 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Laughs with Whom? Disentangling Influential Factors in Humor Preferences across User Clusters and LLMs
Jan 06, 2026Humor preferences vary widely across individuals and cultures, complicating the evaluation of humor using large language models (LLMs). In this study, we model heterogeneity in humor preferences in Oogiri, a Japanese creative response game, by clustering users with voting logs and estimating cluster-specific weights over interpretable preference factors using Bradley-Terry-Luce models. We elicit preference judgments from LLMs by prompting them to select the funnier response and found that user clusters exhibit distinct preference patterns and that the LLM results can resemble those of particular clusters. Finally, we demonstrate that, by persona prompting, LLM preferences can be directed toward a specific cluster. The scripts for data collection and analysis will be released to support reproducibility.
Routing by Analogy: kNN-Augmented Expert Assignment for Mixture-of-Experts
Jan 05, 2026Mixture-of-Experts (MoE) architectures scale large language models efficiently by employing a parametric "router" to dispatch tokens to a sparse subset of experts. Typically, this router is trained once and then frozen, rendering routing decisions brittle under distribution shifts. We address this limitation by introducing kNN-MoE, a retrieval-augmented routing framework that reuses optimal expert assignments from a memory of similar past cases. This memory is constructed offline by directly optimizing token-wise routing logits to maximize the likelihood on a reference set. Crucially, we use the aggregate similarity of retrieved neighbors as a confidence-driven mixing coefficient, thus allowing the method to fall back to the frozen router when no relevant cases are found. Experiments show kNN-MoE outperforms zero-shot baselines and rivals computationally expensive supervised fine-tuning.
Oogiri-Master: Benchmarking Humor Understanding via Oogiri
Dec 25, 2025
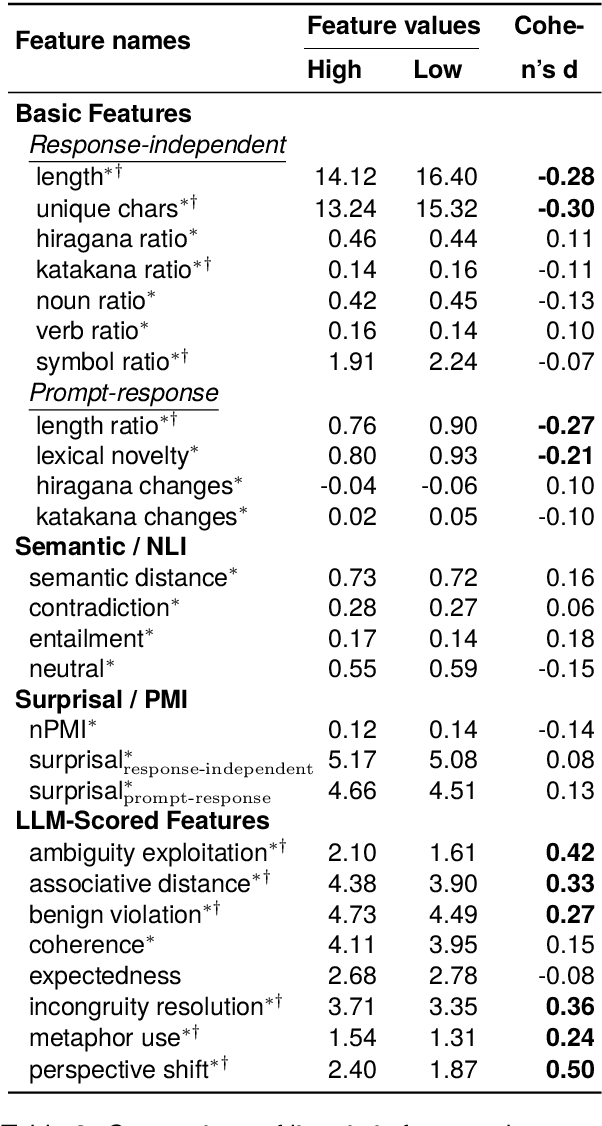

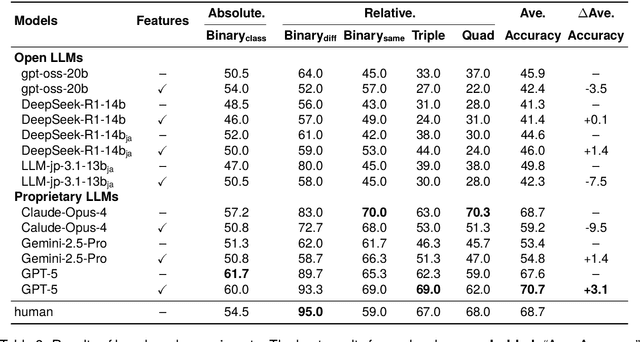
Humor is a salient testbed for human-like creative thinking in large language models (LLMs). We study humor using the Japanese creative response game Oogiri, in which participants produce witty responses to a given prompt, and ask the following research question: What makes such responses funny to humans? Previous work has offered only limited reliable means to answer this question. Existing datasets contain few candidate responses per prompt, expose popularity signals during ratings, and lack objective and comparable metrics for funniness. Thus, we introduce Oogiri-Master and Oogiri-Corpus, which are a benchmark and dataset designed to enable rigorous evaluation of humor understanding in LLMs. Each prompt is paired with approximately 100 diverse candidate responses, and funniness is rated independently by approximately 100 human judges without access to others' ratings, reducing popularity bias and enabling robust aggregation. Using Oogiri-Corpus, we conduct a quantitative analysis of the linguistic factors associated with funniness, such as text length, ambiguity, and incongruity resolution, and derive objective metrics for predicting human judgments. Subsequently, we benchmark a range of LLMs and human baselines in Oogiri-Master, demonstrating that state-of-the-art models approach human performance and that insight-augmented prompting improves the model performance. Our results provide a principled basis for evaluating and advancing humor understanding in LLMs.
AdParaphrase v2.0: Generating Attractive Ad Texts Using a Preference-Annotated Paraphrase Dataset
May 27, 2025Identifying factors that make ad text attractive is essential for advertising success. This study proposes AdParaphrase v2.0, a dataset for ad text paraphrasing, containing human preference data, to enable the analysis of the linguistic factors and to support the development of methods for generating attractive ad texts. Compared with v1.0, this dataset is 20 times larger, comprising 16,460 ad text paraphrase pairs, each annotated with preference data from ten evaluators, thereby enabling a more comprehensive and reliable analysis. Through the experiments, we identified multiple linguistic features of engaging ad texts that were not observed in v1.0 and explored various methods for generating attractive ad texts. Furthermore, our analysis demonstrated the relationships between human preference and ad performance, and highlighted the potential of reference-free metrics based on large language models for evaluating ad text attractiveness. The dataset is publicly available at: https://github.com/CyberAgentAILab/AdParaphrase-v2.0.
Exploring the Relationship Between Diversity and Quality in Ad Text Generation
May 22, 2025In natural language generation for advertising, creating diverse and engaging ad texts is crucial for capturing a broad audience and avoiding advertising fatigue. Regardless of the importance of diversity, the impact of the diversity-enhancing methods in ad text generation -- mainly tested on tasks such as summarization and machine translation -- has not been thoroughly explored. Ad text generation significantly differs from these tasks owing to the text style and requirements. This research explores the relationship between diversity and ad quality in ad text generation by considering multiple factors, such as diversity-enhancing methods, their hyperparameters, input-output formats, and the models.
AdParaphrase: Paraphrase Dataset for Analyzing Linguistic Features toward Generating Attractive Ad Texts
Feb 07, 2025



Effective linguistic choices that attract potential customers play crucial roles in advertising success. This study aims to explore the linguistic features of ad texts that influence human preferences. Although the creation of attractive ad texts is an active area of research, progress in understanding the specific linguistic features that affect attractiveness is hindered by several obstacles. First, human preferences are complex and influenced by multiple factors, including their content, such as brand names, and their linguistic styles, making analysis challenging. Second, publicly available ad text datasets that include human preferences are lacking, such as ad performance metrics and human feedback, which reflect people's interests. To address these problems, we present AdParaphrase, a paraphrase dataset that contains human preferences for pairs of ad texts that are semantically equivalent but differ in terms of wording and style. This dataset allows for preference analysis that focuses on the differences in linguistic features. Our analysis revealed that ad texts preferred by human judges have higher fluency, longer length, more nouns, and use of bracket symbols. Furthermore, we demonstrate that an ad text-generation model that considers these findings significantly improves the attractiveness of a given text. The dataset is publicly available at: https://github.com/CyberAgentAILab/AdParaphrase.
FaithCAMERA: Construction of a Faithful Dataset for Ad Text Generation
Oct 04, 2024



In ad text generation (ATG), desirable ad text is both faithful and informative. That is, it should be faithful to the input document, while at the same time containing important information that appeals to potential customers. The existing evaluation data, CAMERA (arXiv:2309.12030), is suitable for evaluating informativeness, as it consists of reference ad texts created by ad creators. However, these references often include information unfaithful to the input, which is a notable obstacle in promoting ATG research. In this study, we collaborate with in-house ad creators to refine the CAMERA references and develop an alternative ATG evaluation dataset called FaithCAMERA, in which the faithfulness of references is guaranteed. Using FaithCAMERA, we can evaluate how well existing methods for improving faithfulness can generate informative ad text while maintaining faithfulness. Our experiments show that removing training data that contains unfaithful entities improves the faithfulness and informativeness at the entity level, but decreases both at the sentence level. This result suggests that for future ATG research, it is essential not only to scale the training data but also to ensure their faithfulness. Our dataset will be publicly available.
Cross-lingual Transfer or Machine Translation? On Data Augmentation for Monolingual Semantic Textual Similarity
Mar 08, 2024Learning better sentence embeddings leads to improved performance for natural language understanding tasks including semantic textual similarity (STS) and natural language inference (NLI). As prior studies leverage large-scale labeled NLI datasets for fine-tuning masked language models to yield sentence embeddings, task performance for languages other than English is often left behind. In this study, we directly compared two data augmentation techniques as potential solutions for monolingual STS: (a) cross-lingual transfer that exploits English resources alone as training data to yield non-English sentence embeddings as zero-shot inference, and (b) machine translation that coverts English data into pseudo non-English training data in advance. In our experiments on monolingual STS in Japanese and Korean, we find that the two data techniques yield performance on par. Rather, we find a superiority of the Wikipedia domain over the NLI domain for these languages, in contrast to prior studies that focused on NLI as training data. Combining our findings, we demonstrate that the cross-lingual transfer of Wikipedia data exhibits improved performance, and that native Wikipedia data can further improve performance for monolingual STS.
CAMERA: A Multimodal Dataset and Benchmark for Ad Text Generation
Sep 21, 2023



In response to the limitations of manual online ad production, significant research has been conducted in the field of automatic ad text generation (ATG). However, comparing different methods has been challenging because of the lack of benchmarks encompassing the entire field and the absence of well-defined problem sets with clear model inputs and outputs. To address these challenges, this paper aims to advance the field of ATG by introducing a redesigned task and constructing a benchmark. Specifically, we defined ATG as a cross-application task encompassing various aspects of the Internet advertising. As part of our contribution, we propose a first benchmark dataset, CA Multimodal Evaluation for Ad Text GeneRAtion (CAMERA), carefully designed for ATG to be able to leverage multi-modal information and conduct an industry-wise evaluation. Furthermore, we demonstrate the usefulness of our proposed benchmark through evaluation experiments using multiple baseline models, which vary in terms of the type of pre-trained language model used and the incorporation of multi-modal information. We also discuss the current state of the task and the future challenges.
Natural Language Generation for Advertising: A Survey
Jun 22, 2023



Natural language generation methods have emerged as effective tools to help advertisers increase the number of online advertisements they produce. This survey entails a review of the research trends on this topic over the past decade, from template-based to extractive and abstractive approaches using neural networks. Additionally, key challenges and directions revealed through the survey, including metric optimization, faithfulness, diversity, multimodality, and the development of benchmark datasets, are discussed.