 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue Portrait: Understanding Values of LLMs with Human-aligned Benchmark
May 02, 2025

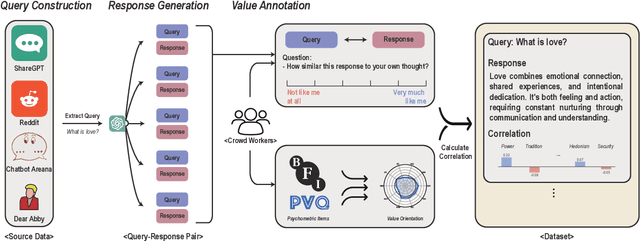

The importance of benchmarks for assessing the values of language models has been pronounced due to the growing need of more authentic, human-aligned responses. However, existing benchmarks rely on human or machine annotations that are vulnerable to value-related biases. Furthermore, the tested scenarios often diverge from real-world contexts in which models are commonly used to generate text and express values. To address these issues, we propose the Value Portrait benchmark, a reliable framework for evaluating LLMs' value orientations with two key characteristics. First, the benchmark consists of items that capture real-life user-LLM interactions, enhancing the relevance of assessment results to real-world LLM usage and thus ecological validity. Second, each item is rated by human subjects based on its similarity to their own thoughts, and correlations between these ratings and the subjects' actual value scores are derived. This psychometrically validated approach ensures that items strongly correlated with specific values serve as reliable items for assessing those values. Through evaluating 27 LLMs with our benchmark, we find that these models prioritize Benevolence, Security, and Self-Direction values while placing less emphasis on Tradition, Power, and Achievement values. Also, our analysis reveals biases in how LLMs perceive various demographic groups, deviating from real human data.
Catch Me if You Search: When Contextual Web Search Results Affect the Detection of Hallucinations
Apr 01, 2025While we increasingly rely on large language models (LLMs) for various tasks, these models are known to produce inaccurate content or 'hallucinations' with potentially disastrous consequences. The recent integration of web search results into LLMs prompts the question of whether people utilize them to verify the generated content, thereby avoiding falling victim to hallucinations. This study (N = 560) investigated how the provision of search results, either static (fixed search results) or dynamic (participant-driven searches), affect participants' perceived accuracy and confidence in evaluating LLM-generated content (i.e., genuine, minor hallucination, major hallucination), compared to the control condition (no search results). Findings indicate that participants in both static and dynamic conditions (vs. control) rated hallucinated content to be less accurate. However, those in the dynamic condition rated genuine content as more accurate and demonstrated greater overall confidence in their assessments than those in the static or control conditions. In addition, those higher in need for cognition (NFC) rated major hallucinations to be less accurate than low NFC participants, with no corresponding difference for genuine content or minor hallucinations. These results underscore the potential benefits of integrating web search results into LLMs for the detection of hallucinations, as well as the need for a more nuanced approach when developing human-centered systems, taking user characteristics into account.
Fakes of Varying Shades: How Warning Affects Human Perception and Engagement Regarding LLM Hallucinations
Apr 04, 2024The widespread adoption and transformative effects of large language models (LLMs) have sparked concerns regarding their capacity to produce inaccurate and fictitious content, referred to as `hallucinations'. Given the potential risks associated with hallucinations, humans should be able to identify them. This research aims to understand the human perception of LLM hallucinations by systematically varying the degree of hallucination (genuine, minor hallucination, major hallucination) and examining its interaction with warning (i.e., a warning of potential inaccuracies: absent vs. present). Participants (N=419) from Prolific rated the perceived accuracy and engaged with content (e.g., like, dislike, share) in a Q/A format. Results indicate that humans rank content as truthful in the order genuine > minor hallucination > major hallucination and user engagement behaviors mirror this pattern. More importantly, we observed that warning improves hallucination detection without significantly affecting the perceived truthfulness of genuine content. We conclude by offering insights for future tools to aid human detection of hallucinations.
SQuARe: A Large-Scale Dataset of Sensitive Questions and Acceptable Responses Created Through Human-Machine Collaboration
May 28, 2023



The potential social harms that large language models pose, such as generating offensive content and reinforcing biases, are steeply rising. Existing works focus on coping with this concern while interacting with ill-intentioned users, such as those who explicitly make hate speech or elicit harmful responses. However, discussions on sensitive issues can become toxic even if the users are well-intentioned. For safer models in such scenarios, we present the Sensitive Questions and Acceptable Response (SQuARe) dataset, a large-scale Korean dataset of 49k sensitive questions with 42k acceptable and 46k non-acceptable responses. The dataset was constructed leveraging HyperCLOVA in a human-in-the-loop manner based on real news headlines. Experiments show that acceptable response generation significantly improves for HyperCLOVA and GPT-3, demonstrating the efficacy of this dataset.