 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllusions of the Gold Standard: A Large-scale Analysis of Human Evaluation Protocols for Long-form Text Generation
Jun 09, 2026Human evaluation plays a critical role in assessing the quality of generated text. However, the reliability and reproducibility of these evaluations depend on transparent and well-documented protocols -- details that are frequently missing in current practice. In this work, we conduct a large-scale analysis of human evaluation protocols for evaluating long-form generation tasks in *CL conference publications from 2023--2025, including a full manual review of 284 papers and LLM-assisted analysis for another 1.8k+ papers. We define a set of 20 reportable criteria related to reproducibility of human evaluation studies, and apply these criteria to systematically examine reporting norms and practices within the community. We find widespread under-reporting of important aspects of human evaluation study design, leading to ambiguity about what was measured and how, who contributed judgments, and how judgments should be interpreted. Based on these findings, we outline actionable recommendations to support more transparent and reproducible reporting in future research. Our analysis code and annotated dataset can be found at: https://github.com/larchlab/Illusions-of-the-Gold-Standard
Leveraging Hierarchical Organization for Medical Multi-document Summarization
Oct 27, 2025Medical multi-document summarization (MDS) is a complex task that requires effectively managing cross-document relationships. This paper investigates whether incorporating hierarchical structures in the inputs of MDS can improve a model's ability to organize and contextualize information across documents compared to traditional flat summarization methods. We investigate two ways of incorporating hierarchical organization across three large language models (LLMs), and conduct comprehensive evaluations of the resulting summaries using automated metrics, model-based metrics, and domain expert evaluation of preference, understandability, clarity, complexity, relevance, coverage, factuality, and coherence. Our results show that human experts prefer model-generated summaries over human-written summaries. Hierarchical approaches generally preserve factuality, coverage, and coherence of information, while also increasing human preference for summaries. Additionally, we examine whether simulated judgments from GPT-4 align with human judgments, finding higher agreement along more objective evaluation facets. Our findings demonstrate that hierarchical structures can improve the clarity of medical summaries generated by models while maintaining content coverage, providing a practical way to improve human preference for generated summaries.
Do Large Multimodal Models Solve Caption Generation for Scientific Figures? Lessons Learned from SCICAP Challenge 2023
Jan 31, 2025
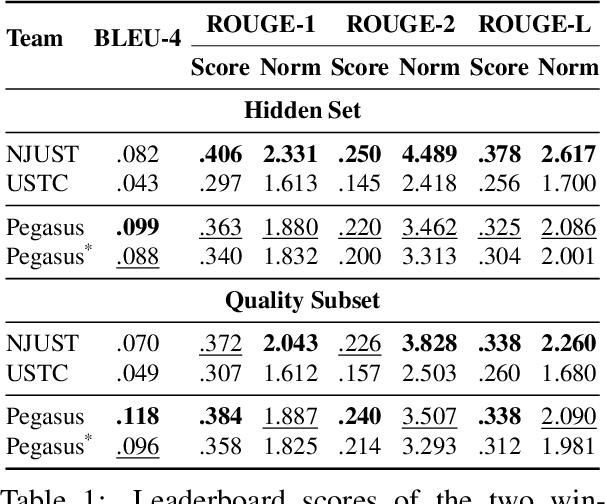
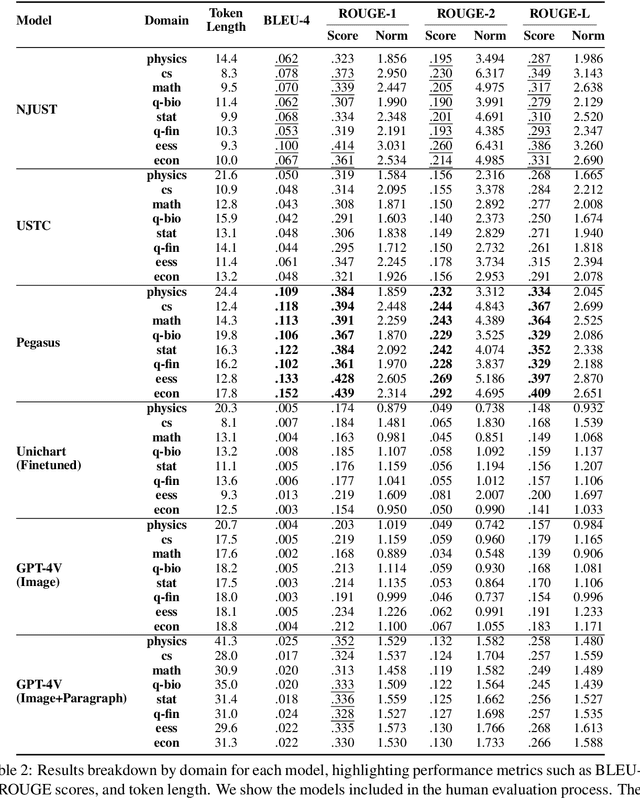
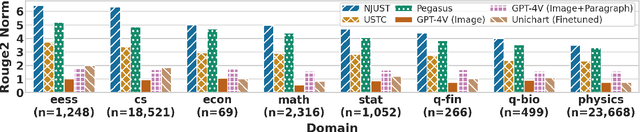
Since the SCICAP datasets launch in 2021, the research community has made significant progress in generating captions for scientific figures in scholarly articles. In 2023, the first SCICAP Challenge took place, inviting global teams to use an expanded SCICAP dataset to develop models for captioning diverse figure types across various academic fields. At the same time, text generation models advanced quickly, with many powerful pre-trained large multimodal models (LMMs) emerging that showed impressive capabilities in various vision-and-language tasks. This paper presents an overview of the first SCICAP Challenge and details the performance of various models on its data, capturing a snapshot of the fields state. We found that professional editors overwhelmingly preferred figure captions generated by GPT-4V over those from all other models and even the original captions written by authors. Following this key finding, we conducted detailed analyses to answer this question: Have advanced LMMs solved the task of generating captions for scientific figures?
Is Explanation the Cure? Misinformation Mitigation in the Short Term and Long Term
Oct 26, 2023
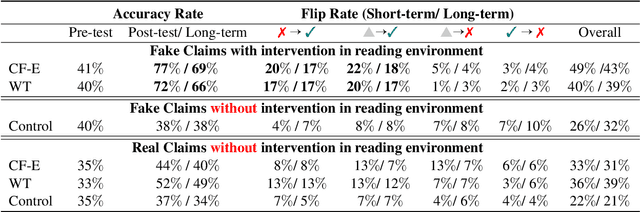
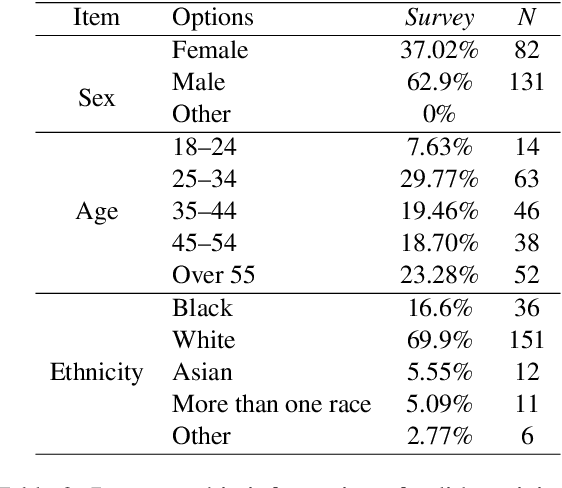
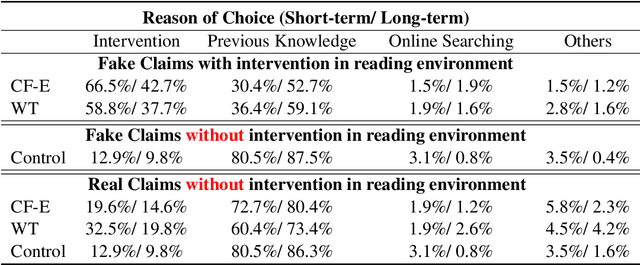
With advancements in natural language processing (NLP) models, automatic explanation generation has been proposed to mitigate misinformation on social media platforms in addition to adding warning labels to identified fake news. While many researchers have focused on generating good explanations, how these explanations can really help humans combat fake news is under-explored. In this study, we compare the effectiveness of a warning label and the state-of-the-art counterfactual explanations generated by GPT-4 in debunking misinformation. In a two-wave, online human-subject study, participants (N = 215) were randomly assigned to a control group in which false contents are shown without any intervention, a warning tag group in which the false claims were labeled, or an explanation group in which the false contents were accompanied by GPT-4 generated explanations. Our results show that both interventions significantly decrease participants' self-reported belief in fake claims in an equivalent manner for the short-term and long-term. We discuss the implications of our findings and directions for future NLP-based misinformation debunking strategies.
Label-Aware Hyperbolic Embeddings for Fine-grained Emotion Classification
Jun 26, 2023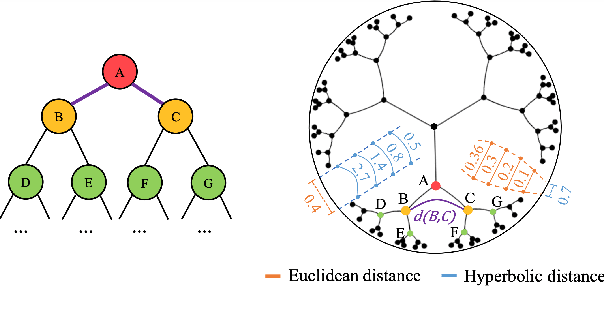
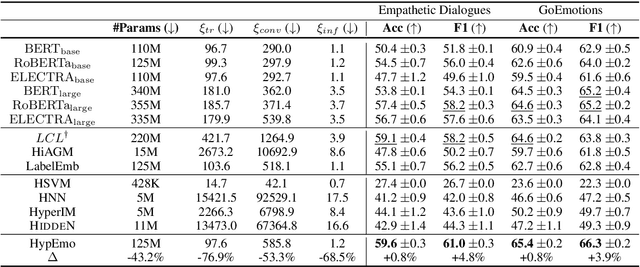
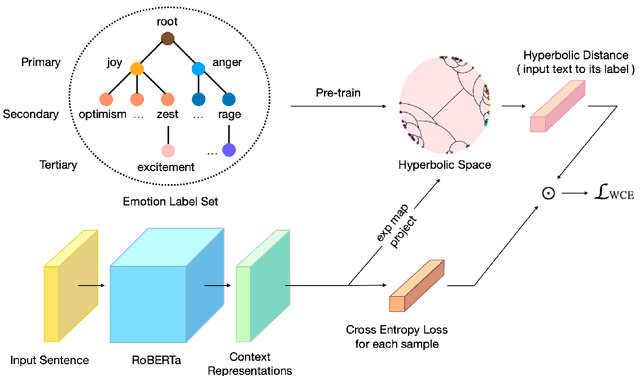
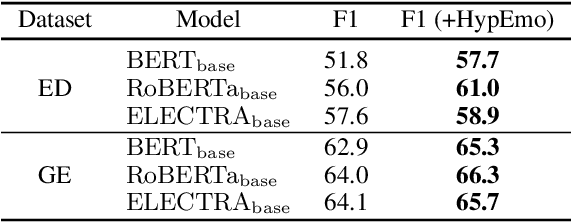
Fine-grained emotion classification (FEC) is a challenging task. Specifically, FEC needs to handle subtle nuance between labels, which can be complex and confusing. Most existing models only address text classification problem in the euclidean space, which we believe may not be the optimal solution as labels of close semantic (e.g., afraid and terrified) may not be differentiated in such space, which harms the performance. In this paper, we propose HypEmo, a novel framework that can integrate hyperbolic embeddings to improve the FEC task. First, we learn label embeddings in the hyperbolic space to better capture their hierarchical structure, and then our model projects contextualized representations to the hyperbolic space to compute the distance between samples and labels. Experimental results show that incorporating such distance to weight cross entropy loss substantially improves the performance with significantly higher efficiency. We evaluate our proposed model on two benchmark datasets and found 4.8% relative improvement compared to the previous state of the art with 43.2% fewer parameters and 76.9% less training time. Code is available at https: //github.com/dinobby/HypEmo.
Ask to Know More: Generating Counterfactual Explanations for Fake Claims
Jun 14, 2022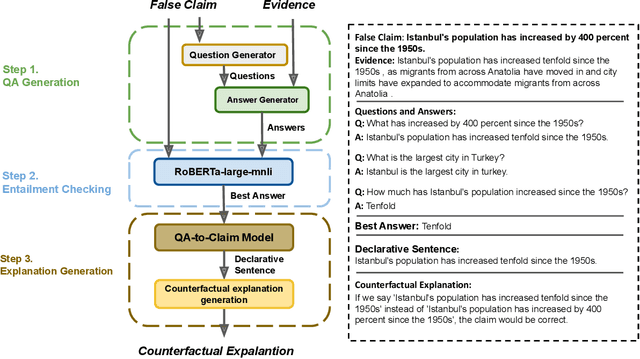
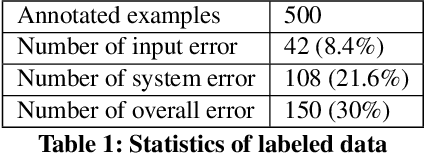
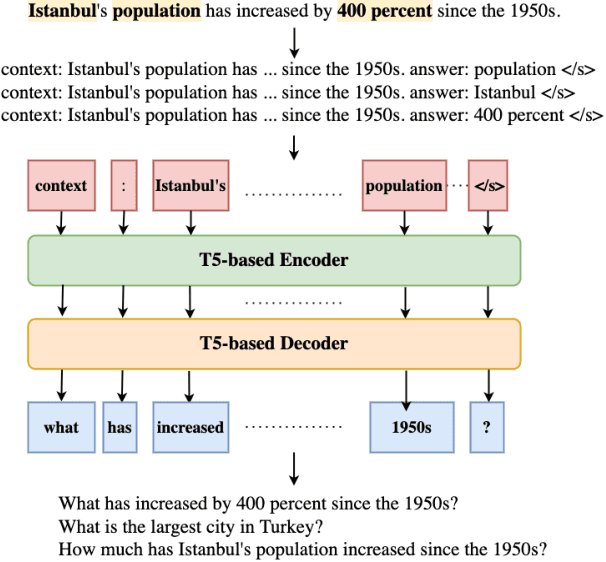
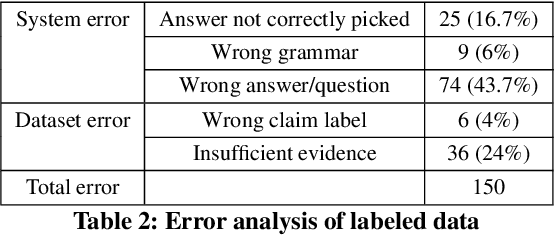
Automated fact checking systems have been proposed that quickly provide veracity prediction at scale to mitigate the negative influence of fake news on people and on public opinion. However, most studies focus on veracity classifiers of those systems, which merely predict the truthfulness of news articles. We posit that effective fact checking also relies on people's understanding of the predictions. In this paper, we propose elucidating fact checking predictions using counterfactual explanations to help people understand why a specific piece of news was identified as fake. In this work, generating counterfactual explanations for fake news involves three steps: asking good questions, finding contradictions, and reasoning appropriately. We frame this research question as contradicted entailment reasoning through question answering (QA). We first ask questions towards the false claim and retrieve potential answers from the relevant evidence documents. Then, we identify the most contradictory answer to the false claim by use of an entailment classifier. Finally, a counterfactual explanation is created using a matched QA pair with three different counterfactual explanation forms. Experiments are conducted on the FEVER dataset for both system and human evaluations. Results suggest that the proposed approach generates the most helpful explanations compared to state-of-the-art methods.