 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Self-Consistency Improve the Recall of Encyclopedic Knowledge?
Apr 21, 2026While self-consistency is known to improve performance on symbolic reasoning, its effect on the recall of encyclopedic knowledge is unclear due to a lack of targeted evaluation grounds. To address this, we establish such a knowledge recall split for the popular MMLU benchmark by applying a data-driven heuristic from prior work. We validate this split by showing that the performance patterns on the symbolic reasoning and knowledge recall subsets mirror those of GSM8K and MedMCQA, respectively. Using this solid ground, we find that self-consistency consistently improves performance across both symbolic reasoning and knowledge recall, even though its underlying CoT prompting is primarily effective for symbolic reasoning. As a result, we achieve an 89\% accuracy on MMLU, the best performance to date with the use of GPT-4o.
Routing by Analogy: kNN-Augmented Expert Assignment for Mixture-of-Experts
Jan 05, 2026Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric "router" to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning.
AdParaphrase v2.0: Generating Attractive Ad Texts Using a Preference-Annotated Paraphrase Dataset
May 27, 2025Identifying factors that make ad text attractive is essential for advertising success. This study proposes AdParaphrase v2.0, a dataset for ad text paraphrasing, containing human preference data, to enable the analysis of the linguistic factors and to support the development of methods for generating attractive ad texts. Compared with v1.0, this dataset is 20 times larger, comprising 16,460 ad text paraphrase pairs, each annotated with preference data from ten evaluators, thereby enabling a more comprehensive and reliable analysis. Through the experiments, we identified multiple linguistic features of engaging ad texts that were not observed in v1.0 and explored various methods for generating attractive ad texts. Furthermore, our analysis demonstrated the relationships between human preference and ad performance, and highlighted the potential of reference-free metrics based on large language models for evaluating ad text attractiveness. The dataset is publicly available at: https://github.com/CyberAgentAILab/AdParaphrase-v2.0.
Out-of-the-Box Conditional Text Embeddings from Large Language Models
Apr 23, 2025

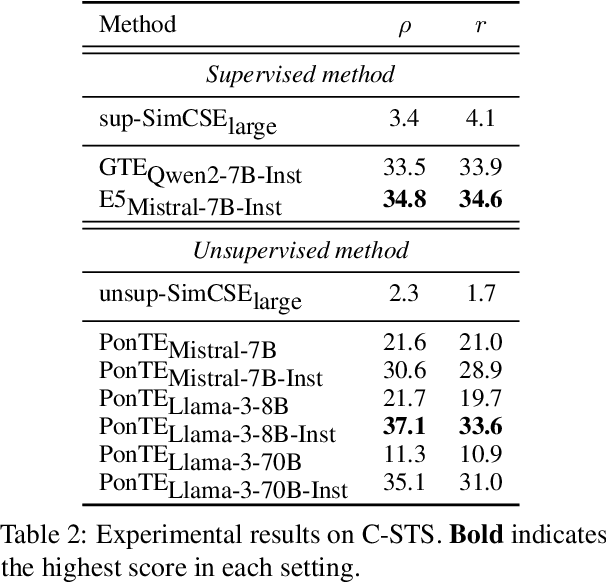

Conditional text embedding is a proposed representation that captures the shift in perspective on texts when conditioned on a specific aspect. Previous methods have relied on extensive training data for fine-tuning models, leading to challenges in terms of labor and resource costs. We propose PonTE, a novel unsupervised conditional text embedding method that leverages a causal large language model and a conditional prompt. Through experiments on conditional semantic text similarity and text clustering, we demonstrate that PonTE can generate useful conditional text embeddings and achieve performance comparable to supervised methods without fine-tuning. We also show the interpretability of text embeddings with PonTE by analyzing word generation following prompts and embedding visualization.
AdParaphrase: Paraphrase Dataset for Analyzing Linguistic Features toward Generating Attractive Ad Texts
Feb 07, 2025



Effective linguistic choices that attract potential customers play crucial roles in advertising success. This study aims to explore the linguistic features of ad texts that influence human preferences. Although the creation of attractive ad texts is an active area of research, progress in understanding the specific linguistic features that affect attractiveness is hindered by several obstacles. First, human preferences are complex and influenced by multiple factors, including their content, such as brand names, and their linguistic styles, making analysis challenging. Second, publicly available ad text datasets that include human preferences are lacking, such as ad performance metrics and human feedback, which reflect people's interests. To address these problems, we present AdParaphrase, a paraphrase dataset that contains human preferences for pairs of ad texts that are semantically equivalent but differ in terms of wording and style. This dataset allows for preference analysis that focuses on the differences in linguistic features. Our analysis revealed that ad texts preferred by human judges have higher fluency, longer length, more nouns, and use of bracket symbols. Furthermore, we demonstrate that an ad text-generation model that considers these findings significantly improves the attractiveness of a given text. The dataset is publicly available at: https://github.com/CyberAgentAILab/AdParaphrase.
LCTG Bench: LLM Controlled Text Generation Benchmark
Jan 27, 2025



The rise of large language models (LLMs) has led to more diverse and higher-quality machine-generated text. However, their high expressive power makes it difficult to control outputs based on specific business instructions. In response, benchmarks focusing on the controllability of LLMs have been developed, but several issues remain: (1) They primarily cover major languages like English and Chinese, neglecting low-resource languages like Japanese; (2) Current benchmarks employ task-specific evaluation metrics, lacking a unified framework for selecting models based on controllability across different use cases. To address these challenges, this research introduces LCTG Bench, the first Japanese benchmark for evaluating the controllability of LLMs. LCTG Bench provides a unified framework for assessing control performance, enabling users to select the most suitable model for their use cases based on controllability. By evaluating nine diverse Japanese-specific and multilingual LLMs like GPT-4, we highlight the current state and challenges of controllability in Japanese LLMs and reveal the significant gap between multilingual models and Japanese-specific models.
FaithCAMERA: Construction of a Faithful Dataset for Ad Text Generation
Oct 04, 2024



In ad text generation (ATG), desirable ad text is both faithful and informative. That is, it should be faithful to the input document, while at the same time containing important information that appeals to potential customers. The existing evaluation data, CAMERA (arXiv:2309.12030), is suitable for evaluating informativeness, as it consists of reference ad texts created by ad creators. However, these references often include information unfaithful to the input, which is a notable obstacle in promoting ATG research. In this study, we collaborate with in-house ad creators to refine the CAMERA references and develop an alternative ATG evaluation dataset called FaithCAMERA, in which the faithfulness of references is guaranteed. Using FaithCAMERA, we can evaluate how well existing methods for improving faithfulness can generate informative ad text while maintaining faithfulness. Our experiments show that removing training data that contains unfaithful entities improves the faithfulness and informativeness at the entity level, but decreases both at the sentence level. This result suggests that for future ATG research, it is essential not only to scale the training data but also to ensure their faithfulness. Our dataset will be publicly available.
AdTEC: A Unified Benchmark for Evaluating Text Quality in Search Engine Advertising
Aug 12, 2024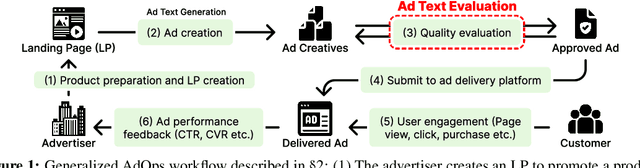


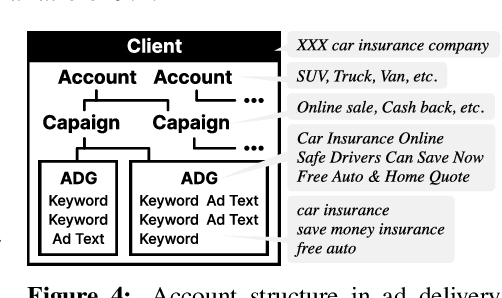
With the increase in the more fluent ad texts automatically created by natural language generation technology, it is in the high demand to verify the quality of these creatives in a real-world setting. We propose AdTEC, the first public benchmark to evaluate ad texts in multiple aspects from the perspective of practical advertising operations. Our contributions are: (i) Defining five tasks for evaluating the quality of ad texts and building a dataset based on the actual operational experience of advertising agencies, which is typically kept in-house. (ii) Validating the performance of existing pre-trained language models (PLMs) and human evaluators on the dataset. (iii) Analyzing the characteristics and providing challenges of the benchmark. The results show that while PLMs have already reached the practical usage level in several tasks, human still outperforms in certain domains, implying that there is significant room for improvement in such area.
Not Eliminate but Aggregate: Post-Hoc Control over Mixture-of-Experts to Address Shortcut Shifts in Natural Language Understanding
Jun 17, 2024Recent models for natural language understanding are inclined to exploit simple patterns in datasets, commonly known as shortcuts. These shortcuts hinge on spurious correlations between labels and latent features existing in the training data. At inference time, shortcut-dependent models are likely to generate erroneous predictions under distribution shifts, particularly when some latent features are no longer correlated with the labels. To avoid this, previous studies have trained models to eliminate the reliance on shortcuts. In this study, we explore a different direction: pessimistically aggregating the predictions of a mixture-of-experts, assuming each expert captures relatively different latent features. The experimental results demonstrate that our post-hoc control over the experts significantly enhances the model's robustness to the distribution shift in shortcuts. Besides, we show that our approach has some practical advantages. We also analyze our model and provide results to support the assumption.
Cross-lingual Transfer or Machine Translation? On Data Augmentation for Monolingual Semantic Textual Similarity
Mar 08, 2024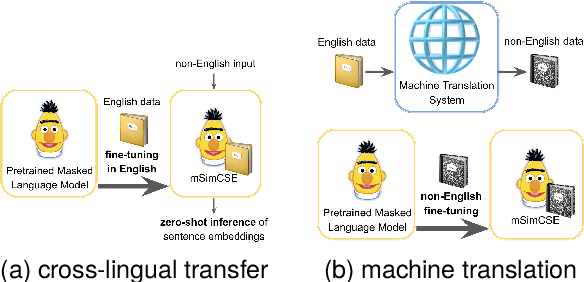
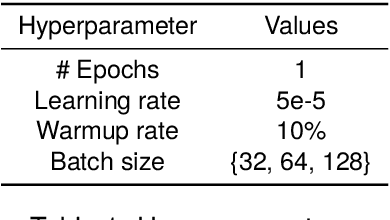
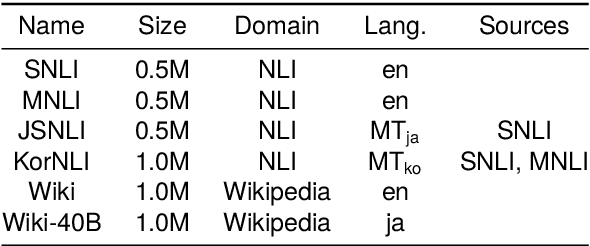
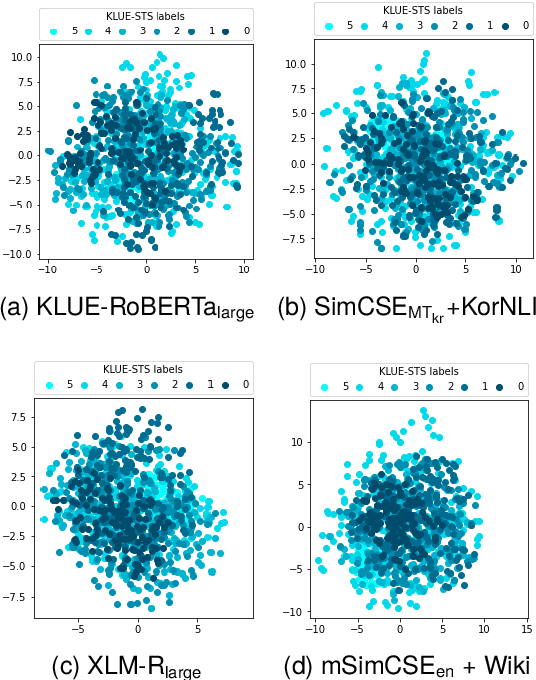
Learning better sentence embeddings leads to improved performance for natural language understanding tasks including semantic textual similarity (STS) and natural language inference (NLI). As prior studies leverage large-scale labeled NLI datasets for fine-tuning masked language models to yield sentence embeddings, task performance for languages other than English is often left behind. In this study, we directly compared two data augmentation techniques as potential solutions for monolingual STS: (a) cross-lingual transfer that exploits English resources alone as training data to yield non-English sentence embeddings as zero-shot inference, and (b) machine translation that coverts English data into pseudo non-English training data in advance. In our experiments on monolingual STS in Japanese and Korean, we find that the two data techniques yield performance on par. Rather, we find a superiority of the Wikipedia domain over the NLI domain for these languages, in contrast to prior studies that focused on NLI as training data. Combining our findings, we demonstrate that the cross-lingual transfer of Wikipedia data exhibits improved performance, and that native Wikipedia data can further improve performance for monolingual STS.