 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hallucination Detection via Future Context
Jul 28, 2025



Large Language Models (LLMs) are widely used to generate plausible text on online platforms, without revealing the generation process. As users increasingly encounter such black-box outputs, detecting hallucinations has become a critical challenge. To address this challenge, we focus on developing a hallucination detection framework for black-box generators. Motivated by the observation that hallucinations, once introduced, tend to persist, we sample future contexts. The sampled future contexts provide valuable clues for hallucination detection and can be effectively integrated with various sampling-based methods. We extensively demonstrate performance improvements across multiple methods using our proposed sampling approach.
ArgInstruct: Specialized Instruction Fine-Tuning for Computational Argumentation
May 28, 2025Training large language models (LLMs) to follow instructions has significantly enhanced their ability to tackle unseen tasks. However, despite their strong generalization capabilities, instruction-following LLMs encounter difficulties when dealing with tasks that require domain knowledge. This work introduces a specialized instruction fine-tuning for the domain of computational argumentation (CA). The goal is to enable an LLM to effectively tackle any unseen CA tasks while preserving its generalization capabilities. Reviewing existing CA research, we crafted natural language instructions for 105 CA tasks to this end. On this basis, we developed a CA-specific benchmark for LLMs that allows for a comprehensive evaluation of LLMs' capabilities in solving various CA tasks. We synthesized 52k CA-related instructions, adapting the self-instruct process to train a CA-specialized instruction-following LLM. Our experiments suggest that CA-specialized instruction fine-tuning significantly enhances the LLM on both seen and unseen CA tasks. At the same time, performance on the general NLP tasks of the SuperNI benchmark remains stable.
ReSCORE: Label-free Iterative Retriever Training for Multi-hop Question Answering with Relevance-Consistency Supervision
May 27, 2025Multi-hop question answering (MHQA) involves reasoning across multiple documents to answer complex questions. Dense retrievers typically outperform sparse methods like BM25 by leveraging semantic embeddings; however, they require labeled query-document pairs for fine-tuning. This poses a significant challenge in MHQA due to the high variability of queries (reformulated) questions throughout the reasoning steps. To overcome this limitation, we introduce Retriever Supervision with Consistency and Relevance (ReSCORE), a novel method for training dense retrievers for MHQA without labeled documents. ReSCORE leverages large language models to capture each documents relevance to the question and consistency with the correct answer and use them to train a retriever within an iterative question-answering framework. Experiments on three MHQA benchmarks demonstrate the effectiveness of ReSCORE, with significant improvements in retrieval, and in turn, the state-of-the-art MHQA performance. Our implementation is available at: https://leeds1219.github.io/ReSCORE.
Are LLM-Judges Robust to Expressions of Uncertainty? Investigating the effect of Epistemic Markers on LLM-based Evaluation
Oct 28, 2024



In line with the principle of honesty, there has been a growing effort to train large language models (LLMs) to generate outputs containing epistemic markers. However, evaluation in the presence of epistemic markers has been largely overlooked, raising a critical question: Could the use of epistemic markers in LLM-generated outputs lead to unintended negative consequences? To address this, we present EMBER, a benchmark designed to assess the robustness of LLM-judges to epistemic markers in both single and pairwise evaluation settings. Our findings, based on evaluations using EMBER, reveal that all tested LLM-judges, including GPT-4o, show a notable lack of robustness in the presence of epistemic markers. Specifically, we observe a negative bias toward epistemic markers, with a stronger bias against markers expressing uncertainty. This suggests that LLM-judges are influenced by the presence of these markers and do not focus solely on the correctness of the content.
Investigating How Large Language Models Leverage Internal Knowledge to Perform Complex Reasoning
Jun 27, 2024



Despite significant advancements, there is a limited understanding of how large language models (LLMs) utilize knowledge for reasoning. To address this, we propose a method that deconstructs complex real-world questions into a graph, representing each question as a node with parent nodes of background knowledge needed to solve the question. We develop the DepthQA dataset, deconstructing questions into three depths: (i) recalling conceptual knowledge, (ii) applying procedural knowledge, and (iii) analyzing strategic knowledge. Based on a hierarchical graph, we quantify forward discrepancy, discrepancies in LLMs' performance on simpler sub-problems versus complex questions. We also measure backward discrepancy, where LLMs answer complex questions but struggle with simpler ones. Our analysis shows that smaller models have more discrepancies than larger models. Additionally, guiding models from simpler to complex questions through multi-turn interactions improves performance across model sizes, highlighting the importance of structured intermediate steps in knowledge reasoning. This work enhances our understanding of LLM reasoning and suggests ways to improve their problem-solving abilities.
Return of EM: Entity-driven Answer Set Expansion for QA Evaluation
Apr 24, 2024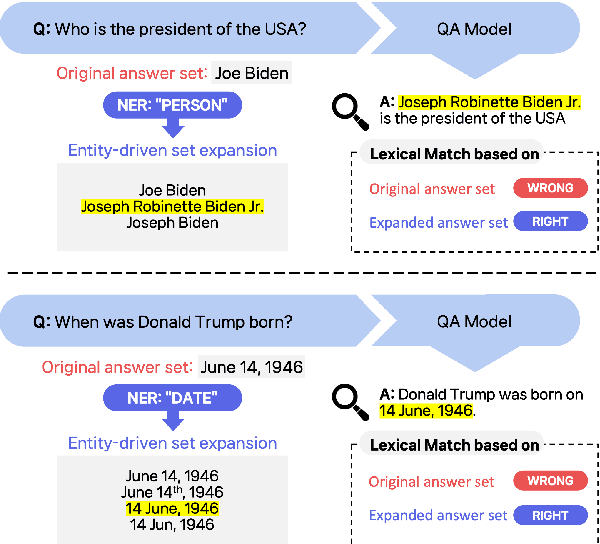
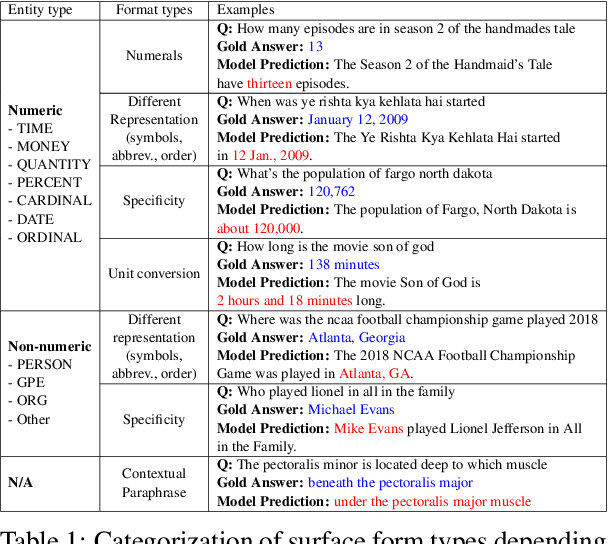
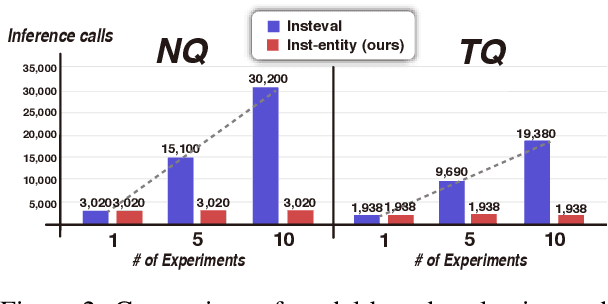
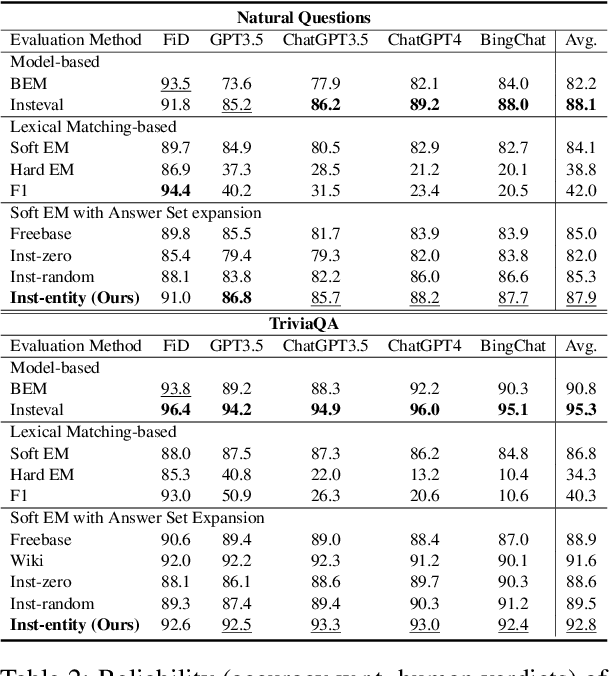
Recently, directly using large language models (LLMs) has been shown to be the most reliable method to evaluate QA models. However, it suffers from limited interpretability, high cost, and environmental harm. To address these, we propose to use soft EM with entity-driven answer set expansion. Our approach expands the gold answer set to include diverse surface forms, based on the observation that the surface forms often follow particular patterns depending on the entity type. The experimental results show that our method outperforms traditional evaluation methods by a large margin. Moreover, the reliability of our evaluation method is comparable to that of LLM-based ones, while offering the benefits of high interpretability and reduced environmental harm.
AdvisorQA: Towards Helpful and Harmless Advice-seeking Question Answering with Collective Intelligence
Apr 18, 2024
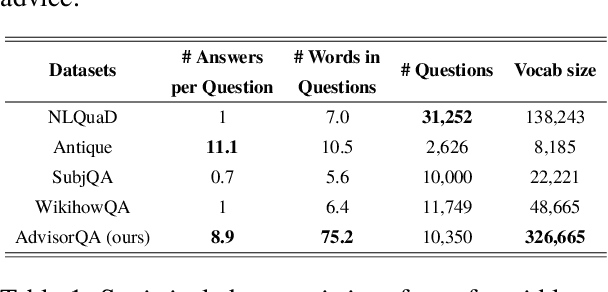
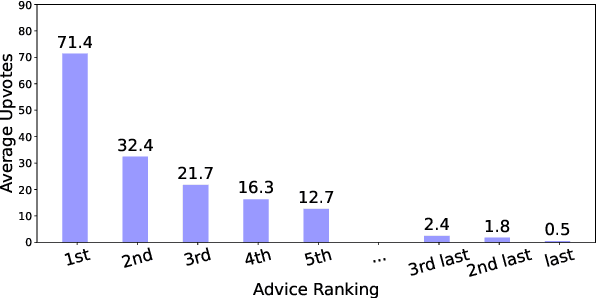

As the integration of large language models into daily life is on the rise, there is a clear gap in benchmarks for advising on subjective and personal dilemmas. To address this, we introduce AdvisorQA, the first benchmark developed to assess LLMs' capability in offering advice for deeply personalized concerns, utilizing the LifeProTips subreddit forum. This forum features a dynamic interaction where users post advice-seeking questions, receiving an average of 8.9 advice per query, with 164.2 upvotes from hundreds of users, embodying a collective intelligence framework. Therefore, we've completed a benchmark encompassing daily life questions, diverse corresponding responses, and majority vote ranking to train our helpfulness metric. Baseline experiments validate the efficacy of AdvisorQA through our helpfulness metric, GPT-4, and human evaluation, analyzing phenomena beyond the trade-off between helpfulness and harmlessness. AdvisorQA marks a significant leap in enhancing QA systems for providing personalized, empathetic advice, showcasing LLMs' improved understanding of human subjectivity.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
A Design Space for Intelligent and Interactive Writing Assistants
Mar 26, 2024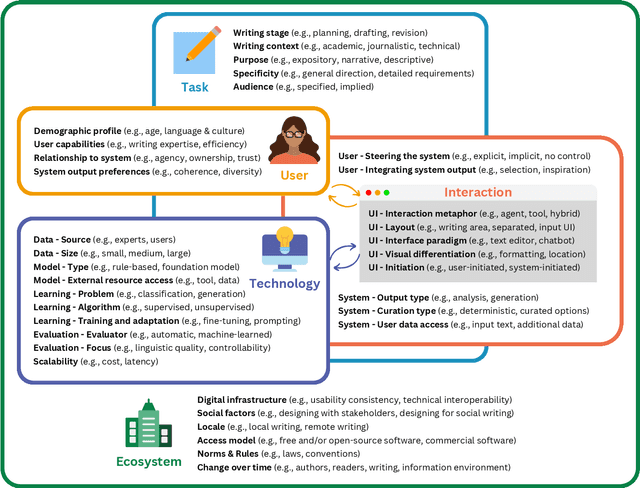
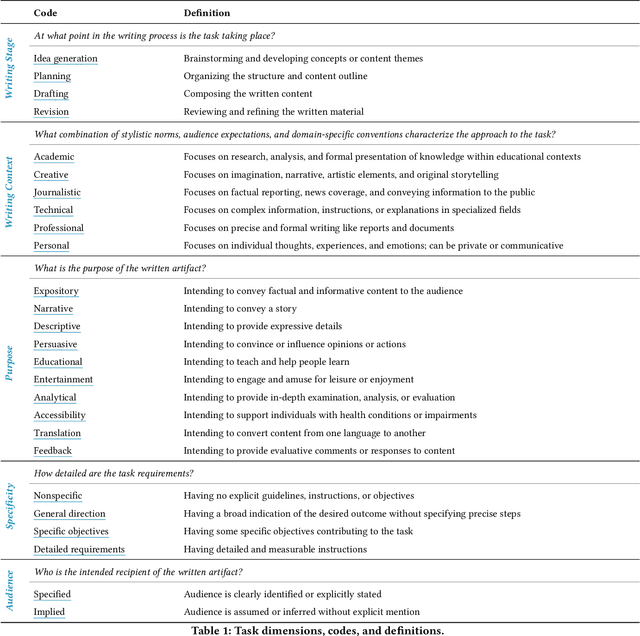
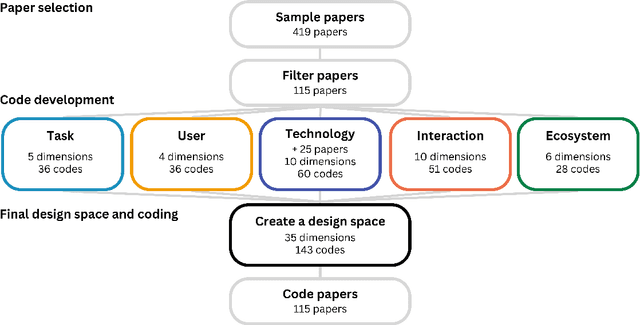
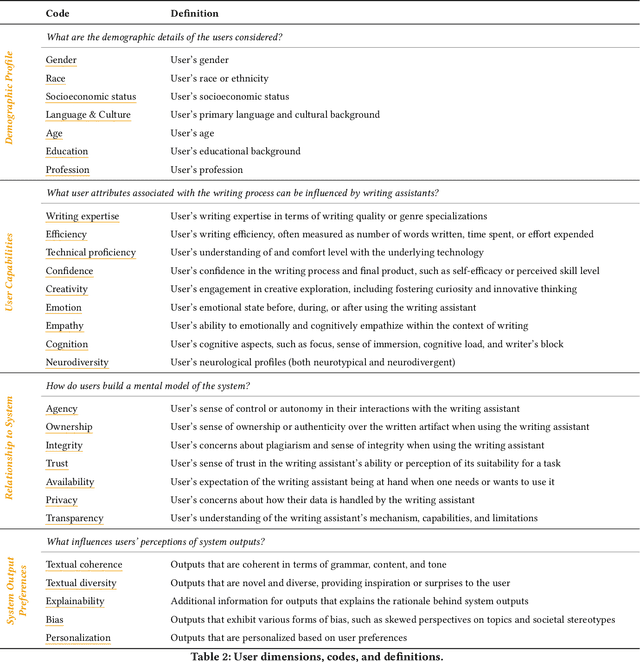
In our era of rapid technological advancement, the research landscape for writing assistants has become increasingly fragmented across various research communities. We seek to address this challenge by proposing a design space as a structured way to examine and explore the multidimensional space of intelligent and interactive writing assistants. Through a large community collaboration, we explore five aspects of writing assistants: task, user, technology, interaction, and ecosystem. Within each aspect, we define dimensions (i.e., fundamental components of an aspect) and codes (i.e., potential options for each dimension) by systematically reviewing 115 papers. Our design space aims to offer researchers and designers a practical tool to navigate, comprehend, and compare the various possibilities of writing assistants, and aid in the envisioning and design of new writing assistants.
Argument Quality Assessment in the Age of Instruction-Following Large Language Models
Mar 24, 2024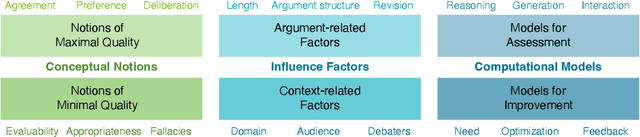

The computational treatment of arguments on controversial issues has been subject to extensive NLP research, due to its envisioned impact on opinion formation, decision making, writing education, and the like. A critical task in any such application is the assessment of an argument's quality - but it is also particularly challenging. In this position paper, we start from a brief survey of argument quality research, where we identify the diversity of quality notions and the subjectiveness of their perception as the main hurdles towards substantial progress on argument quality assessment. We argue that the capabilities of instruction-following large language models (LLMs) to leverage knowledge across contexts enable a much more reliable assessment. Rather than just fine-tuning LLMs towards leaderboard chasing on assessment tasks, they need to be instructed systematically with argumentation theories and scenarios as well as with ways to solve argument-related problems. We discuss the real-world opportunities and ethical issues emerging thereby.