 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Contextually Aligned Online Reviews to Measure LLMs' Performance Disparities Across Language Varieties
Feb 10, 2025A language can have different varieties. These varieties can affect the performance of natural language processing (NLP) models, including large language models (LLMs), which are often trained on data from widely spoken varieties. This paper introduces a novel and cost-effective approach to benchmark model performance across language varieties. We argue that international online review platforms, such as Booking.com, can serve as effective data sources for constructing datasets that capture comments in different language varieties from similar real-world scenarios, like reviews for the same hotel with the same rating using the same language (e.g., Mandarin Chinese) but different language varieties (e.g., Taiwan Mandarin, Mainland Mandarin). To prove this concept, we constructed a contextually aligned dataset comprising reviews in Taiwan Mandarin and Mainland Mandarin and tested six LLMs in a sentiment analysis task. Our results show that LLMs consistently underperform in Taiwan Mandarin.
Do Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SCICAP Challenge 2023
Jan 31, 2025
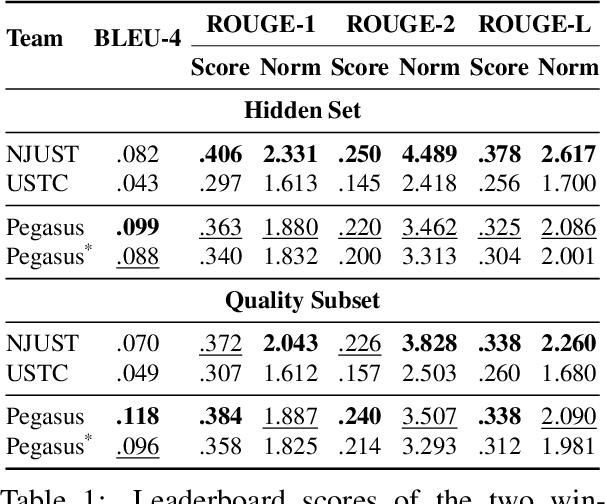
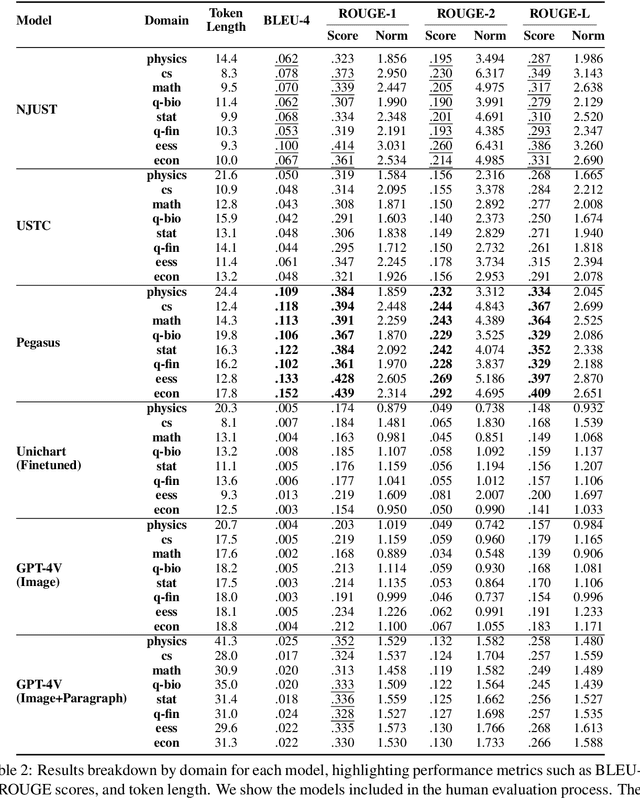
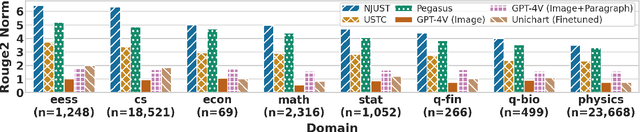
Since the SCICAP datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SCICAP Challenge took place, inviting global teams to use an expanded SCICAP dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SCICAP Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?
Multi-LLM Collaborative Caption Generation in Scientific Documents
Jan 05, 2025



Scientific figure captioning is a complex task that requires generating contextually appropriate descriptions of visual content. However, existing methods often fall short by utilizing incomplete information, treating the task solely as either an image-to-text or text summarization problem. This limitation hinders the generation of high-quality captions that fully capture the necessary details. Moreover, existing data sourced from arXiv papers contain low-quality captions, posing significant challenges for training large language models (LLMs). In this paper, we introduce a framework called Multi-LLM Collaborative Figure Caption Generation (MLBCAP) to address these challenges by leveraging specialized LLMs for distinct sub-tasks. Our approach unfolds in three key modules: (Quality Assessment) We utilize multimodal LLMs to assess the quality of training data, enabling the filtration of low-quality captions. (Diverse Caption Generation) We then employ a strategy of fine-tuning/prompting multiple LLMs on the captioning task to generate candidate captions. (Judgment) Lastly, we prompt a prominent LLM to select the highest quality caption from the candidates, followed by refining any remaining inaccuracies. Human evaluations demonstrate that informative captions produced by our approach rank better than human-written captions, highlighting its effectiveness. Our code is available at https://github.com/teamreboott/MLBCAP
Generating Educational Materials with Different Levels of Readability using LLMs
Jun 18, 2024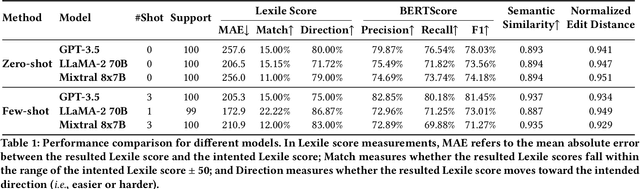
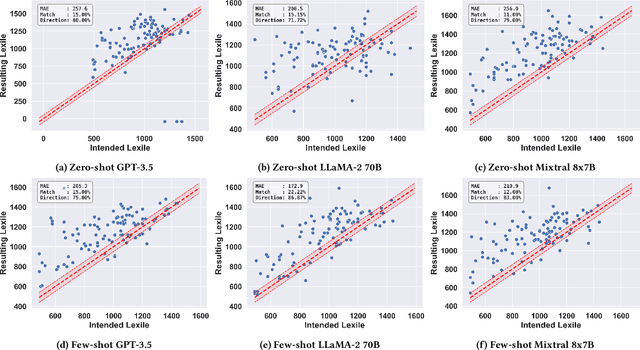
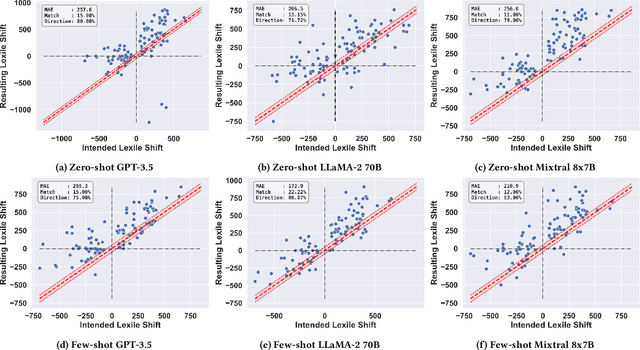
This study introduces the leveled-text generation task, aiming to rewrite educational materials to specific readability levels while preserving meaning. We assess the capability of GPT-3.5, LLaMA-2 70B, and Mixtral 8x7B, to generate content at various readability levels through zero-shot and few-shot prompting. Evaluating 100 processed educational materials reveals that few-shot prompting significantly improves performance in readability manipulation and information preservation. LLaMA-2 70B performs better in achieving the desired difficulty range, while GPT-3.5 maintains original meaning. However, manual inspection highlights concerns such as misinformation introduction and inconsistent edit distribution. These findings emphasize the need for further research to ensure the quality of generated educational content.
SciCapenter: Supporting Caption Composition for Scientific Figures with Machine-Generated Captions and Ratings
Mar 26, 2024
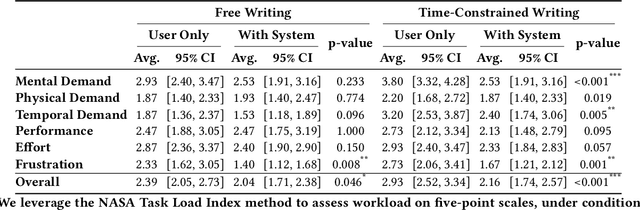

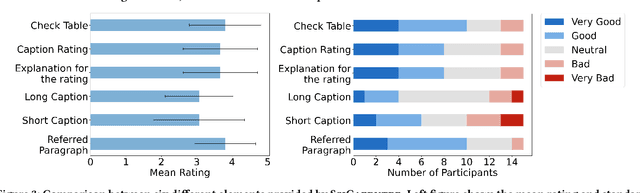
Crafting effective captions for figures is important. Readers heavily depend on these captions to grasp the figure's message. However, despite a well-developed set of AI technologies for figures and captions, these have rarely been tested for usefulness in aiding caption writing. This paper introduces SciCapenter, an interactive system that puts together cutting-edge AI technologies for scientific figure captions to aid caption composition. SciCapenter generates a variety of captions for each figure in a scholarly article, providing scores and a comprehensive checklist to assess caption quality across multiple critical aspects, such as helpfulness, OCR mention, key takeaways, and visual properties reference. Users can directly edit captions in SciCapenter, resubmit for revised evaluations, and iteratively refine them. A user study with Ph.D. students indicates that SciCapenter significantly lowers the cognitive load of caption writing. Participants' feedback further offers valuable design insights for future systems aiming to enhance caption writing.
If in a Crowdsourced Data Annotation Pipeline, a GPT-4
Feb 26, 2024



Recent studies indicated GPT-4 outperforms online crowd workers in data labeling accuracy, notably workers from Amazon Mechanical Turk (MTurk). However, these studies were criticized for deviating from standard crowdsourcing practices and emphasizing individual workers' performances over the whole data-annotation process. This paper compared GPT-4 and an ethical and well-executed MTurk pipeline, with 415 workers labeling 3,177 sentence segments from 200 scholarly articles using the CODA-19 scheme. Two worker interfaces yielded 127,080 labels, which were then used to infer the final labels through eight label-aggregation algorithms. Our evaluation showed that despite best practices, MTurk pipeline's highest accuracy was 81.5%, whereas GPT-4 achieved 83.6%. Interestingly, when combining GPT-4's labels with crowd labels collected via an advanced worker interface for aggregation, 2 out of the 8 algorithms achieved an even higher accuracy (87.5%, 87.0%). Further analysis suggested that, when the crowd's and GPT-4's labeling strengths are complementary, aggregating them could increase labeling accuracy.
GPT-4 as an Effective Zero-Shot Evaluator for Scientific Figure Captions
Oct 23, 2023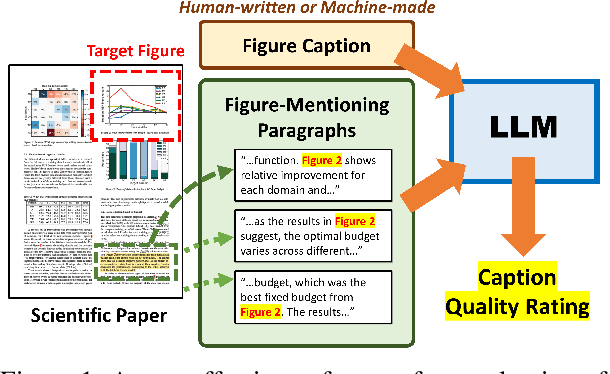
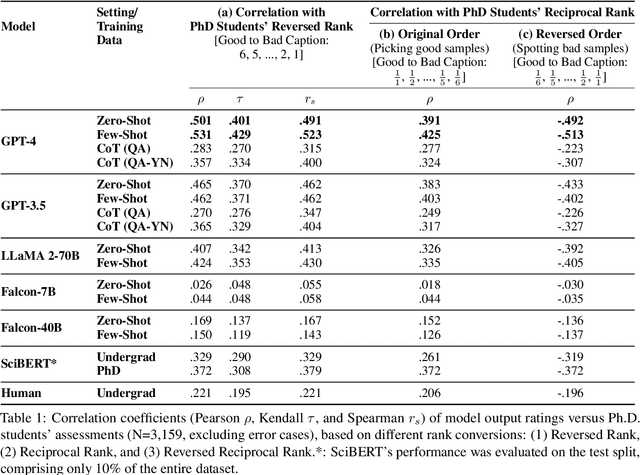
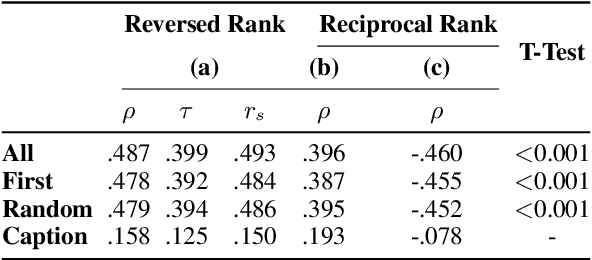
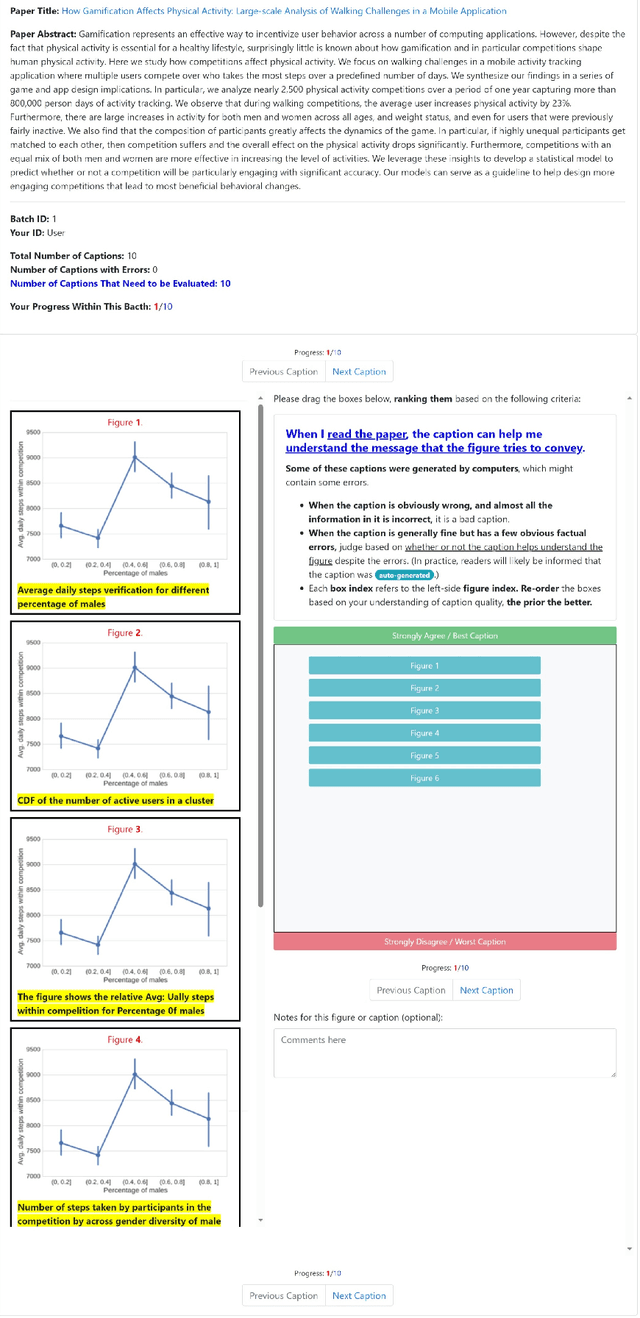
There is growing interest in systems that generate captions for scientific figures. However, assessing these systems output poses a significant challenge. Human evaluation requires academic expertise and is costly, while automatic evaluation depends on often low-quality author-written captions. This paper investigates using large language models (LLMs) as a cost-effective, reference-free method for evaluating figure captions. We first constructed SCICAP-EVAL, a human evaluation dataset that contains human judgments for 3,600 scientific figure captions, both original and machine-made, for 600 arXiv figures. We then prompted LLMs like GPT-4 and GPT-3 to score (1-6) each caption based on its potential to aid reader understanding, given relevant context such as figure-mentioning paragraphs. Results show that GPT-4, used as a zero-shot evaluator, outperformed all other models and even surpassed assessments made by Computer Science and Informatics undergraduates, achieving a Kendall correlation score of 0.401 with Ph.D. students rankings
Good Data, Large Data, or No Data? Comparing Three Approaches in Developing Research Aspect Classifiers for Biomedical Papers
Jun 07, 2023The rapid growth of scientific publications, particularly during the COVID-19 pandemic, emphasizes the need for tools to help researchers efficiently comprehend the latest advancements. One essential part of understanding scientific literature is research aspect classification, which categorizes sentences in abstracts to Background, Purpose, Method, and Finding. In this study, we investigate the impact of different datasets on model performance for the crowd-annotated CODA-19 research aspect classification task. Specifically, we explore the potential benefits of using the large, automatically curated PubMed 200K RCT dataset and evaluate the effectiveness of large language models (LLMs), such as LLaMA, GPT-3, ChatGPT, and GPT-4. Our results indicate that using the PubMed 200K RCT dataset does not improve performance for the CODA-19 task. We also observe that while GPT-4 performs well, it does not outperform the SciBERT model fine-tuned on the CODA-19 dataset, emphasizing the importance of a dedicated and task-aligned datasets dataset for the target task. Our code is available at https://github.com/Crowd-AI-Lab/CODA-19-exp.
ConvXAI: Delivering Heterogeneous AI Explanations via Conversations to Support Human-AI Scientific Writing
May 16, 2023While various AI explanation (XAI) methods have been proposed to interpret AI systems, whether the state-of-the-art XAI methods are practically useful for humans remains inconsistent findings. To improve the usefulness of XAI methods, a line of studies identifies the gaps between the diverse and dynamic real-world user needs with the status quo of XAI methods. Although prior studies envision mitigating these gaps by integrating multiple XAI methods into the universal XAI interfaces (e.g., conversational or GUI-based XAI systems), there is a lack of work investigating how these systems should be designed to meet practical user needs. In this study, we present ConvXAI, a conversational XAI system that incorporates multiple XAI types, and empowers users to request a variety of XAI questions via a universal XAI dialogue interface. Particularly, we innovatively embed practical user needs (i.e., four principles grounding on the formative study) into ConvXAI design to improve practical usefulness. Further, we design the domain-specific language (DSL) to implement the essential conversational XAI modules and release the core conversational universal XAI API for generalization. The findings from two within-subjects studies with 21 users show that ConvXAI is more useful for humans in perceiving the understanding and writing improvement, and improving the writing process in terms of productivity and sentence quality. Finally, this work contributes insight into the design space of useful XAI, reveals humans' XAI usage patterns with empirical evidence in practice, and identifies opportunities for future useful XAI work.
What Types of Questions Require Conversation to Answer? A Case Study of AskReddit Questions
Apr 03, 2023



The proliferation of automated conversational systems such as chatbots, spoken-dialogue systems, and smart speakers, has significantly impacted modern digital life. However, these systems are primarily designed to provide answers to well-defined questions rather than to support users in exploring complex, ill-defined questions. In this paper, we aim to push the boundaries of conversational systems by examining the types of nebulous, open-ended questions that can best be answered through conversation. We first sampled 500 questions from one million open-ended requests posted on AskReddit, and then recruited online crowd workers to answer eight inquiries about these questions. We also performed open coding to categorize the questions into 27 different domains. We found that the issues people believe require conversation to resolve satisfactorily are highly social and personal. Our work provides insights into how future research could be geared to align with users' needs.