 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study of LLM Secure Code Generation
Mar 18, 2025



LLMs are widely used in software development. However, the code generated by LLMs often contains vulnerabilities. Several secure code generation methods have been proposed to address this issue, but their current evaluation schemes leave several concerns unaddressed. Specifically, most existing studies evaluate security and functional correctness separately, using different datasets. That is, they assess vulnerabilities using security-related code datasets while validating functionality with general code datasets. In addition, prior research primarily relies on a single static analyzer, CodeQL, to detect vulnerabilities in generated code, which limits the scope of security evaluation. In this work, we conduct a comprehensive study to systematically assess the improvements introduced by four state-of-the-art secure code generation techniques. Specifically, we apply both security inspection and functionality validation to the same generated code and evaluate these two aspects together. We also employ three popular static analyzers and two LLMs to identify potential vulnerabilities in the generated code. Our study reveals that existing techniques often compromise the functionality of generated code to enhance security. Their overall performance remains limited when evaluating security and functionality together. In fact, many techniques even degrade the performance of the base LLM. Our further inspection reveals that these techniques often either remove vulnerable lines of code entirely or generate ``garbage code'' that is unrelated to the intended task. Moreover, the commonly used static analyzer CodeQL fails to detect several vulnerabilities, further obscuring the actual security improvements achieved by existing techniques. Our study serves as a guideline for a more rigorous and comprehensive evaluation of secure code generation performance in future work.
Exploiting Watermark-Based Defense Mechanisms in Text-to-Image Diffusion Models for Unauthorized Data Usage
Nov 22, 2024



Text-to-image diffusion models, such as Stable Diffusion, have shown exceptional potential in generating high-quality images. However, recent studies highlight concerns over the use of unauthorized data in training these models, which may lead to intellectual property infringement or privacy violations. A promising approach to mitigate these issues is to apply a watermark to images and subsequently check if generative models reproduce similar watermark features. In this paper, we examine the robustness of various watermark-based protection methods applied to text-to-image models. We observe that common image transformations are ineffective at removing the watermark effect. Therefore, we propose \tech{}, that leverages the diffusion process to conduct controlled image generation on the protected input, preserving the high-level features of the input while ignoring the low-level details utilized by watermarks. A small number of generated images are then used to fine-tune protected models. Our experiments on three datasets and 140 text-to-image diffusion models reveal that existing state-of-the-art protections are not robust against RATTAN.
Is Explanation the Cure? Misinformation Mitigation in the Short Term and Long Term
Oct 26, 2023
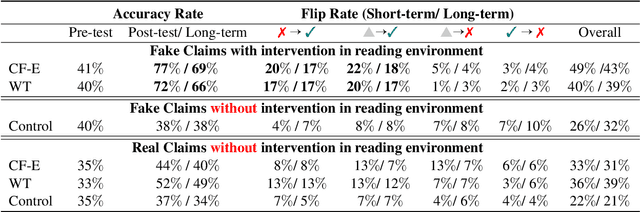
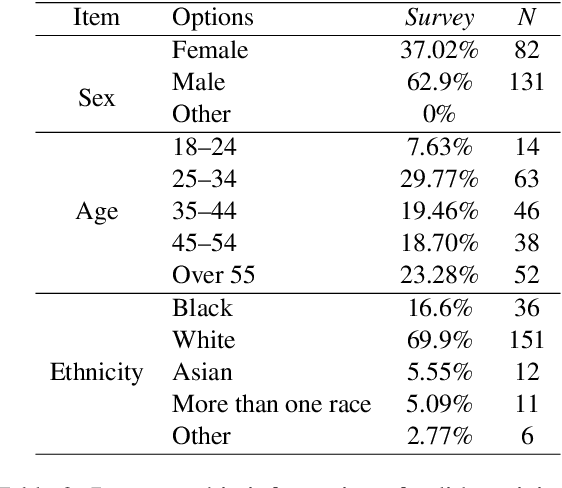
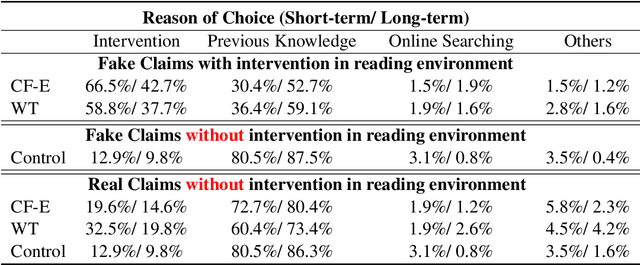
With advancements in natural language processing (NLP) models, automatic explanation generation has been proposed to mitigate misinformation on social media platforms in addition to adding warning labels to identified fake news. While many researchers have focused on generating good explanations, how these explanations can really help humans combat fake news is under-explored. In this study, we compare the effectiveness of a warning label and the state-of-the-art counterfactual explanations generated by GPT-4 in debunking misinformation. In a two-wave, online human-subject study, participants (N = 215) were randomly assigned to a control group in which false contents are shown without any intervention, a warning tag group in which the false claims were labeled, or an explanation group in which the false contents were accompanied by GPT-4 generated explanations. Our results show that both interventions significantly decrease participants' self-reported belief in fake claims in an equivalent manner for the short-term and long-term. We discuss the implications of our findings and directions for future NLP-based misinformation debunking strategies.
LLM-in-the-loop: Leveraging Large Language Model for Thematic Analysis
Oct 23, 2023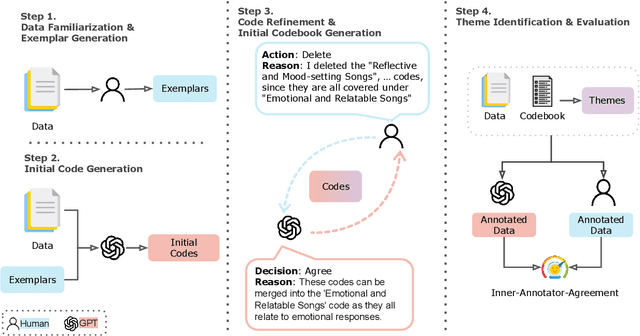


Thematic analysis (TA) has been widely used for analyzing qualitative data in many disciplines and fields. To ensure reliable analysis, the same piece of data is typically assigned to at least two human coders. Moreover, to produce meaningful and useful analysis, human coders develop and deepen their data interpretation and coding over multiple iterations, making TA labor-intensive and time-consuming. Recently the emerging field of large language models (LLMs) research has shown that LLMs have the potential replicate human-like behavior in various tasks: in particular, LLMs outperform crowd workers on text-annotation tasks, suggesting an opportunity to leverage LLMs on TA. We propose a human-LLM collaboration framework (i.e., LLM-in-the-loop) to conduct TA with in-context learning (ICL). This framework provides the prompt to frame discussions with a LLM (e.g., GPT-3.5) to generate the final codebook for TA. We demonstrate the utility of this framework using survey datasets on the aspects of the music listening experience and the usage of a password manager. Results of the two case studies show that the proposed framework yields similar coding quality to that of human coders but reduces TA's labor and time demands.
Ask to Know More: Generating Counterfactual Explanations for Fake Claims
Jun 14, 2022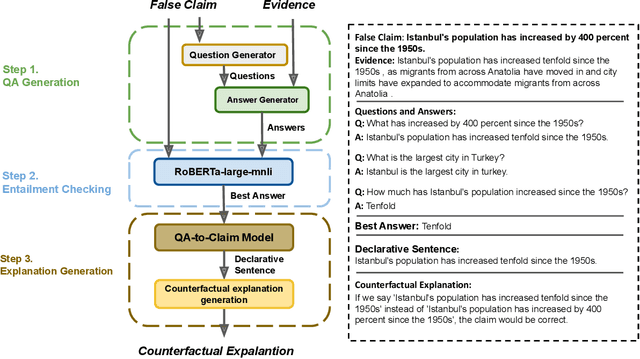
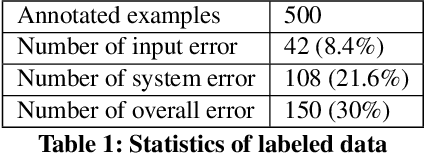
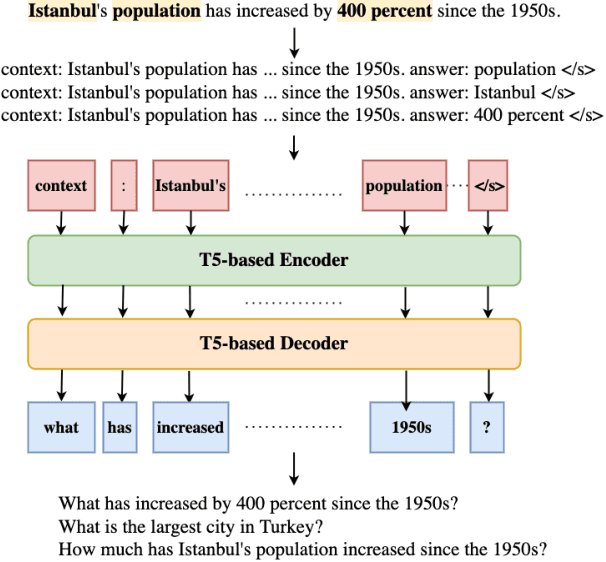
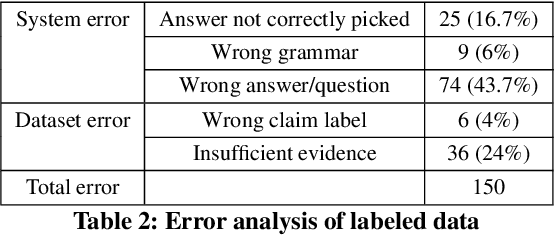
Automated fact checking systems have been proposed that quickly provide veracity prediction at scale to mitigate the negative influence of fake news on people and on public opinion. However, most studies focus on veracity classifiers of those systems, which merely predict the truthfulness of news articles. We posit that effective fact checking also relies on people's understanding of the predictions. In this paper, we propose elucidating fact checking predictions using counterfactual explanations to help people understand why a specific piece of news was identified as fake. In this work, generating counterfactual explanations for fake news involves three steps: asking good questions, finding contradictions, and reasoning appropriately. We frame this research question as contradicted entailment reasoning through question answering (QA). We first ask questions towards the false claim and retrieve potential answers from the relevant evidence documents. Then, we identify the most contradictory answer to the false claim by use of an entailment classifier. Finally, a counterfactual explanation is created using a matched QA pair with three different counterfactual explanation forms. Experiments are conducted on the FEVER dataset for both system and human evaluations. Results suggest that the proposed approach generates the most helpful explanations compared to state-of-the-art methods.