 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIf in a Crowdsourced Data Annotation Pipeline, a GPT-4
Feb 26, 2024



Recent studies indicated GPT-4 outperforms online crowd workers in data labeling accuracy, notably workers from Amazon Mechanical Turk (MTurk). However, these studies were criticized for deviating from standard crowdsourcing practices and emphasizing individual workers' performances over the whole data-annotation process. This paper compared GPT-4 and an ethical and well-executed MTurk pipeline, with 415 workers labeling 3,177 sentence segments from 200 scholarly articles using the CODA-19 scheme. Two worker interfaces yielded 127,080 labels, which were then used to infer the final labels through eight label-aggregation algorithms. Our evaluation showed that despite best practices, MTurk pipeline's highest accuracy was 81.5%, whereas GPT-4 achieved 83.6%. Interestingly, when combining GPT-4's labels with crowd labels collected via an advanced worker interface for aggregation, 2 out of the 8 algorithms achieved an even higher accuracy (87.5%, 87.0%). Further analysis suggested that, when the crowd's and GPT-4's labeling strengths are complementary, aggregating them could increase labeling accuracy.
CODA-19: Reliably Annotating Research Aspects on 10,000+ CORD-19 Abstracts Using a Non-Expert Crowd
May 20, 2020
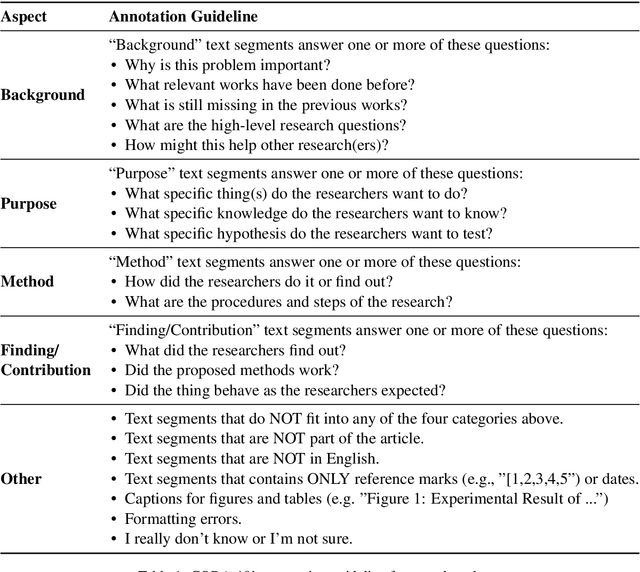


This paper introduces CODA-19, a human-annotated dataset that codes the Background, Purpose, Method, Finding/Contribution, and Other sections of 10,966 English abstracts in the COVID-19 Open Research Dataset. CODA-19 was created by 248 crowd workers from Amazon Mechanical Turk within 10 days, achieving a label quality comparable to that of experts. Each abstract was annotated by nine different workers, and the final labels were obtained by majority vote. The inter-annotator agreement (Cohen's kappa) between the crowd and the biomedical expert (0.741) is comparable to inter-expert agreement (0.788). CODA-19's labels have an accuracy of 82.2% when compared to the biomedical expert's labels, while the accuracy between experts was 85.0%. Reliable human annotations help scientists to understand the rapidly accelerating coronavirus literature and also serve as the battery of AI/NLP research, but obtaining expert annotations can be slow. We demonstrated that a non-expert crowd can be rapidly employed at scale to join the fight against COVID-19.