 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Mechanistic Circuits for Extractive Question-Answering
Feb 12, 2025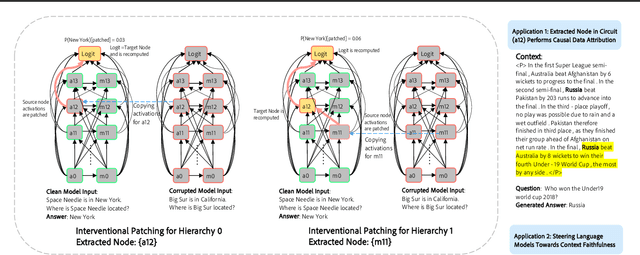
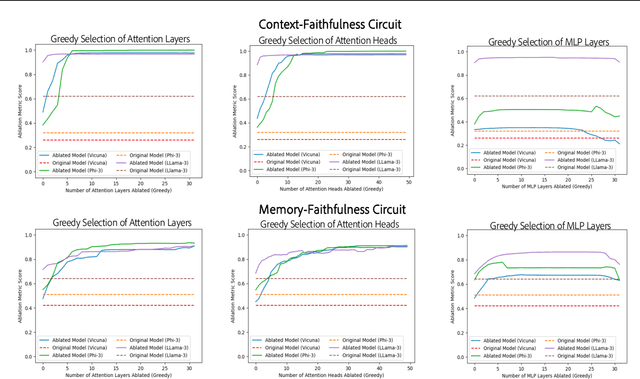
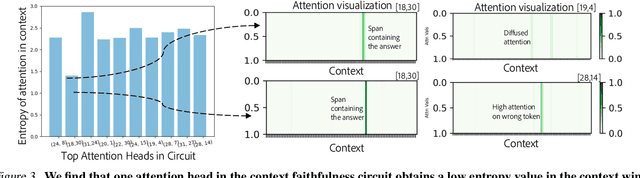
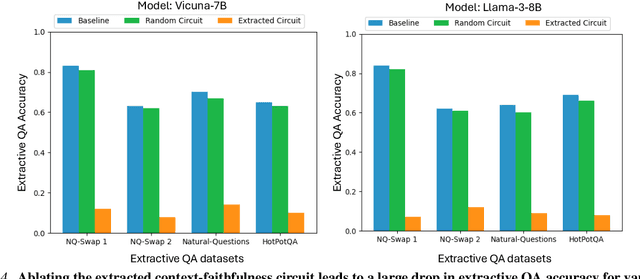
Large language models are increasingly used to process documents and facilitate question-answering on them. In our paper, we extract mechanistic circuits for this real-world language modeling task: context-augmented language modeling for extractive question-answering (QA) tasks and understand the potential benefits of circuits towards downstream applications such as data attribution to context information. We extract circuits as a function of internal model components (e.g., attention heads, MLPs) using causal mediation analysis techniques. Leveraging the extracted circuits, we first understand the interplay between the model's usage of parametric memory and retrieved context towards a better mechanistic understanding of context-augmented language models. We then identify a small set of attention heads in our circuit which performs reliable data attribution by default, thereby obtaining attribution for free in just the model's forward pass. Using this insight, we then introduce ATTNATTRIB, a fast data attribution algorithm which obtains state-of-the-art attribution results across various extractive QA benchmarks. Finally, we show the possibility to steer the language model towards answering from the context, instead of the parametric memory by using the attribution from ATTNATTRIB as an additional signal during the forward pass. Beyond mechanistic understanding, our paper provides tangible applications of circuits in the form of reliable data attribution and model steering.
On Mechanistic Knowledge Localization in Text-to-Image Generative Models
May 02, 2024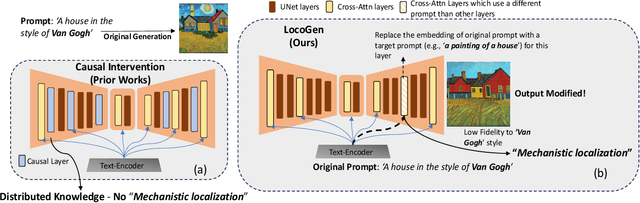
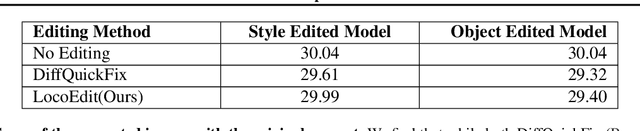
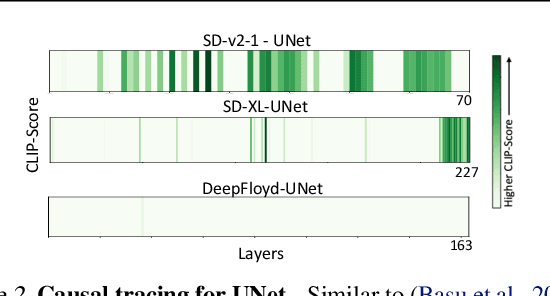
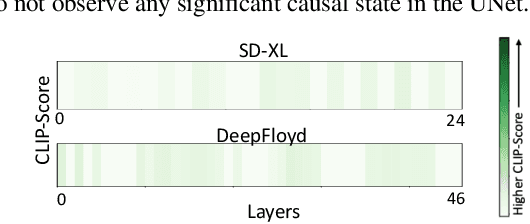
Identifying layers within text-to-image models which control visual attributes can facilitate efficient model editing through closed-form updates. Recent work, leveraging causal tracing show that early Stable-Diffusion variants confine knowledge primarily to the first layer of the CLIP text-encoder, while it diffuses throughout the UNet.Extending this framework, we observe that for recent models (e.g., SD-XL, DeepFloyd), causal tracing fails in pinpointing localized knowledge, highlighting challenges in model editing. To address this issue, we introduce the concept of Mechanistic Localization in text-to-image models, where knowledge about various visual attributes (e.g., ``style", ``objects", ``facts") can be mechanistically localized to a small fraction of layers in the UNet, thus facilitating efficient model editing. We localize knowledge using our method LocoGen which measures the direct effect of intermediate layers to output generation by performing interventions in the cross-attention layers of the UNet. We then employ LocoEdit, a fast closed-form editing method across popular open-source text-to-image models (including the latest SD-XL)and explore the possibilities of neuron-level model editing. Using Mechanistic Localization, our work offers a better view of successes and failures in localization-based text-to-image model editing. Code will be available at \href{https://github.com/samyadeepbasu/LocoGen}{https://github.com/samyadeepbasu/LocoGen}.