 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Hallucination Detection via Future Context
Jul 28, 2025Large Language Models (LLMs) are widely used to generate plausible text on online platforms, without revealing the generation process. As users increasingly encounter such black-box outputs, detecting hallucinations has become a critical challenge. To address this challenge, we focus on developing a hallucination detection framework for black-box generators. Motivated by the observation that hallucinations, once introduced, tend to persist, we sample future contexts. The sampled future contexts provide valuable clues for hallucination detection and can be effectively integrated with various sampling-based methods. We extensively demonstrate performance improvements across multiple methods using our proposed sampling approach.
Cross-lingual Collapse: How Language-Centric Foundation Models Shape Reasoning in Large Language Models
Jun 06, 2025



We identify \textbf{Cross-lingual Collapse}, a systematic drift in which the chain-of-thought (CoT) of a multilingual language model reverts to its dominant pre-training language even when the prompt is expressed in a different language. Recent large language models (LLMs) with reinforcement learning with verifiable reward (RLVR) have achieved strong logical reasoning performances by exposing their intermediate reasoning traces, giving rise to large reasoning models (LRMs). However, the mechanism behind multilingual reasoning in LRMs is not yet fully explored. To investigate the issue, we fine-tune multilingual LRMs with Group-Relative Policy Optimization (GRPO) on translated versions of the GSM$8$K and SimpleRL-Zoo datasets in three different languages: Chinese, Korean, and Ukrainian. During training, we monitor both task accuracy and language consistency of the reasoning chains. Our experiments reveal three key findings: (i) GRPO rapidly amplifies pre-training language imbalances, leading to the erosion of low-resource languages within just a few hundred updates; (ii) language consistency reward mitigates this drift but does so at the expense of an almost 5 - 10 pp drop in accuracy. and (iii) the resulting language collapse is severely damaging and largely irreversible, as subsequent fine-tuning struggles to steer the model back toward its original target-language reasoning capabilities. Together, these findings point to a remarkable conclusion: \textit{not all languages are trained equally for reasoning}. Furthermore, our paper sheds light on the roles of reward shaping, data difficulty, and pre-training priors in eliciting multilingual reasoning.
ReGUIDE: Data Efficient GUI Grounding via Spatial Reasoning and Search
May 21, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enabled autonomous agents to interact with computers via Graphical User Interfaces (GUIs), where accurately localizing the coordinates of interface elements (e.g., buttons) is often required for fine-grained actions. However, this remains significantly challenging, leading prior works to rely on large-scale web datasets to improve the grounding accuracy. In this work, we propose Reasoning Graphical User Interface Grounding for Data Efficiency (ReGUIDE), a novel and effective framework for web grounding that enables MLLMs to learn data efficiently through self-generated reasoning and spatial-aware criticism. More specifically, ReGUIDE learns to (i) self-generate a language reasoning process for the localization via online reinforcement learning, and (ii) criticize the prediction using spatial priors that enforce equivariance under input transformations. At inference time, ReGUIDE further boosts performance through a test-time scaling strategy, which combines spatial search with coordinate aggregation. Our experiments demonstrate that ReGUIDE significantly advances web grounding performance across multiple benchmarks, outperforming baselines with substantially fewer training data points (e.g., only 0.2% samples compared to the best open-sourced baselines).
Peri-LN: Revisiting Layer Normalization in the Transformer Architecture
Feb 04, 2025



Designing Transformer architectures with the optimal layer normalization (LN) strategy that ensures large-scale training stability and expedite convergence has remained elusive, even in this era of large language models (LLMs). To this end, we present a comprehensive analytical foundation for understanding how different LN strategies influence training dynamics in large-scale Transformer training. Until recently, Pre-LN and Post-LN have long dominated standard practices despite their limitations in large-scale training. However, several open-source large-scale models have recently begun silently adopting a third strategy without much explanation. This strategy places layer normalization (LN) peripherally around sublayers, a design we term Peri-LN. While Peri-LN has demonstrated promising empirical performance, its precise mechanisms and benefits remain almost unexplored. Our in-depth analysis shows that Peri-LN strikes an ideal balance in variance growth -- unlike Pre-LN and Post-LN, which are prone to vanishing gradients and ``massive activations.'' To validate our theoretical insight, we conduct large-scale experiments on Transformers up to 3.2B parameters, showing that Peri-LN consistently achieves more balanced variance growth, steadier gradient flow, and convergence stability. Our results suggest that Peri-LN warrants broader consideration for large-scale Transformer architectures, providing renewed insights into the optimal placement and application of LN.
Code-Switching Curriculum Learning for Multilingual Transfer in LLMs
Nov 04, 2024



Large language models (LLMs) now exhibit near human-level performance in various tasks, but their performance drops drastically after a handful of high-resource languages due to the imbalance in pre-training data. Inspired by the human process of second language acquisition, particularly code-switching (the practice of language alternation in a conversation), we propose code-switching curriculum learning (CSCL) to enhance cross-lingual transfer for LLMs. CSCL mimics the stages of human language learning by progressively training models with a curriculum consisting of 1) token-level code-switching, 2) sentence-level code-switching, and 3) monolingual corpora. Using Qwen 2 as our underlying model, we demonstrate the efficacy of the CSCL in improving language transfer to Korean, achieving significant performance gains compared to monolingual continual pre-training methods. Ablation studies reveal that both token- and sentence-level code-switching significantly enhance cross-lingual transfer and that curriculum learning amplifies these effects. We also extend our findings into various languages, including Japanese (high-resource) and Indonesian (low-resource), and using two additional models (Gemma 2 and Phi 3.5). We further show that CSCL mitigates spurious correlations between language resources and safety alignment, presenting a robust, efficient framework for more equitable language transfer in LLMs. We observe that CSCL is effective for low-resource settings where high-quality, monolingual corpora for language transfer are hardly available.
Adaptive Contrastive Decoding in Retrieval-Augmented Generation for Handling Noisy Contexts
Aug 02, 2024When using large language models (LLMs) in knowledge-intensive tasks, such as open-domain question answering, external context can bridge a gap between external knowledge and LLM's parametric knowledge. Recent research has been developed to amplify contextual knowledge over the parametric knowledge of LLM with contrastive decoding approaches. While these approaches could yield truthful responses when relevant context is provided, they are prone to vulnerabilities when faced with noisy contexts. We extend the scope of previous studies to encompass noisy contexts and propose adaptive contrastive decoding (ACD) to leverage contextual influence effectively. ACD demonstrates improvements in open-domain question answering tasks compared to baselines, especially in robustness by remaining undistracted by noisy contexts in retrieval-augmented generation.
Aligning Language Models to Explicitly Handle Ambiguity
Apr 18, 2024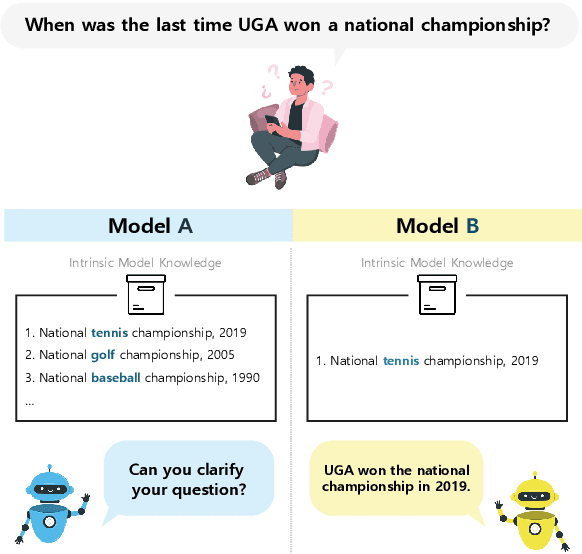
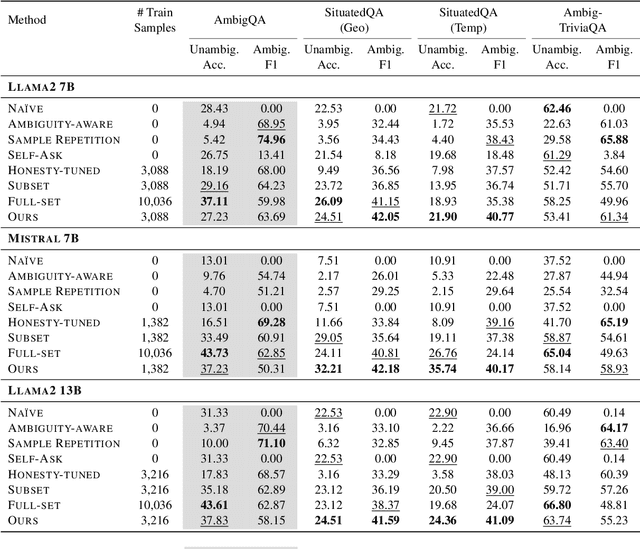
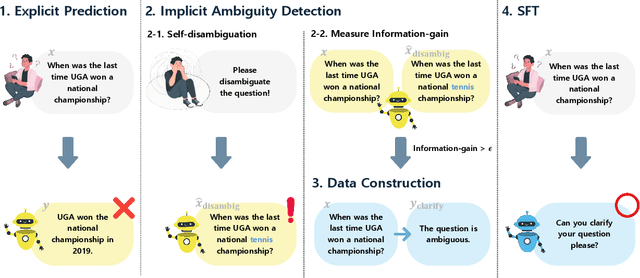
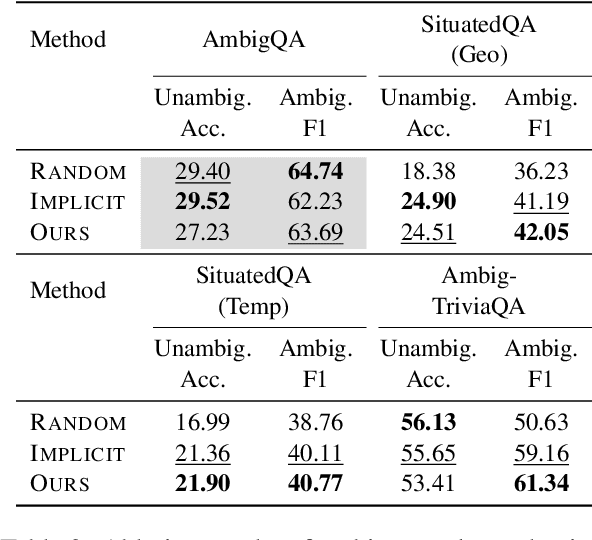
In spoken languages, utterances are often shaped to be incomplete or vague for efficiency. This can lead to varying interpretations of the same input, based on different assumptions about the context. To ensure reliable user-model interactions in such scenarios, it is crucial for models to adeptly handle the inherent ambiguity in user queries. However, conversational agents built upon even the most recent large language models (LLMs) face challenges in processing ambiguous inputs, primarily due to the following two hurdles: (1) LLMs are not directly trained to handle inputs that are too ambiguous to be properly managed; (2) the degree of ambiguity in an input can vary according to the intrinsic knowledge of the LLMs, which is difficult to investigate. To address these issues, this paper proposes a method to align LLMs to explicitly handle ambiguous inputs. Specifically, we introduce a proxy task that guides LLMs to utilize their intrinsic knowledge to self-disambiguate a given input. We quantify the information gain from the disambiguation procedure as a measure of the extent to which the models perceive their inputs as ambiguous. This measure serves as a cue for selecting samples deemed ambiguous from the models' perspectives, which are then utilized for alignment. Experimental results from several question-answering datasets demonstrate that the LLMs fine-tuned with our approach are capable of handling ambiguous inputs while still performing competitively on clear questions within the task.
HyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
KMMLU: Measuring Massive Multitask Language Understanding in Korean
Feb 18, 2024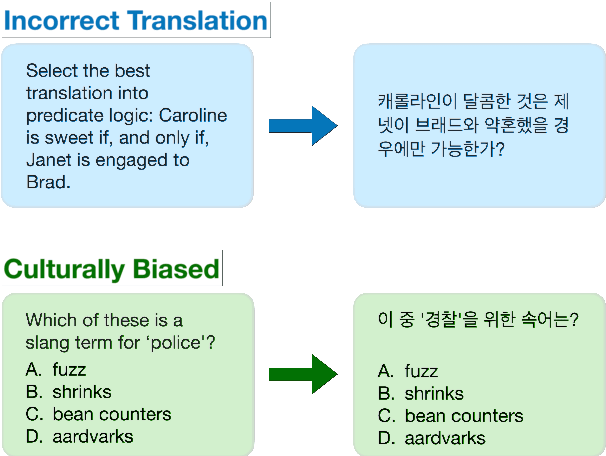



We propose KMMLU, a new Korean benchmark with 35,030 expert-level multiple-choice questions across 45 subjects ranging from humanities to STEM. Unlike previous Korean benchmarks that are translated from existing English benchmarks, KMMLU is collected from original Korean exams, capturing linguistic and cultural aspects of the Korean language. We test 26 publically available and proprietary LLMs, identifying significant room for improvement. The best publicly available model achieves 50.54% on KMMLU, far below the average human performance of 62.6%. This model was primarily trained for English and Chinese, not Korean. Current LLMs tailored to Korean, such as Polyglot-Ko, perform far worse. Surprisingly, even the most capable proprietary LLMs, e.g., GPT-4 and HyperCLOVA X, achieve 59.95% and 53.40%, respectively. This suggests that further work is needed to improve Korean LLMs, and KMMLU offers the right tool to track this progress. We make our dataset publicly available on the Hugging Face Hub and integrate the benchmark into EleutherAI's Language Model Evaluation Harness.
PASTA: PArallel Spatio-Temporal Attention with spatial auto-correlation gating for fine-grained crowd flow prediction
Oct 02, 2023Understanding the movement patterns of objects (e.g., humans and vehicles) in a city is essential for many applications, including city planning and management. This paper proposes a method for predicting future city-wide crowd flows by modeling the spatio-temporal patterns of historical crowd flows in fine-grained city-wide maps. We introduce a novel neural network named PArallel Spatio-Temporal Attention with spatial auto-correlation gating (PASTA) that effectively captures the irregular spatio-temporal patterns of fine-grained maps. The novel components in our approach include spatial auto-correlation gating, multi-scale residual block, and temporal attention gating module. The spatial auto-correlation gating employs the concept of spatial statistics to identify irregular spatial regions. The multi-scale residual block is responsible for handling multiple range spatial dependencies in the fine-grained map, and the temporal attention gating filters out irrelevant temporal information for the prediction. The experimental results demonstrate that our model outperforms other competing baselines, especially under challenging conditions that contain irregular spatial regions. We also provide a qualitative analysis to derive the critical time information where our model assigns high attention scores in prediction.