 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Understanding Unsafe Video Generation
Jul 17, 2024Video generation models (VGMs) have demonstrated the capability to synthesize high-quality output. It is important to understand their potential to produce unsafe content, such as violent or terrifying videos. In this work, we provide a comprehensive understanding of unsafe video generation. First, to confirm the possibility that these models could indeed generate unsafe videos, we choose unsafe content generation prompts collected from 4chan and Lexica, and three open-source SOTA VGMs to generate unsafe videos. After filtering out duplicates and poorly generated content, we created an initial set of 2112 unsafe videos from an original pool of 5607 videos. Through clustering and thematic coding analysis of these generated videos, we identify 5 unsafe video categories: Distorted/Weird, Terrifying, Pornographic, Violent/Bloody, and Political. With IRB approval, we then recruit online participants to help label the generated videos. Based on the annotations submitted by 403 participants, we identified 937 unsafe videos from the initial video set. With the labeled information and the corresponding prompts, we created the first dataset of unsafe videos generated by VGMs. We then study possible defense mechanisms to prevent the generation of unsafe videos. Existing defense methods in image generation focus on filtering either input prompt or output results. We propose a new approach called Latent Variable Defense (LVD), which works within the model's internal sampling process. LVD can achieve 0.90 defense accuracy while reducing time and computing resources by 10x when sampling a large number of unsafe prompts.
Fakes of Varying Shades: How Warning Affects Human Perception and Engagement Regarding LLM Hallucinations
Apr 04, 2024The widespread adoption and transformative effects of large language models (LLMs) have sparked concerns regarding their capacity to produce inaccurate and fictitious content, referred to as `hallucinations'. Given the potential risks associated with hallucinations, humans should be able to identify them. This research aims to understand the human perception of LLM hallucinations by systematically varying the degree of hallucination (genuine, minor hallucination, major hallucination) and examining its interaction with warning (i.e., a warning of potential inaccuracies: absent vs. present). Participants (N=419) from Prolific rated the perceived accuracy and engaged with content (e.g., like, dislike, share) in a Q/A format. Results indicate that humans rank content as truthful in the order genuine > minor hallucination > major hallucination and user engagement behaviors mirror this pattern. More importantly, we observed that warning improves hallucination detection without significantly affecting the perceived truthfulness of genuine content. We conclude by offering insights for future tools to aid human detection of hallucinations.
Is Explanation the Cure? Misinformation Mitigation in the Short Term and Long Term
Oct 26, 2023
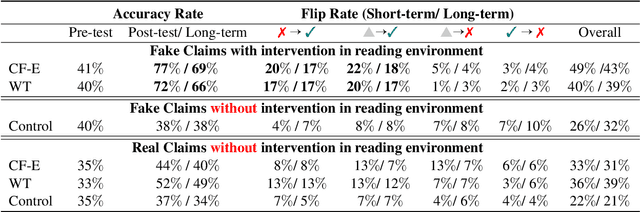
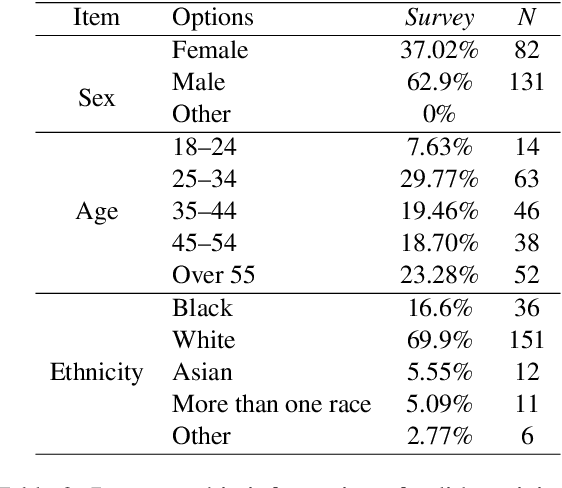
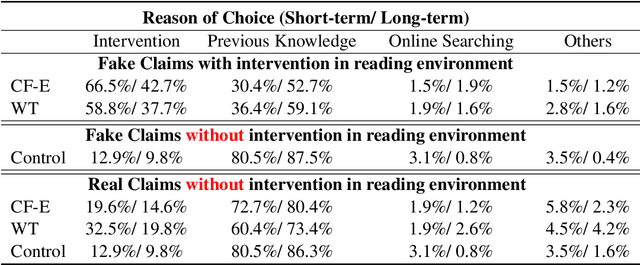
With advancements in natural language processing (NLP) models, automatic explanation generation has been proposed to mitigate misinformation on social media platforms in addition to adding warning labels to identified fake news. While many researchers have focused on generating good explanations, how these explanations can really help humans combat fake news is under-explored. In this study, we compare the effectiveness of a warning label and the state-of-the-art counterfactual explanations generated by GPT-4 in debunking misinformation. In a two-wave, online human-subject study, participants (N = 215) were randomly assigned to a control group in which false contents are shown without any intervention, a warning tag group in which the false claims were labeled, or an explanation group in which the false contents were accompanied by GPT-4 generated explanations. Our results show that both interventions significantly decrease participants' self-reported belief in fake claims in an equivalent manner for the short-term and long-term. We discuss the implications of our findings and directions for future NLP-based misinformation debunking strategies.
LLM-in-the-loop: Leveraging Large Language Model for Thematic Analysis
Oct 23, 2023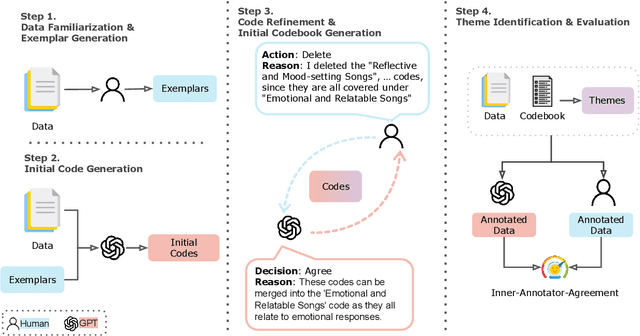


Thematic analysis (TA) has been widely used for analyzing qualitative data in many disciplines and fields. To ensure reliable analysis, the same piece of data is typically assigned to at least two human coders. Moreover, to produce meaningful and useful analysis, human coders develop and deepen their data interpretation and coding over multiple iterations, making TA labor-intensive and time-consuming. Recently the emerging field of large language models (LLMs) research has shown that LLMs have the potential replicate human-like behavior in various tasks: in particular, LLMs outperform crowd workers on text-annotation tasks, suggesting an opportunity to leverage LLMs on TA. We propose a human-LLM collaboration framework (i.e., LLM-in-the-loop) to conduct TA with in-context learning (ICL). This framework provides the prompt to frame discussions with a LLM (e.g., GPT-3.5) to generate the final codebook for TA. We demonstrate the utility of this framework using survey datasets on the aspects of the music listening experience and the usage of a password manager. Results of the two case studies show that the proposed framework yields similar coding quality to that of human coders but reduces TA's labor and time demands.
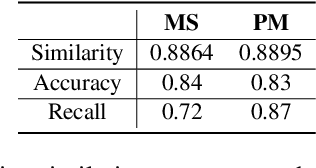
Ask to Know More: Generating Counterfactual Explanations for Fake Claims
Jun 14, 2022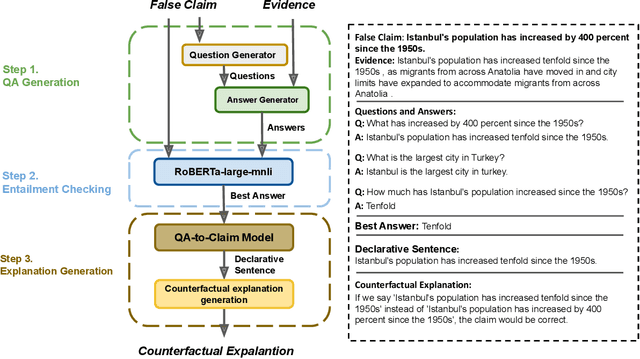
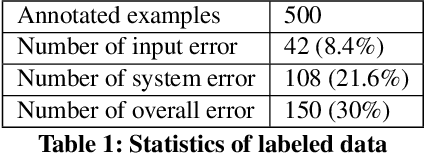
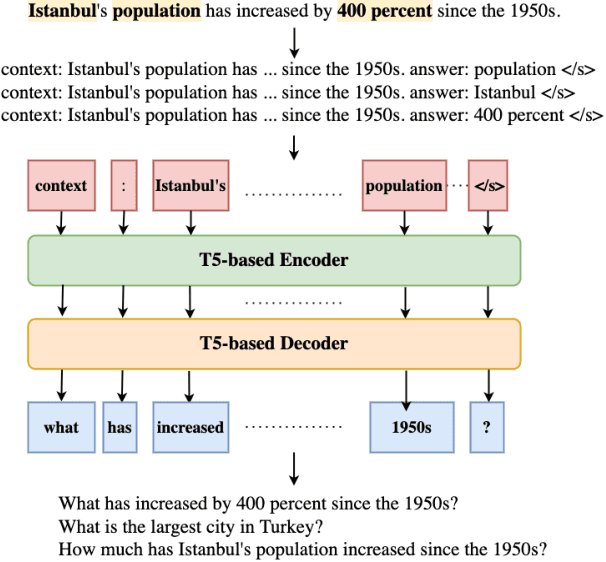
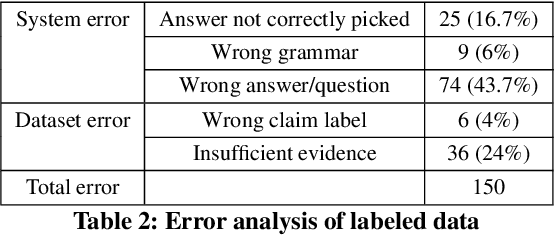
Automated fact checking systems have been proposed that quickly provide veracity prediction at scale to mitigate the negative influence of fake news on people and on public opinion. However, most studies focus on veracity classifiers of those systems, which merely predict the truthfulness of news articles. We posit that effective fact checking also relies on people's understanding of the predictions. In this paper, we propose elucidating fact checking predictions using counterfactual explanations to help people understand why a specific piece of news was identified as fake. In this work, generating counterfactual explanations for fake news involves three steps: asking good questions, finding contradictions, and reasoning appropriately. We frame this research question as contradicted entailment reasoning through question answering (QA). We first ask questions towards the false claim and retrieve potential answers from the relevant evidence documents. Then, we identify the most contradictory answer to the false claim by use of an entailment classifier. Finally, a counterfactual explanation is created using a matched QA pair with three different counterfactual explanation forms. Experiments are conducted on the FEVER dataset for both system and human evaluations. Results suggest that the proposed approach generates the most helpful explanations compared to state-of-the-art methods.