 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSliderEdit: Continuous Image Editing with Fine-Grained Instruction Control
Nov 12, 2025Instruction-based image editing models have recently achieved impressive performance, enabling complex edits to an input image from a multi-instruction prompt. However, these models apply each instruction in the prompt with a fixed strength, limiting the user's ability to precisely and continuously control the intensity of individual edits. We introduce SliderEdit, a framework for continuous image editing with fine-grained, interpretable instruction control. Given a multi-part edit instruction, SliderEdit disentangles the individual instructions and exposes each as a globally trained slider, allowing smooth adjustment of its strength. Unlike prior works that introduced slider-based attribute controls in text-to-image generation, typically requiring separate training or fine-tuning for each attribute or concept, our method learns a single set of low-rank adaptation matrices that generalize across diverse edits, attributes, and compositional instructions. This enables continuous interpolation along individual edit dimensions while preserving both spatial locality and global semantic consistency. We apply SliderEdit to state-of-the-art image editing models, including FLUX-Kontext and Qwen-Image-Edit, and observe substantial improvements in edit controllability, visual consistency, and user steerability. To the best of our knowledge, we are the first to explore and propose a framework for continuous, fine-grained instruction control in instruction-based image editing models. Our results pave the way for interactive, instruction-driven image manipulation with continuous and compositional control.
Decomposition-Enhanced Training for Post-Hoc Attributions In Language Models
Oct 29, 2025Large language models (LLMs) are increasingly used for long-document question answering, where reliable attribution to sources is critical for trust. Existing post-hoc attribution methods work well for extractive QA but struggle in multi-hop, abstractive, and semi-extractive settings, where answers synthesize information across passages. To address these challenges, we argue that post-hoc attribution can be reframed as a reasoning problem, where answers are decomposed into constituent units, each tied to specific context. We first show that prompting models to generate such decompositions alongside attributions improves performance. Building on this, we introduce DecompTune, a post-training method that teaches models to produce answer decompositions as intermediate reasoning steps. We curate a diverse dataset of complex QA tasks, annotated with decompositions by a strong LLM, and post-train Qwen-2.5 (7B and 14B) using a two-stage SFT + GRPO pipeline with task-specific curated rewards. Across extensive experiments and ablations, DecompTune substantially improves attribution quality, outperforming prior methods and matching or exceeding state-of-the-art frontier models.
Steering MoE LLMs via Expert (De)Activation
Sep 11, 2025



Mixture-of-Experts (MoE) in Large Language Models (LLMs) routes each token through a subset of specialized Feed-Forward Networks (FFN), known as experts. We present SteerMoE, a framework for steering MoE models by detecting and controlling behavior-linked experts. Our detection method identifies experts with distinct activation patterns across paired inputs exhibiting contrasting behaviors. By selectively (de)activating such experts during inference, we control behaviors like faithfulness and safety without retraining or modifying weights. Across 11 benchmarks and 6 LLMs, our steering raises safety by up to +20% and faithfulness by +27%. In adversarial attack mode, it drops safety by -41% alone, and -100% when combined with existing jailbreak methods, bypassing all safety guardrails and exposing a new dimension of alignment faking hidden within experts.
VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
Aug 10, 2025Most organizational data in this world are stored as documents, and visual retrieval plays a crucial role in unlocking the collective intelligence from all these documents. However, existing benchmarks focus on English-only document retrieval or only consider multilingual question-answering on a single-page image. To bridge this gap, we introduce VisR-Bench, a multilingual benchmark designed for question-driven multimodal retrieval in long documents. Our benchmark comprises over 35K high-quality QA pairs across 1.2K documents, enabling fine-grained evaluation of multimodal retrieval. VisR-Bench spans sixteen languages with three question types (figures, text, and tables), offering diverse linguistic and question coverage. Unlike prior datasets, we include queries without explicit answers, preventing models from relying on superficial keyword matching. We evaluate various retrieval models, including text-based methods, multimodal encoders, and MLLMs, providing insights into their strengths and limitations. Our results show that while MLLMs significantly outperform text-based and multimodal encoder models, they still struggle with structured tables and low-resource languages, highlighting key challenges in multilingual visual retrieval.
A Survey on Long-Video Storytelling Generation: Architectures, Consistency, and Cinematic Quality
Jul 09, 2025

Despite the significant progress that has been made in video generative models, existing state-of-the-art methods can only produce videos lasting 5-16 seconds, often labeled "long-form videos". Furthermore, videos exceeding 16 seconds struggle to maintain consistent character appearances and scene layouts throughout the narrative. In particular, multi-subject long videos still fail to preserve character consistency and motion coherence. While some methods can generate videos up to 150 seconds long, they often suffer from frame redundancy and low temporal diversity. Recent work has attempted to produce long-form videos featuring multiple characters, narrative coherence, and high-fidelity detail. We comprehensively studied 32 papers on video generation to identify key architectural components and training strategies that consistently yield these qualities. We also construct a comprehensive novel taxonomy of existing methods and present comparative tables that categorize papers by their architectural designs and performance characteristics.
Learning to Clarify by Reinforcement Learning Through Reward-Weighted Fine-Tuning
Jun 08, 2025


Question answering (QA) agents automatically answer questions posed in natural language. In this work, we learn to ask clarifying questions in QA agents. The key idea in our method is to simulate conversations that contain clarifying questions and learn from them using reinforcement learning (RL). To make RL practical, we propose and analyze offline RL objectives that can be viewed as reward-weighted supervised fine-tuning (SFT) and easily optimized in large language models. Our work stands in a stark contrast to recently proposed methods, based on SFT and direct preference optimization, which have additional hyper-parameters and do not directly optimize rewards. We compare to these methods empirically and report gains in both optimized rewards and language quality.
Chart-to-Experience: Benchmarking Multimodal LLMs for Predicting Experiential Impact of Charts
May 23, 2025
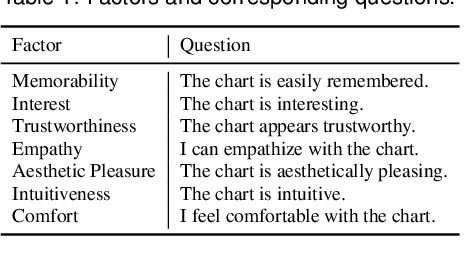

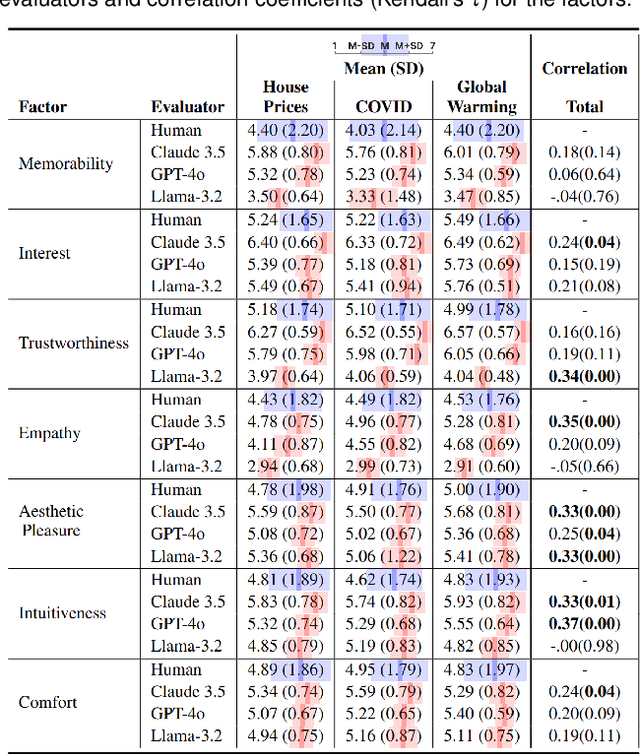
The field of Multimodal Large Language Models (MLLMs) has made remarkable progress in visual understanding tasks, presenting a vast opportunity to predict the perceptual and emotional impact of charts. However, it also raises concerns, as many applications of LLMs are based on overgeneralized assumptions from a few examples, lacking sufficient validation of their performance and effectiveness. We introduce Chart-to-Experience, a benchmark dataset comprising 36 charts, evaluated by crowdsourced workers for their impact on seven experiential factors. Using the dataset as ground truth, we evaluated capabilities of state-of-the-art MLLMs on two tasks: direct prediction and pairwise comparison of charts. Our findings imply that MLLMs are not as sensitive as human evaluators when assessing individual charts, but are accurate and reliable in pairwise comparisons.
CachePrune: Neural-Based Attribution Defense Against Indirect Prompt Injection Attacks
Apr 29, 2025Large Language Models (LLMs) are identified as being susceptible to indirect prompt injection attack, where the model undesirably deviates from user-provided instructions by executing tasks injected in the prompt context. This vulnerability stems from LLMs' inability to distinguish between data and instructions within a prompt. In this paper, we propose CachePrune that defends against this attack by identifying and pruning task-triggering neurons from the KV cache of the input prompt context. By pruning such neurons, we encourage the LLM to treat the text spans of input prompt context as only pure data, instead of any indicator of instruction following. These neurons are identified via feature attribution with a loss function induced from an upperbound of the Direct Preference Optimization (DPO) objective. We show that such a loss function enables effective feature attribution with only a few samples. We further improve on the quality of feature attribution, by exploiting an observed triggering effect in instruction following. Our approach does not impose any formatting on the original prompt or introduce extra test-time LLM calls. Experiments show that CachePrune significantly reduces attack success rates without compromising the response quality. Note: This paper aims to defend against indirect prompt injection attacks, with the goal of developing more secure and robust AI systems.
WaterFlow: Learning Fast & Robust Watermarks using Stable Diffusion
Apr 18, 2025The ability to embed watermarks in images is a fundamental problem of interest for computer vision, and is exacerbated by the rapid rise of generated imagery in recent times. Current state-of-the-art techniques suffer from computational and statistical challenges such as the slow execution speed for practical deployments. In addition, other works trade off fast watermarking speeds but suffer greatly in their robustness or perceptual quality. In this work, we propose WaterFlow (WF), a fast and extremely robust approach for high fidelity visual watermarking based on a learned latent-dependent watermark. Our approach utilizes a pretrained latent diffusion model to encode an arbitrary image into a latent space and produces a learned watermark that is then planted into the Fourier Domain of the latent. The transformation is specified via invertible flow layers that enhance the expressivity of the latent space of the pre-trained model to better preserve image quality while permitting robust and tractable detection. Most notably, WaterFlow demonstrates state-of-the-art performance on general robustness and is the first method capable of effectively defending against difficult combination attacks. We validate our findings on three widely used real and generated datasets: MS-COCO, DiffusionDB, and WikiArt.
A Survey on Personalized and Pluralistic Preference Alignment in Large Language Models
Apr 09, 2025Personalized preference alignment for large language models (LLMs), the process of tailoring LLMs to individual users' preferences, is an emerging research direction spanning the area of NLP and personalization. In this survey, we present an analysis of works on personalized alignment and modeling for LLMs. We introduce a taxonomy of preference alignment techniques, including training time, inference time, and additionally, user-modeling based methods. We provide analysis and discussion on the strengths and limitations of each group of techniques and then cover evaluation, benchmarks, as well as open problems in the field.