 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Expert Alignment Is Hard: Evidence from Subjective Evaluation
May 06, 2026Aligning large language models with expert judgment is especially difficult in subjective evaluation tasks, where experts may disagree, rely on tacit criteria, and change their judgments over time. In this paper, we study expert alignment as a way to understand this difficulty. Using expert evaluations and follow-up questionnaires, we examine how different forms of expert information affect alignment and what this reveals about subjective judgment. Our findings show four consistent patterns. First, alignment difficulty varies substantially across experts, suggesting that expert evaluation styles differ widely in their distance from a model's prior behavior. Second, explicit criteria and reasoning do not always improve alignment, indicating that expert judgment is not fully captured by verbalized rules. Third, editing is sensitive to both the number and the identity of examples, with small numbers of edits providing useful but unstable gains. Fourth, alignment difficulty differs across evaluation dimensions: dimensions grounded more directly in proposal content are easier to align, while dimensions requiring external knowledge or value-based judgment remain harder. Taken together, these results suggest that expert alignment is difficult not only because of model limitations, but also because subjective evaluation is inherently heterogeneous, partly tacit, dimension-dependent, and temporally unstable.
Aggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement
Apr 24, 2026Evaluating LLM-generated business ideas is often harder to scale than generating them. Unlike standard NLP benchmarks, business idea evaluation relies on multi-dimensional criteria such as feasibility, novelty, differentiation, user need, and market size, and expert judgments often disagree. This paper studies a methodological question raised by such disagreement: should an automatic judge approximate an aggregate consensus, or model evaluators individually? We introduce PBIG-DATA, a dataset of approximately 3,000 individual scores across 300 patent-grounded product ideas, provided by domain experts on six business-oriented dimensions: specificity, technical validity, innovativeness, competitive advantage, need validity, and market size. Analyses show substantial expert disagreement on fine-grained ordinal scores, while agreement is higher under coarse selection, suggesting structured heterogeneity rather than random noise. We then compare three judge configurations: a rubric-only zero-shot judge, an aggregate judge conditioned on mixed evaluator histories, and a personalized judge conditioned on the target evaluator's scoring history. Across dimensions and model sizes, personalized judges align more closely with the corresponding evaluator than aggregate judges, and evaluator agreement correlates with similarity of judge-generated reasoning only under personalized conditioning. These results indicate that pooled labels can be a fragile target in pluralistic evaluation settings and motivate evaluator-conditioned judge designs for business idea assessment.
Confidence-Driven Multi-Scale Model Selection for Cost-Efficient Inference
Feb 25, 2026Large Language Models (LLMs) have revolutionized inference across diverse natural language tasks, with larger models performing better but at higher computational costs. We propose a confidence-driven strategy that dynamically selects the most suitable model based on confidence estimates. By assessing a model's confidence in handling the task and response accuracy, tasks that are likely to be solved correctly are retained, while more uncertain or complex cases are delegated to a larger model, ensuring reliability while minimizing computation. Specifically, we evaluate a model's likelihood of knowing the correct answer and the probability that its response is accurate. Experiments on the Massive Multitask Language Understanding (MMLU) benchmark show that our approach achieves accuracy comparable to the largest model while reducing computational costs by 20\% to 40\%. When applied to GPT-4o API calls, it reduces token usage by approximately 60\%, further improving cost efficiency. These findings indicate the potential of confidence-based model selection to enhance real-world LLM deployment, particularly in resource-constrained settings such as edge devices and commercial API applications.
Evaluating Large Language Models as Expert Annotators
Aug 11, 2025Textual data annotation, the process of labeling or tagging text with relevant information, is typically costly, time-consuming, and labor-intensive. While large language models (LLMs) have demonstrated their potential as direct alternatives to human annotators for general domains natural language processing (NLP) tasks, their effectiveness on annotation tasks in domains requiring expert knowledge remains underexplored. In this paper, we investigate: whether top-performing LLMs, which might be perceived as having expert-level proficiency in academic and professional benchmarks, can serve as direct alternatives to human expert annotators? To this end, we evaluate both individual LLMs and multi-agent approaches across three highly specialized domains: finance, biomedicine, and law. Specifically, we propose a multi-agent discussion framework to simulate a group of human annotators, where LLMs are tasked to engage in discussions by considering others' annotations and justifications before finalizing their labels. Additionally, we incorporate reasoning models (e.g., o3-mini) to enable a more comprehensive comparison. Our empirical results reveal that: (1) Individual LLMs equipped with inference-time techniques (e.g., chain-of-thought (CoT), self-consistency) show only marginal or even negative performance gains, contrary to prior literature suggesting their broad effectiveness. (2) Overall, reasoning models do not demonstrate statistically significant improvements over non-reasoning models in most settings. This suggests that extended long CoT provides relatively limited benefits for data annotation in specialized domains. (3) Certain model behaviors emerge in the multi-agent discussion environment. For instance, Claude 3.7 Sonnet with thinking rarely changes its initial annotations, even when other agents provide correct annotations or valid reasoning.
Modeling Professionalism in Expert Questioning through Linguistic Differentiation
Jul 27, 2025Professionalism is a crucial yet underexplored dimension of expert communication, particularly in high-stakes domains like finance. This paper investigates how linguistic features can be leveraged to model and evaluate professionalism in expert questioning. We introduce a novel annotation framework to quantify structural and pragmatic elements in financial analyst questions, such as discourse regulators, prefaces, and request types. Using both human-authored and large language model (LLM)-generated questions, we construct two datasets: one annotated for perceived professionalism and one labeled by question origin. We show that the same linguistic features correlate strongly with both human judgments and authorship origin, suggesting a shared stylistic foundation. Furthermore, a classifier trained solely on these interpretable features outperforms gemini-2.0 and SVM baselines in distinguishing expert-authored questions. Our findings demonstrate that professionalism is a learnable, domain-general construct that can be captured through linguistically grounded modeling.
Decision-Oriented Text Evaluation
Jul 03, 2025
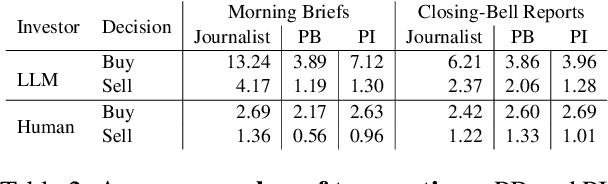

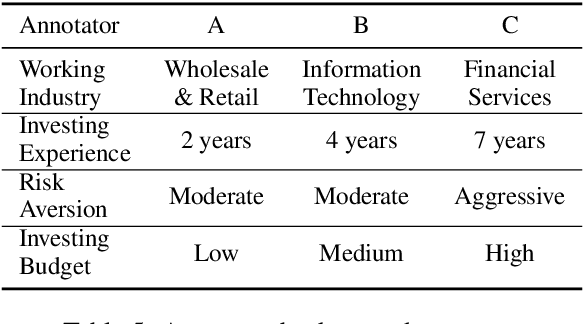
Natural language generation (NLG) is increasingly deployed in high-stakes domains, yet common intrinsic evaluation methods, such as n-gram overlap or sentence plausibility, weakly correlate with actual decision-making efficacy. We propose a decision-oriented framework for evaluating generated text by directly measuring its influence on human and large language model (LLM) decision outcomes. Using market digest texts--including objective morning summaries and subjective closing-bell analyses--as test cases, we assess decision quality based on the financial performance of trades executed by human investors and autonomous LLM agents informed exclusively by these texts. Our findings reveal that neither humans nor LLM agents consistently surpass random performance when relying solely on summaries. However, richer analytical commentaries enable collaborative human-LLM teams to outperform individual human or agent baselines significantly. Our approach underscores the importance of evaluating generated text by its ability to facilitate synergistic decision-making between humans and LLMs, highlighting critical limitations of traditional intrinsic metrics.
Refining Financial Consumer Complaints through Multi-Scale Model Interaction
Apr 14, 2025Legal writing demands clarity, formality, and domain-specific precision-qualities often lacking in documents authored by individuals without legal training. To bridge this gap, this paper explores the task of legal text refinement that transforms informal, conversational inputs into persuasive legal arguments. We introduce FinDR, a Chinese dataset of financial dispute records, annotated with official judgments on claim reasonableness. Our proposed method, Multi-Scale Model Interaction (MSMI), leverages a lightweight classifier to evaluate outputs and guide iterative refinement by Large Language Models (LLMs). Experimental results demonstrate that MSMI significantly outperforms single-pass prompting strategies. Additionally, we validate the generalizability of MSMI on several short-text benchmarks, showing improved adversarial robustness. Our findings reveal the potential of multi-model collaboration for enhancing legal document generation and broader text refinement tasks.
The Impact and Feasibility of Self-Confidence Shaping for AI-Assisted Decision-Making
Feb 20, 2025In AI-assisted decision-making, it is crucial but challenging for humans to appropriately rely on AI, especially in high-stakes domains such as finance and healthcare. This paper addresses this problem from a human-centered perspective by presenting an intervention for self-confidence shaping, designed to calibrate self-confidence at a targeted level. We first demonstrate the impact of self-confidence shaping by quantifying the upper-bound improvement in human-AI team performance. Our behavioral experiments with 121 participants show that self-confidence shaping can improve human-AI team performance by nearly 50% by mitigating both over- and under-reliance on AI. We then introduce a self-confidence prediction task to identify when our intervention is needed. Our results show that simple machine-learning models achieve 67% accuracy in predicting self-confidence. We further illustrate the feasibility of such interventions. The observed relationship between sentiment and self-confidence suggests that modifying sentiment could be a viable strategy for shaping self-confidence. Finally, we outline future research directions to support the deployment of self-confidence shaping in a real-world scenario for effective human-AI collaboration.
Observing Micromotives and Macrobehavior of Large Language Models
Dec 10, 2024Thomas C. Schelling, awarded the 2005 Nobel Memorial Prize in Economic Sciences, pointed out that ``individuals decisions (micromotives), while often personal and localized, can lead to societal outcomes (macrobehavior) that are far more complex and different from what the individuals intended.'' The current research related to large language models' (LLMs') micromotives, such as preferences or biases, assumes that users will make more appropriate decisions once LLMs are devoid of preferences or biases. Consequently, a series of studies has focused on removing bias from LLMs. In the NLP community, while there are many discussions on LLMs' micromotives, previous studies have seldom conducted a systematic examination of how LLMs may influence society's macrobehavior. In this paper, we follow the design of Schelling's model of segregation to observe the relationship between the micromotives and macrobehavior of LLMs. Our results indicate that, regardless of the level of bias in LLMs, a highly segregated society will emerge as more people follow LLMs' suggestions. We hope our discussion will spark further consideration of the fundamental assumption regarding the mitigation of LLMs' micromotives and encourage a reevaluation of how LLMs may influence users and society.
Paraphrase-Aligned Machine Translation
Dec 08, 2024Large Language Models (LLMs) have demonstrated significant capabilities in machine translation. However, their translation quality is sometimes questioned, as the generated outputs may deviate from expressions typically used by native speakers. These deviations often arise from differences in sentence structure between language systems. To address this issue, we propose ParaAlign Translator, a method that fine-tunes LLMs to paraphrase sentences, aligning their structures with those of the target language systems. This approach improves the performance of subsequent translations. Experimental results demonstrate that the proposed method enhances the LLaMA-3-8B model's performance in both resource-rich and low-resource scenarios and achieves parity with or surpassing the much larger LLaMA-3-70B model.