs of large language models (LLMs) presents an opportunity to support these services without compromising content integrity. This paper introduces novel auction mechanisms for ad allocation and pricing within the textual outputs of LLMs, leveraging retrieval-augmented generation (RAG). We propose a segment auction where an ad is probabilistically retrieved for each discourse segment (paragraph, section, or entire output) according to its bid and relevance, following the RAG framework, and priced according to competing bids. We show that our auction maximizes logarithmic social welfare, a new notion of welfare that balances allocation efficiency and fairness, and we characterize the associated incentive-compatible pricing rule. These results are extended to multi-ad allocation per segment. An empirical evaluation validates the feasibility and effectiveness of our approach over several ad auction scenarios, and exhibits inherent tradeoffs in metrics as we allow the LLM more flexibility to allocate ads.