 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Laughs with Whom? Disentangling Influential Factors in Humor Preferences across User Clusters and LLMs
Jan 06, 2026Humor preferences vary widely across individuals and cultures, complicating the evaluation of humor using large language models (LLMs). In this study, we model heterogeneity in humor preferences in Oogiri, a Japanese creative response game, by clustering users with voting logs and estimating cluster-specific weights over interpretable preference factors using Bradley-Terry-Luce models. We elicit preference judgments from LLMs by prompting them to select the funnier response and found that user clusters exhibit distinct preference patterns and that the LLM results can resemble those of particular clusters. Finally, we demonstrate that, by persona prompting, LLM preferences can be directed toward a specific cluster. The scripts for data collection and analysis will be released to support reproducibility.
Oogiri-Master: Benchmarking Humor Understanding via Oogiri
Dec 25, 2025
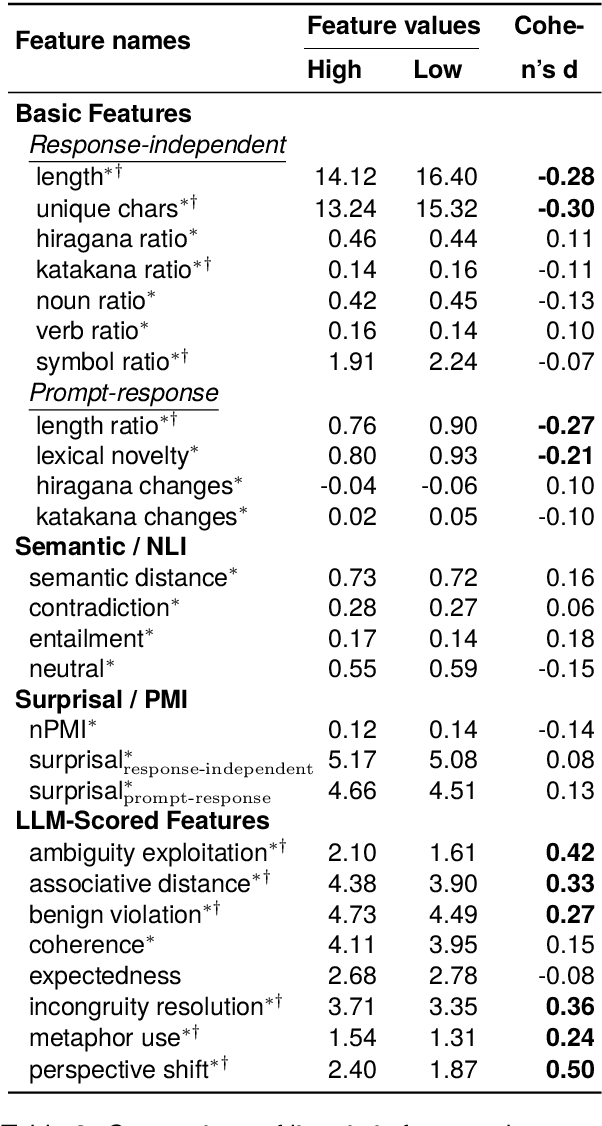

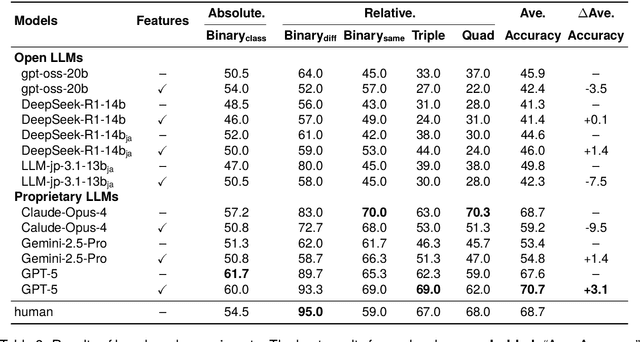
Humor is a salient testbed for human-like creative thinking in large language models (LLMs). We study humor using the Japanese creative response game Oogiri, in which participants produce witty responses to a given prompt, and ask the following research question: What makes such responses funny to humans? Previous work has offered only limited reliable means to answer this question. Existing datasets contain few candidate responses per prompt, expose popularity signals during ratings, and lack objective and comparable metrics for funniness. Thus, we introduce Oogiri-Master and Oogiri-Corpus, which are a benchmark and dataset designed to enable rigorous evaluation of humor understanding in LLMs. Each prompt is paired with approximately 100 diverse candidate responses, and funniness is rated independently by approximately 100 human judges without access to others' ratings, reducing popularity bias and enabling robust aggregation. Using Oogiri-Corpus, we conduct a quantitative analysis of the linguistic factors associated with funniness, such as text length, ambiguity, and incongruity resolution, and derive objective metrics for predicting human judgments. Subsequently, we benchmark a range of LLMs and human baselines in Oogiri-Master, demonstrating that state-of-the-art models approach human performance and that insight-augmented prompting improves the model performance. Our results provide a principled basis for evaluating and advancing humor understanding in LLMs.
Tracking Temporal Dynamics of Vector Sets with Gaussian Process
Dec 17, 2025Understanding the temporal evolution of sets of vectors is a fundamental challenge across various domains, including ecology, crime analysis, and linguistics. For instance, ecosystem structures evolve due to interactions among plants, herbivores, and carnivores; the spatial distribution of crimes shifts in response to societal changes; and word embedding vectors reflect cultural and semantic trends over time. However, analyzing such time-varying sets of vectors is challenging due to their complicated structures, which also evolve over time. In this work, we propose a novel method for modeling the distribution underlying each set of vectors using infinite-dimensional Gaussian processes. By approximating the latent function in the Gaussian process with Random Fourier Features, we obtain compact and comparable vector representations over time. This enables us to track and visualize temporal transitions of vector sets in a low-dimensional space. We apply our method to both sociological data (crime distributions) and linguistic data (word embeddings), demonstrating its effectiveness in capturing temporal dynamics. Our results show that the proposed approach provides interpretable and robust representations, offering a powerful framework for analyzing structural changes in temporally indexed vector sets across diverse domains.
QCoder Benchmark: Bridging Language Generation and Quantum Hardware through Simulator-Based Feedback
Oct 30, 2025Large language models (LLMs) have increasingly been applied to automatic programming code generation. This task can be viewed as a language generation task that bridges natural language, human knowledge, and programming logic. However, it remains underexplored in domains that require interaction with hardware devices, such as quantum programming, where human coders write Python code that is executed on a quantum computer. To address this gap, we introduce QCoder Benchmark, an evaluation framework that assesses LLMs on quantum programming with feedback from simulated hardware devices. Our benchmark offers two key features. First, it supports evaluation using a quantum simulator environment beyond conventional Python execution, allowing feedback of domain-specific metrics such as circuit depth, execution time, and error classification, which can be used to guide better generation. Second, it incorporates human-written code submissions collected from real programming contests, enabling both quantitative comparisons and qualitative analyses of LLM outputs against human-written codes. Our experiments reveal that even advanced models like GPT-4o achieve only around 18.97% accuracy, highlighting the difficulty of the benchmark. In contrast, reasoning-based models such as o3 reach up to 78% accuracy, outperforming averaged success rates of human-written codes (39.98%). We release the QCoder Benchmark dataset and public evaluation API to support further research.
AdParaphrase v2.0: Generating Attractive Ad Texts Using a Preference-Annotated Paraphrase Dataset
May 27, 2025Identifying factors that make ad text attractive is essential for advertising success. This study proposes AdParaphrase v2.0, a dataset for ad text paraphrasing, containing human preference data, to enable the analysis of the linguistic factors and to support the development of methods for generating attractive ad texts. Compared with v1.0, this dataset is 20 times larger, comprising 16,460 ad text paraphrase pairs, each annotated with preference data from ten evaluators, thereby enabling a more comprehensive and reliable analysis. Through the experiments, we identified multiple linguistic features of engaging ad texts that were not observed in v1.0 and explored various methods for generating attractive ad texts. Furthermore, our analysis demonstrated the relationships between human preference and ad performance, and highlighted the potential of reference-free metrics based on large language models for evaluating ad text attractiveness. The dataset is publicly available at: https://github.com/CyberAgentAILab/AdParaphrase-v2.0.
Rewriting Pre-Training Data Boosts LLM Performance in Math and Code
May 05, 2025The performance of large language models (LLMs) in program synthesis and mathematical reasoning is fundamentally limited by the quality of their pre-training corpora. We introduce two openly licensed datasets, released under the Llama 3.3 Community License, that significantly enhance LLM performance by systematically rewriting public data. SwallowCode (approximately 16.1 billion tokens) refines Python snippets from The-Stack-v2 through a novel four-stage pipeline: syntax validation, pylint-based style filtering, and a two-stage LLM rewriting process that enforces style conformity and transforms snippets into self-contained, algorithmically efficient examples. Unlike prior methods that rely on exclusionary filtering or limited transformations, our transform-and-retain approach upgrades low-quality code, maximizing data utility. SwallowMath (approximately 2.3 billion tokens) enhances Finemath-4+ by removing boilerplate, restoring context, and reformatting solutions into concise, step-by-step explanations. Within a fixed 50 billion token training budget, continual pre-training of Llama-3.1-8B with SwallowCode boosts pass@1 by +17.0 on HumanEval and +17.7 on HumanEval+ compared to Stack-Edu, surpassing the baseline model's code generation capabilities. Similarly, substituting SwallowMath yields +12.4 accuracy on GSM8K and +7.6 on MATH. Ablation studies confirm that each pipeline stage contributes incrementally, with rewriting delivering the largest gains. All datasets, prompts, and checkpoints are publicly available, enabling reproducible research and advancing LLM pre-training for specialized domains.
Building Instruction-Tuning Datasets from Human-Written Instructions with Open-Weight Large Language Models
Mar 31, 2025Instruction tuning is crucial for enabling Large Language Models (LLMs) to solve real-world tasks. Prior work has shown the effectiveness of instruction-tuning data synthesized solely from LLMs, raising a fundamental question: Do we still need human-originated signals for instruction tuning? This work answers the question affirmatively: we build state-of-the-art instruction-tuning datasets sourced from human-written instructions, by simply pairing them with LLM-generated responses. LLMs fine-tuned on our datasets consistently outperform those fine-tuned on existing ones. Our data construction approach can be easily adapted to other languages; we build datasets for Japanese and confirm that LLMs tuned with our data reach state-of-the-art performance. Analyses suggest that instruction-tuning in a new language allows LLMs to follow instructions, while the tuned models exhibit a notable lack of culture-specific knowledge in that language. The datasets and fine-tuned models will be publicly available. Our datasets, synthesized with open-weight LLMs, are openly distributed under permissive licenses, allowing for diverse use cases.
AdParaphrase: Paraphrase Dataset for Analyzing Linguistic Features toward Generating Attractive Ad Texts
Feb 07, 2025



Effective linguistic choices that attract potential customers play crucial roles in advertising success. This study aims to explore the linguistic features of ad texts that influence human preferences. Although the creation of attractive ad texts is an active area of research, progress in understanding the specific linguistic features that affect attractiveness is hindered by several obstacles. First, human preferences are complex and influenced by multiple factors, including their content, such as brand names, and their linguistic styles, making analysis challenging. Second, publicly available ad text datasets that include human preferences are lacking, such as ad performance metrics and human feedback, which reflect people's interests. To address these problems, we present AdParaphrase, a paraphrase dataset that contains human preferences for pairs of ad texts that are semantically equivalent but differ in terms of wording and style. This dataset allows for preference analysis that focuses on the differences in linguistic features. Our analysis revealed that ad texts preferred by human judges have higher fluency, longer length, more nouns, and use of bracket symbols. Furthermore, we demonstrate that an ad text-generation model that considers these findings significantly improves the attractiveness of a given text. The dataset is publicly available at: https://github.com/CyberAgentAILab/AdParaphrase.
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices
Jan 16, 2025



The meanings and relationships of words shift over time. This phenomenon is referred to as semantic shift.Research focused on understanding how semantic shifts occur over multiple time periods is essential for gaining a detailed understanding of semantic shifts.However, detecting change points only between adjacent time periods is insufficient for analyzing detailed semantic shifts, and using BERT-based methods to examine word sense proportions incurs a high computational cost.To address those issues, we propose a simple yet intuitive framework for how semantic shifts occur over multiple time periods by leveraging a similarity matrix between the embeddings of the same word through time.We compute a diachronic word similarity matrix using fast and lightweight word embeddings across arbitrary time periods, making it deeper to analyze continuous semantic shifts.Additionally, by clustering the similarity matrices for different words, we can categorize words that exhibit similar behavior of semantic shift in an unsupervised manner.
Why We Build Local Large Language Models: An Observational Analysis from 35 Japanese and Multilingual LLMs
Dec 19, 2024



Why do we build local large language models (LLMs)? What should a local LLM learn from the target language? Which abilities can be transferred from other languages? Do language-specific scaling laws exist? To explore these research questions, we evaluated 35 Japanese, English, and multilingual LLMs on 19 evaluation benchmarks for Japanese and English, taking Japanese as a local language. Adopting an observational approach, we analyzed correlations of benchmark scores, and conducted principal component analysis (PCA) on the scores to derive \textit{ability factors} of local LLMs. We found that training on English text can improve the scores of academic subjects in Japanese (JMMLU). In addition, it is unnecessary to specifically train on Japanese text to enhance abilities for solving Japanese code generation, arithmetic reasoning, commonsense, and reading comprehension tasks. In contrast, training on Japanese text could improve question-answering tasks about Japanese knowledge and English-Japanese translation, which indicates that abilities for solving these two tasks can be regarded as \textit{Japanese abilities} for LLMs. Furthermore, we confirmed that the Japanese abilities scale with the computational budget for Japanese text.