 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRET: A Self-Evolving LLM Evaluation Toolkit for Korean
Apr 01, 2025Recent advancements in Korean large language models (LLMs) have spurred numerous benchmarks and evaluation methodologies, yet the lack of a standardized evaluation framework has led to inconsistent results and limited comparability. To address this, we introduce HRET Haerae Evaluation Toolkit, an open-source, self-evolving evaluation framework tailored specifically for Korean LLMs. HRET unifies diverse evaluation methods, including logit-based scoring, exact-match, language-inconsistency penalization, and LLM-as-a-Judge assessments. Its modular, registry-based architecture integrates major benchmarks (HAE-RAE Bench, KMMLU, KUDGE, HRM8K) and multiple inference backends (vLLM, HuggingFace, OpenAI-compatible endpoints). With automated pipelines for continuous evolution, HRET provides a robust foundation for reproducible, fair, and transparent Korean NLP research.
TWICE: What Advantages Can Low-Resource Domain-Specific Embedding Model Bring? - A Case Study on Korea Financial Texts
Feb 10, 2025
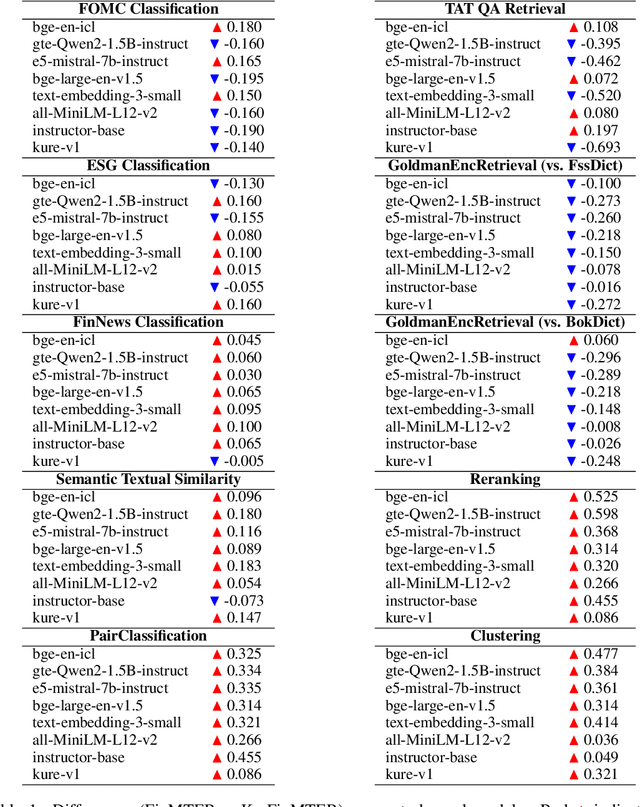

Domain specificity of embedding models is critical for effective performance. However, existing benchmarks, such as FinMTEB, are primarily designed for high-resource languages, leaving low-resource settings, such as Korean, under-explored. Directly translating established English benchmarks often fails to capture the linguistic and cultural nuances present in low-resource domains. In this paper, titled TWICE: What Advantages Can Low-Resource Domain-Specific Embedding Models Bring? A Case Study on Korea Financial Texts, we introduce KorFinMTEB, a novel benchmark for the Korean financial domain, specifically tailored to reflect its unique cultural characteristics in low-resource languages. Our experimental results reveal that while the models perform robustly on a translated version of FinMTEB, their performance on KorFinMTEB uncovers subtle yet critical discrepancies, especially in tasks requiring deeper semantic understanding, that underscore the limitations of direct translation. This discrepancy highlights the necessity of benchmarks that incorporate language-specific idiosyncrasies and cultural nuances. The insights from our study advocate for the development of domain-specific evaluation frameworks that can more accurately assess and drive the progress of embedding models in low-resource settings.
ML-Promise: A Multilingual Dataset for Corporate Promise Verification
Nov 07, 2024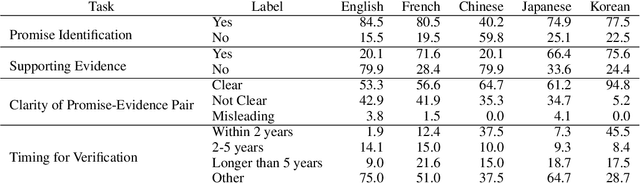
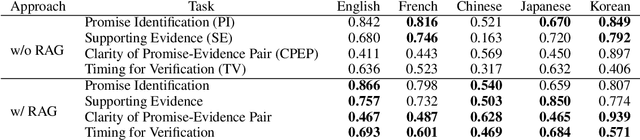
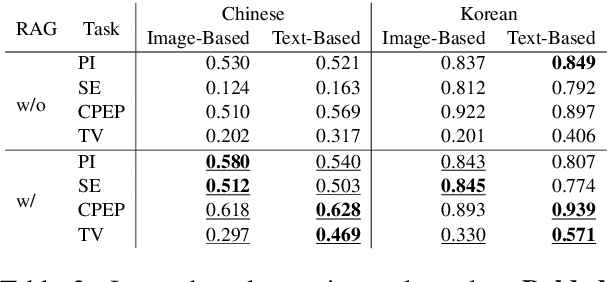
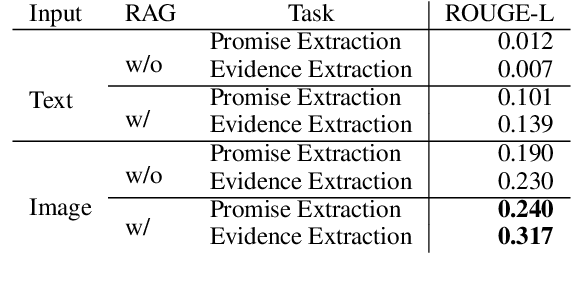
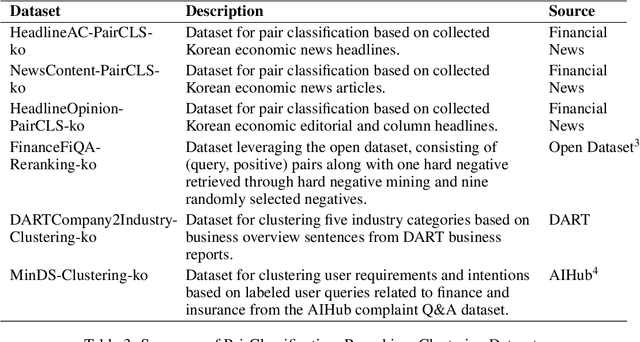
Promises made by politicians, corporate leaders, and public figures have a significant impact on public perception, trust, and institutional reputation. However, the complexity and volume of such commitments, coupled with difficulties in verifying their fulfillment, necessitate innovative methods for assessing their credibility. This paper introduces the concept of Promise Verification, a systematic approach involving steps such as promise identification, evidence assessment, and the evaluation of timing for verification. We propose the first multilingual dataset, ML-Promise, which includes English, French, Chinese, Japanese, and Korean, aimed at facilitating in-depth verification of promises, particularly in the context of Environmental, Social, and Governance (ESG) reports. Given the growing emphasis on corporate environmental contributions, this dataset addresses the challenge of evaluating corporate promises, especially in light of practices like greenwashing. Our findings also explore textual and image-based baselines, with promising results from retrieval-augmented generation (RAG) approaches. This work aims to foster further discourse on the accountability of public commitments across multiple languages and domains.
KMMLU: Measuring Massive Multitask Language Understanding in Korean
Feb 18, 2024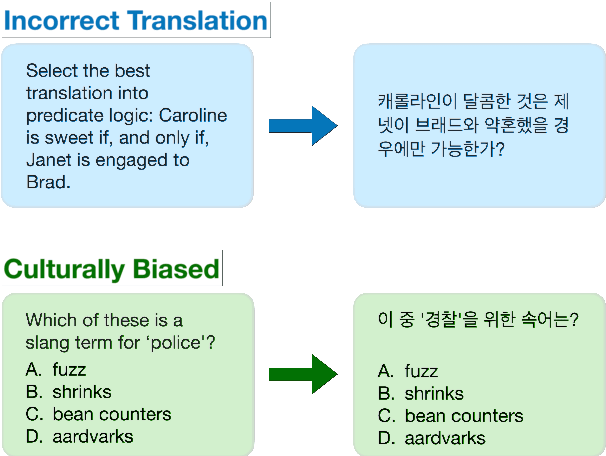



We propose KMMLU, a new Korean benchmark with 35,030 expert-level multiple-choice questions across 45 subjects ranging from humanities to STEM. Unlike previous Korean benchmarks that are translated from existing English benchmarks, KMMLU is collected from original Korean exams, capturing linguistic and cultural aspects of the Korean language. We test 26 publically available and proprietary LLMs, identifying significant room for improvement. The best publicly available model achieves 50.54% on KMMLU, far below the average human performance of 62.6%. This model was primarily trained for English and Chinese, not Korean. Current LLMs tailored to Korean, such as Polyglot-Ko, perform far worse. Surprisingly, even the most capable proprietary LLMs, e.g., GPT-4 and HyperCLOVA X, achieve 59.95% and 53.40%, respectively. This suggests that further work is needed to improve Korean LLMs, and KMMLU offers the right tool to track this progress. We make our dataset publicly available on the Hugging Face Hub and integrate the benchmark into EleutherAI's Language Model Evaluation Harness.
HAE-RAE Bench: Evaluation of Korean Knowledge in Language Models
Sep 15, 2023Large Language Models (LLMs) pretrained on massive corpora exhibit remarkable capabilities across a wide range of tasks, however, the attention given to non-English languages has been limited in this field of research. To address this gap and assess the proficiency of language models in the Korean language and culture, we present HAE-RAE Bench, covering 6 tasks including vocabulary, history, and general knowledge. Our evaluation of language models on this benchmark highlights the potential advantages of employing Large Language-Specific Models(LLSMs) over a comprehensive, universal model like GPT-3.5. Remarkably, our study reveals that models approximately 13 times smaller than GPT-3.5 can exhibit similar performance levels in terms of language-specific knowledge retrieval. This observation underscores the importance of homogeneous corpora for training professional-level language-specific models. On the contrary, we also observe a perplexing performance dip in these smaller LMs when they are tasked to generate structured answers.
EaSyGuide : ESG Issue Identification Framework leveraging Abilities of Generative Large Language Models
Jun 13, 2023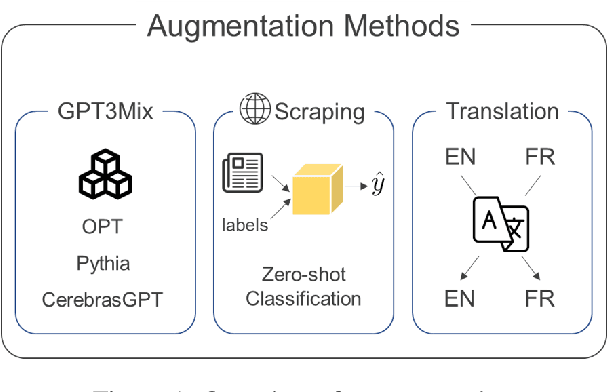


This paper presents our participation in the FinNLP-2023 shared task on multi-lingual environmental, social, and corporate governance issue identification (ML-ESG). The task's objective is to classify news articles based on the 35 ESG key issues defined by the MSCI ESG rating guidelines. Our approach focuses on the English and French subtasks, employing the CerebrasGPT, OPT, and Pythia models, along with the zero-shot and GPT3Mix Augmentation techniques. We utilize various encoder models, such as RoBERTa, DeBERTa, and FinBERT, subjecting them to knowledge distillation and additional training. Our approach yielded exceptional results, securing the first position in the English text subtask with F1-score 0.69 and the second position in the French text subtask with F1-score 0.78. These outcomes underscore the effectiveness of our methodology in identifying ESG issues in news articles across different languages. Our findings contribute to the exploration of ESG topics and highlight the potential of leveraging advanced language models for ESG issue identification.
Removing Non-Stationary Knowledge From Pre-Trained Language Models for Entity-Level Sentiment Classification in Finance
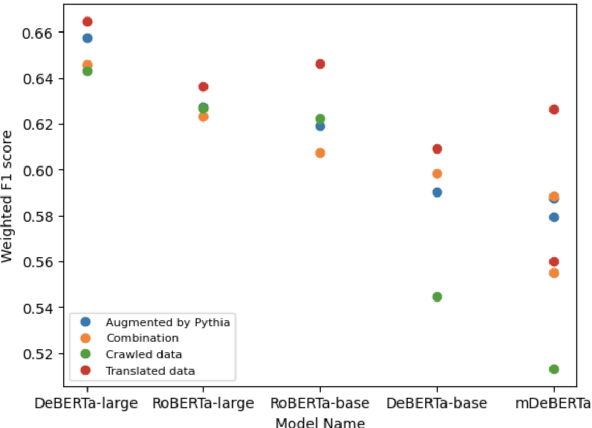
Jan 25, 2023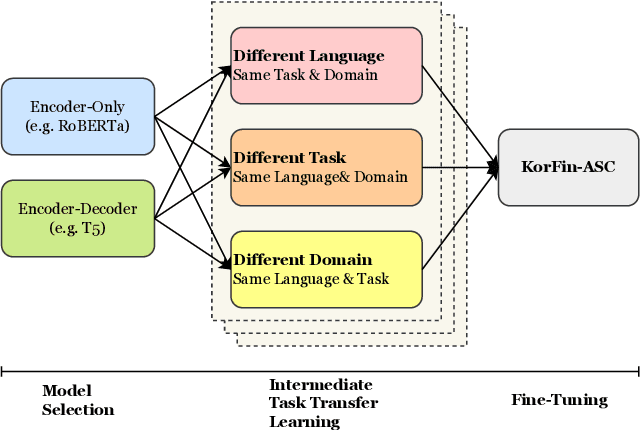

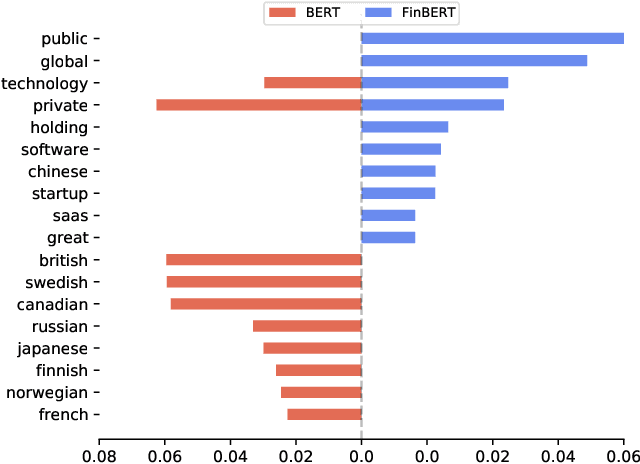
Extraction of sentiment signals from news text, stock message boards, and business reports, for stock movement prediction, has been a rising field of interest in finance. Building upon past literature, the most recent works attempt to better capture sentiment from sentences with complex syntactic structures by introducing aspect-level sentiment classification (ASC). Despite the growing interest, however, fine-grained sentiment analysis has not been fully explored in non-English literature due to the shortage of annotated finance-specific data. Accordingly, it is necessary for non-English languages to leverage datasets and pre-trained language models (PLM) of different domains, languages, and tasks to best their performance. To facilitate finance-specific ASC research in the Korean language, we build KorFinASC, a Korean aspect-level sentiment classification dataset for finance consisting of 12,613 human-annotated samples, and explore methods of intermediate transfer learning. Our experiments indicate that past research has been ignorant towards the potentially wrong knowledge of financial entities encoded during the training phase, which has overestimated the predictive power of PLMs. In our work, we use the term "non-stationary knowledge'' to refer to information that was previously correct but is likely to change, and present "TGT-Masking'', a novel masking pattern to restrict PLMs from speculating knowledge of the kind. Finally, through a series of transfer learning with TGT-Masking applied we improve 22.63% of classification accuracy compared to standalone models on KorFinASC.