 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFive Years of SciCap: What We Learned and Future Directions for Scientific Figure Captioning
Dec 25, 2025Between 2021 and 2025, the SciCap project grew from a small seed-funded idea at The Pennsylvania State University (Penn State) into one of the central efforts shaping the scientific figure-captioning landscape. Supported by a Penn State seed grant, Adobe, and the Alfred P. Sloan Foundation, what began as our attempt to test whether domain-specific training, which was successful in text models like SciBERT, could also work for figure captions expanded into a multi-institution collaboration. Over these five years, we curated, released, and continually updated a large collection of figure-caption pairs from arXiv papers, conducted extensive automatic and human evaluations on both generated and author-written captions, navigated the rapid rise of large language models (LLMs), launched annual challenges, and built interactive systems that help scientists write better captions. In this piece, we look back at the first five years of SciCap and summarize the key technical and methodological lessons we learned. We then outline five major unsolved challenges and propose directions for the next phase of research in scientific figure captioning.
Investigating Pedagogical Teacher and Student LLM Agents: Genetic Adaptation Meets Retrieval Augmented Generation Across Learning Style
May 25, 2025Effective teaching requires adapting instructional strategies to accommodate the diverse cognitive and behavioral profiles of students, a persistent challenge in education and teacher training. While Large Language Models (LLMs) offer promise as tools to simulate such complex pedagogical environments, current simulation frameworks are limited in two key respects: (1) they often reduce students to static knowledge profiles, and (2) they lack adaptive mechanisms for modeling teachers who evolve their strategies in response to student feedback. To address these gaps, \textbf{we introduce a novel simulation framework that integrates LLM-based heterogeneous student agents with a self-optimizing teacher agent}. The teacher agent's pedagogical policy is dynamically evolved using a genetic algorithm, allowing it to discover and refine effective teaching strategies based on the aggregate performance of diverse learners. In addition, \textbf{we propose Persona-RAG}, a Retrieval Augmented Generation module that enables student agents to retrieve knowledge tailored to their individual learning styles. Persona-RAG preserves the retrieval accuracy of standard RAG baselines while enhancing personalization, an essential factor in modeling realistic educational scenarios. Through extensive experiments, we demonstrate how our framework supports the emergence of distinct and interpretable teaching patterns when interacting with varied student populations. Our results highlight the potential of LLM-driven simulations to inform adaptive teaching practices and provide a testbed for training human educators in controlled, data-driven environments.
Do Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SCICAP Challenge 2023
Jan 31, 2025
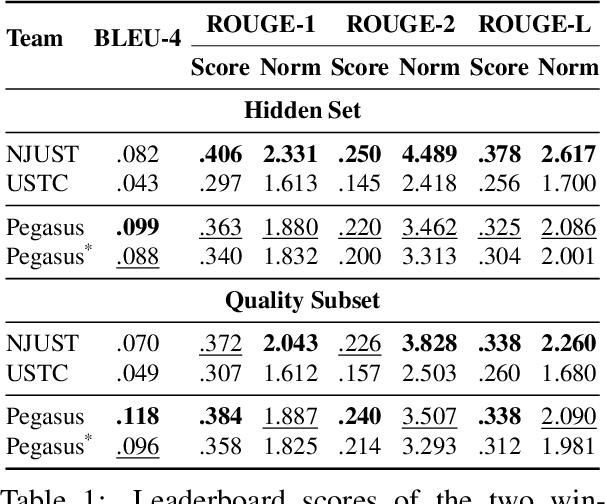
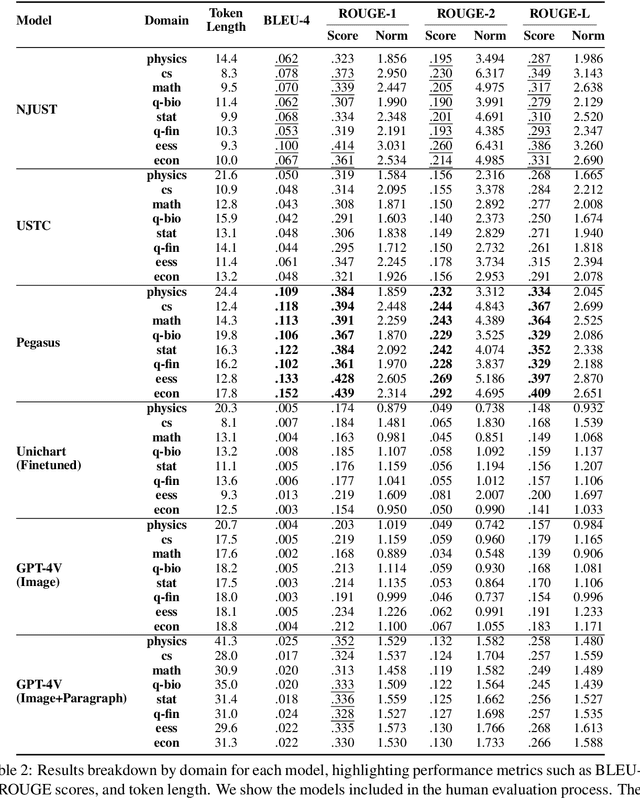
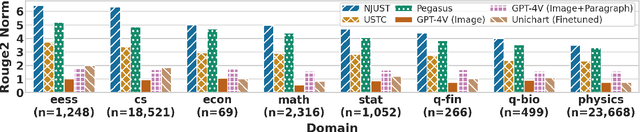
Since the SCICAP datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SCICAP Challenge took place, inviting global teams to use an expanded SCICAP dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SCICAP Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?
PseudoSeer: a Search Engine for Pseudocode
Nov 19, 2024A novel pseudocode search engine is designed to facilitate efficient retrieval and search of academic papers containing pseudocode. By leveraging Elasticsearch, the system enables users to search across various facets of a paper, such as the title, abstract, author information, and LaTeX code snippets, while supporting advanced features like combined facet searches and exact-match queries for more targeted results. A description of the data acquisition process is provided, with arXiv as the primary data source, along with methods for data extraction and text-based indexing, highlighting how different data elements are stored and optimized for search. A weighted BM25-based ranking algorithm is used by the search engine, and factors considered when prioritizing search results for both single and combined facet searches are described. We explain how each facet is weighted in a combined search. Several search engine results pages are displayed. Finally, there is a brief overview of future work and potential evaluation methodology for assessing the effectiveness and performance of the search engine is described.
Cognitive LLMs: Towards Integrating Cognitive Architectures and Large Language Models for Manufacturing Decision-making
Aug 17, 2024



Resolving the dichotomy between the human-like yet constrained reasoning processes of Cognitive Architectures and the broad but often noisy inference behavior of Large Language Models (LLMs) remains a challenging but exciting pursuit, for enabling reliable machine reasoning capabilities in production systems. Because Cognitive Architectures are famously developed for the purpose of modeling the internal mechanisms of human cognitive decision-making at a computational level, new investigations consider the goal of informing LLMs with the knowledge necessary for replicating such processes, e.g., guided perception, memory, goal-setting, and action. Previous approaches that use LLMs for grounded decision-making struggle with complex reasoning tasks that require slower, deliberate cognition over fast and intuitive inference -- reporting issues related to the lack of sufficient grounding, as in hallucination. To resolve these challenges, we introduce LLM-ACTR, a novel neuro-symbolic architecture that provides human-aligned and versatile decision-making by integrating the ACT-R Cognitive Architecture with LLMs. Our framework extracts and embeds knowledge of ACT-R's internal decision-making process as latent neural representations, injects this information into trainable LLM adapter layers, and fine-tunes the LLMs for downstream prediction. Our experiments on novel Design for Manufacturing tasks show both improved task performance as well as improved grounded decision-making capability of our approach, compared to LLM-only baselines that leverage chain-of-thought reasoning strategies.
Scaling Automatic Extraction of Pseudocode
Jun 07, 2024Pseudocode in a scholarly paper provides a concise way to express the algorithms implemented therein. Pseudocode can also be thought of as an intermediary representation that helps bridge the gap between programming languages and natural languages. Having access to a large collection of pseudocode can provide various benefits ranging from enhancing algorithmic understanding, facilitating further algorithmic design, to empowering NLP or computer vision based models for tasks such as automated code generation and optical character recognition (OCR). We have created a large pseudocode collection by extracting nearly 320,000 pseudocode examples from arXiv papers. This process involved scanning over $2.2$ million scholarly papers, with 1,000 of them being manually inspected and labeled. Our approach encompasses an extraction mechanism tailored to optimize the coverage and a validation mechanism based on random sampling to check its accuracy and reliability, given the inherent heterogeneity of the collection. In addition, we offer insights into common pseudocode structures, supported by clustering and statistical analyses. Notably, these analyses indicate an exponential-like growth in the usage of pseudocodes, highlighting their increasing significance.
Investigating Symbolic Capabilities of Large Language Models
May 21, 2024Prompting techniques have significantly enhanced the capabilities of Large Language Models (LLMs) across various complex tasks, including reasoning, planning, and solving math word problems. However, most research has predominantly focused on language-based reasoning and word problems, often overlooking the potential of LLMs in handling symbol-based calculations and reasoning. This study aims to bridge this gap by rigorously evaluating LLMs on a series of symbolic tasks, such as addition, multiplication, modulus arithmetic, numerical precision, and symbolic counting. Our analysis encompasses eight LLMs, including four enterprise-grade and four open-source models, of which three have been pre-trained on mathematical tasks. The assessment framework is anchored in Chomsky's Hierarchy, providing a robust measure of the computational abilities of these models. The evaluation employs minimally explained prompts alongside the zero-shot Chain of Thoughts technique, allowing models to navigate the solution process autonomously. The findings reveal a significant decline in LLMs' performance on context-free and context-sensitive symbolic tasks as the complexity, represented by the number of symbols, increases. Notably, even the fine-tuned GPT3.5 exhibits only marginal improvements, mirroring the performance trends observed in other models. Across the board, all models demonstrated a limited generalization ability on these symbol-intensive tasks. This research underscores LLMs' challenges with increasing symbolic complexity and highlights the need for specialized training, memory and architectural adjustments to enhance their proficiency in symbol-based reasoning tasks.
SciCapenter: Supporting Caption Composition for Scientific Figures with Machine-Generated Captions and Ratings
Mar 26, 2024
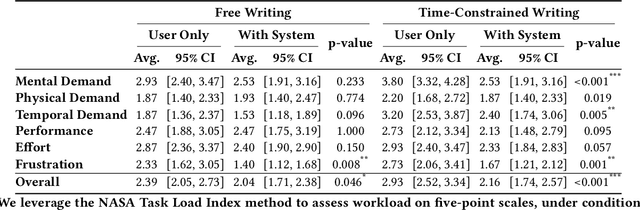

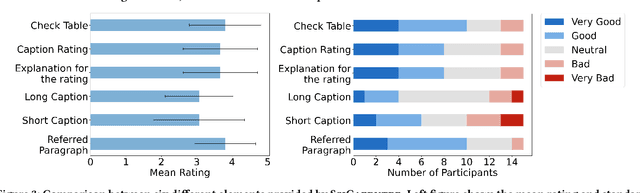
Crafting effective captions for figures is important. Readers heavily depend on these captions to grasp the figure's message. However, despite a well-developed set of AI technologies for figures and captions, these have rarely been tested for usefulness in aiding caption writing. This paper introduces SciCapenter, an interactive system that puts together cutting-edge AI technologies for scientific figure captions to aid caption composition. SciCapenter generates a variety of captions for each figure in a scholarly article, providing scores and a comprehensive checklist to assess caption quality across multiple critical aspects, such as helpfulness, OCR mention, key takeaways, and visual properties reference. Users can directly edit captions in SciCapenter, resubmit for revised evaluations, and iteratively refine them. A user study with Ph.D. students indicates that SciCapenter significantly lowers the cognitive load of caption writing. Participants' feedback further offers valuable design insights for future systems aiming to enhance caption writing.
Automated Detection and Analysis of Data Practices Using A Real-World Corpus
Feb 16, 2024



Privacy policies are crucial for informing users about data practices, yet their length and complexity often deter users from reading them. In this paper, we propose an automated approach to identify and visualize data practices within privacy policies at different levels of detail. Leveraging crowd-sourced annotations from the ToS;DR platform, we experiment with various methods to match policy excerpts with predefined data practice descriptions. We further conduct a case study to evaluate our approach on a real-world policy, demonstrating its effectiveness in simplifying complex policies. Experiments show that our approach accurately matches data practice descriptions with policy excerpts, facilitating the presentation of simplified privacy information to users.
Stability Analysis of Various Symbolic Rule Extraction Methods from Recurrent Neural Network
Feb 04, 2024This paper analyzes two competing rule extraction methodologies: quantization and equivalence query. We trained $3600$ RNN models, extracting $18000$ DFA with a quantization approach (k-means and SOM) and $3600$ DFA by equivalence query($L^{*}$) methods across $10$ initialization seeds. We sampled the datasets from $7$ Tomita and $4$ Dyck grammars and trained them on $4$ RNN cells: LSTM, GRU, O2RNN, and MIRNN. The observations from our experiments establish the superior performance of O2RNN and quantization-based rule extraction over others. $L^{*}$, primarily proposed for regular grammars, performs similarly to quantization methods for Tomita languages when neural networks are perfectly trained. However, for partially trained RNNs, $L^{*}$ shows instability in the number of states in DFA, e.g., for Tomita 5 and Tomita 6 languages, $L^{*}$ produced more than $100$ states. In contrast, quantization methods result in rules with number of states very close to ground truth DFA. Among RNN cells, O2RNN produces stable DFA consistently compared to other cells. For Dyck Languages, we observe that although GRU outperforms other RNNs in network performance, the DFA extracted by O2RNN has higher performance and better stability. The stability is computed as the standard deviation of accuracy on test sets on networks trained across $10$ seeds. On Dyck Languages, quantization methods outperformed $L^{*}$ with better stability in accuracy and the number of states. $L^{*}$ often showed instability in accuracy in the order of $16\% - 22\%$ for GRU and MIRNN while deviation for quantization methods varied in $5\% - 15\%$. In many instances with LSTM and GRU, DFA's extracted by $L^{*}$ even failed to beat chance accuracy ($50\%$), while those extracted by quantization method had standard deviation in the $7\%-17\%$ range. For O2RNN, both rule extraction methods had deviation in the $0.5\% - 3\%$ range.