 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNodes Are Early, Edges Are Late: Probing Diagram Representations in Large Vision-Language Models
Mar 03, 2026Large vision-language models (LVLMs) demonstrate strong performance on diagram understanding benchmarks, yet they still struggle with understanding relationships between elements, particularly those represented by nodes and directed edges (e.g., arrows and lines). To investigate the underlying causes of this limitation, we probe the internal representation of LVLMs using a carefully constructed synthetic diagram dataset based on directed graphs. Our probing experiments reveal that edge information is not linearly separable in the vision encoder and becomes linearly encoded only in the text tokens in the language model. In contrast, node information and global structural features are already linearly encoded in individual hidden states of the vision encoder. These findings suggest that the stage at which linearly separable representations are formed varies depending on the type of visual information. In particular, the delayed emergence of edge representations may help explain why LVLMs struggle with relational understanding, such as interpreting edge directions, which require more abstract, compositionally integrated processes.
Exploring the Relationship Between Diversity and Quality in Ad Text Generation
May 22, 2025

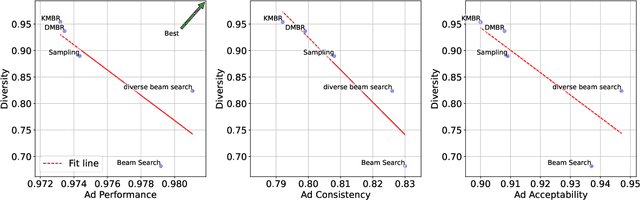
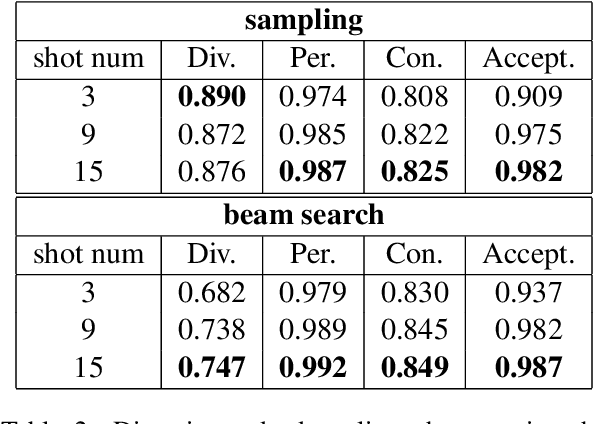
In natural language generation for advertising, creating diverse and engaging ad texts is crucial for capturing a broad audience and avoiding advertising fatigue. Regardless of the importance of diversity, the impact of the diversity-enhancing methods in ad text generation -- mainly tested on tasks such as summarization and machine translation -- has not been thoroughly explored. Ad text generation significantly differs from these tasks owing to the text style and requirements. This research explores the relationship between diversity and ad quality in ad text generation by considering multiple factors, such as diversity-enhancing methods, their hyperparameters, input-output formats, and the models.
Think-to-Talk or Talk-to-Think? When LLMs Come Up with an Answer in Multi-Step Reasoning
Dec 02, 2024



This study investigates the internal reasoning mechanism of language models during symbolic multi-step reasoning, motivated by the question of whether chain-of-thought (CoT) outputs are faithful to the model's internals. Specifically, we inspect when they internally determine their answers, particularly before or after CoT begins, to determine whether models follow a post-hoc "think-to-talk" mode or a step-by-step "talk-to-think" mode of explanation. Through causal probing experiments in controlled arithmetic reasoning tasks, we found systematic internal reasoning patterns across models; for example, simple subproblems are solved before CoT begins, and more complicated multi-hop calculations are performed during CoT.
First Heuristic Then Rational: Dynamic Use of Heuristics in Language Model Reasoning
Jun 23, 2024



Multi-step reasoning is widely adopted in the community to explore the better performance of language models (LMs). We report on the systematic strategy that LMs use in this process. Our controlled experiments reveal that LMs rely more heavily on heuristics, such as lexical overlap, in the earlier stages of reasoning when more steps are required to reach an answer. Conversely, as LMs progress closer to the final answer, their reliance on heuristics decreases. This suggests that LMs track only a limited number of future steps and dynamically combine heuristic strategies with logical ones in tasks involving multi-step reasoning.
Empirical Investigation of Neural Symbolic Reasoning Strategies
Feb 16, 2023Neural reasoning accuracy improves when generating intermediate reasoning steps. However, the source of this improvement is yet unclear. Here, we investigate and factorize the benefit of generating intermediate steps for symbolic reasoning. Specifically, we decompose the reasoning strategy w.r.t. step granularity and chaining strategy. With a purely symbolic numerical reasoning dataset (e.g., A=1, B=3, C=A+3, C?), we found that the choice of reasoning strategies significantly affects the performance, with the gap becoming even larger as the extrapolation length becomes longer. Surprisingly, we also found that certain configurations lead to nearly perfect performance, even in the case of length extrapolation. Our results indicate the importance of further exploring effective strategies for neural reasoning models.
Do Deep Neural Networks Capture Compositionality in Arithmetic Reasoning?
Feb 15, 2023Compositionality is a pivotal property of symbolic reasoning. However, how well recent neural models capture compositionality remains underexplored in the symbolic reasoning tasks. This study empirically addresses this question by systematically examining recently published pre-trained seq2seq models with a carefully controlled dataset of multi-hop arithmetic symbolic reasoning. We introduce a skill tree on compositionality in arithmetic symbolic reasoning that defines the hierarchical levels of complexity along with three compositionality dimensions: systematicity, productivity, and substitutivity. Our experiments revealed that among the three types of composition, the models struggled most with systematicity, performing poorly even with relatively simple compositions. That difficulty was not resolved even after training the models with intermediate reasoning steps.