 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Relationship Between Diversity and Quality in Ad Text Generation
May 22, 2025

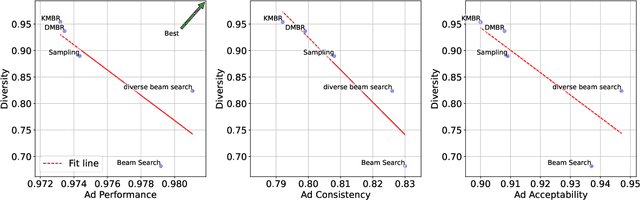
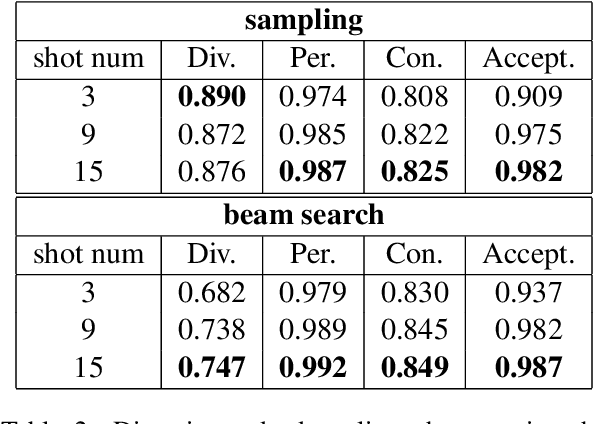
In natural language generation for advertising, creating diverse and engaging ad texts is crucial for capturing a broad audience and avoiding advertising fatigue. Regardless of the importance of diversity, the impact of the diversity-enhancing methods in ad text generation -- mainly tested on tasks such as summarization and machine translation -- has not been thoroughly explored. Ad text generation significantly differs from these tasks owing to the text style and requirements. This research explores the relationship between diversity and ad quality in ad text generation by considering multiple factors, such as diversity-enhancing methods, their hyperparameters, input-output formats, and the models.
FaithCAMERA: Construction of a Faithful Dataset for Ad Text Generation
Oct 04, 2024



In ad text generation (ATG), desirable ad text is both faithful and informative. That is, it should be faithful to the input document, while at the same time containing important information that appeals to potential customers. The existing evaluation data, CAMERA (arXiv:2309.12030), is suitable for evaluating informativeness, as it consists of reference ad texts created by ad creators. However, these references often include information unfaithful to the input, which is a notable obstacle in promoting ATG research. In this study, we collaborate with in-house ad creators to refine the CAMERA references and develop an alternative ATG evaluation dataset called FaithCAMERA, in which the faithfulness of references is guaranteed. Using FaithCAMERA, we can evaluate how well existing methods for improving faithfulness can generate informative ad text while maintaining faithfulness. Our experiments show that removing training data that contains unfaithful entities improves the faithfulness and informativeness at the entity level, but decreases both at the sentence level. This result suggests that for future ATG research, it is essential not only to scale the training data but also to ensure their faithfulness. Our dataset will be publicly available.
Cross-lingual Transfer or Machine Translation? On Data Augmentation for Monolingual Semantic Textual Similarity
Mar 08, 2024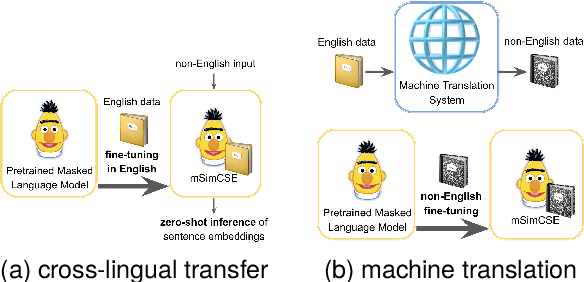
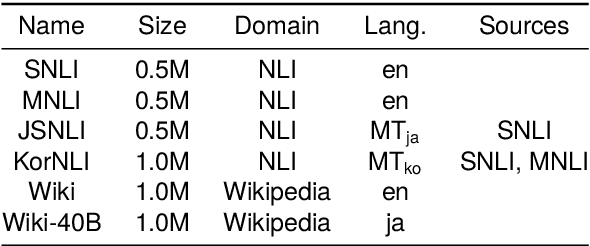
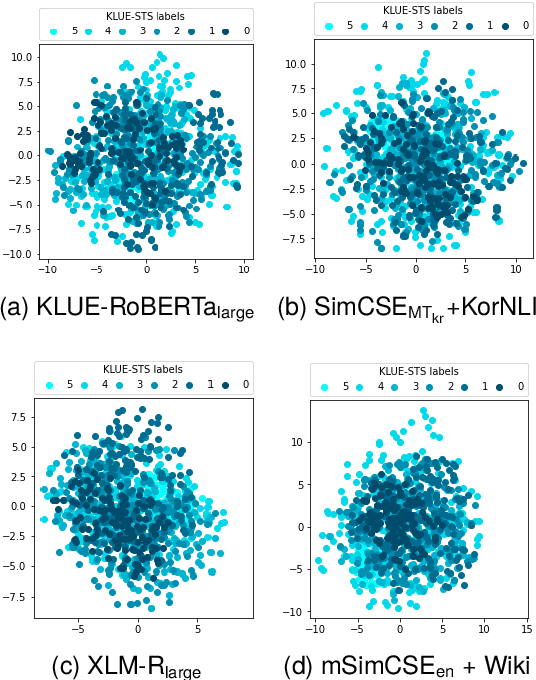
Learning better sentence embeddings leads to improved performance for natural language understanding tasks including semantic textual similarity (STS) and natural language inference (NLI). As prior studies leverage large-scale labeled NLI datasets for fine-tuning masked language models to yield sentence embeddings, task performance for languages other than English is often left behind. In this study, we directly compared two data augmentation techniques as potential solutions for monolingual STS: (a) cross-lingual transfer that exploits English resources alone as training data to yield non-English sentence embeddings as zero-shot inference, and (b) machine translation that coverts English data into pseudo non-English training data in advance. In our experiments on monolingual STS in Japanese and Korean, we find that the two data techniques yield performance on par. Rather, we find a superiority of the Wikipedia domain over the NLI domain for these languages, in contrast to prior studies that focused on NLI as training data. Combining our findings, we demonstrate that the cross-lingual transfer of Wikipedia data exhibits improved performance, and that native Wikipedia data can further improve performance for monolingual STS.
CAMERA: A Multimodal Dataset and Benchmark for Ad Text Generation
Sep 21, 2023



In response to the limitations of manual online ad production, significant research has been conducted in the field of automatic ad text generation (ATG). However, comparing different methods has been challenging because of the lack of benchmarks encompassing the entire field and the absence of well-defined problem sets with clear model inputs and outputs. To address these challenges, this paper aims to advance the field of ATG by introducing a redesigned task and constructing a benchmark. Specifically, we defined ATG as a cross-application task encompassing various aspects of the Internet advertising. As part of our contribution, we propose a first benchmark dataset, CA Multimodal Evaluation for Ad Text GeneRAtion (CAMERA), carefully designed for ATG to be able to leverage multi-modal information and conduct an industry-wise evaluation. Furthermore, we demonstrate the usefulness of our proposed benchmark through evaluation experiments using multiple baseline models, which vary in terms of the type of pre-trained language model used and the incorporation of multi-modal information. We also discuss the current state of the task and the future challenges.