 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink-to-Talk or Talk-to-Think? When LLMs Come Up with an Answer in Multi-Step Reasoning
Dec 02, 2024



This study investigates the internal reasoning mechanism of language models during symbolic multi-step reasoning, motivated by the question of whether chain-of-thought (CoT) outputs are faithful to the model's internals. Specifically, we inspect when they internally determine their answers, particularly before or after CoT begins, to determine whether models follow a post-hoc "think-to-talk" mode or a step-by-step "talk-to-think" mode of explanation. Through causal probing experiments in controlled arithmetic reasoning tasks, we found systematic internal reasoning patterns across models; for example, simple subproblems are solved before CoT begins, and more complicated multi-hop calculations are performed during CoT.
First Heuristic Then Rational: Dynamic Use of Heuristics in Language Model Reasoning
Jun 23, 2024



Multi-step reasoning is widely adopted in the community to explore the better performance of language models (LMs). We report on the systematic strategy that LMs use in this process. Our controlled experiments reveal that LMs rely more heavily on heuristics, such as lexical overlap, in the earlier stages of reasoning when more steps are required to reach an answer. Conversely, as LMs progress closer to the final answer, their reliance on heuristics decreases. This suggests that LMs track only a limited number of future steps and dynamically combine heuristic strategies with logical ones in tasks involving multi-step reasoning.
TNF: Tri-branch Neural Fusion for Multimodal Medical Data Classification
Mar 10, 2024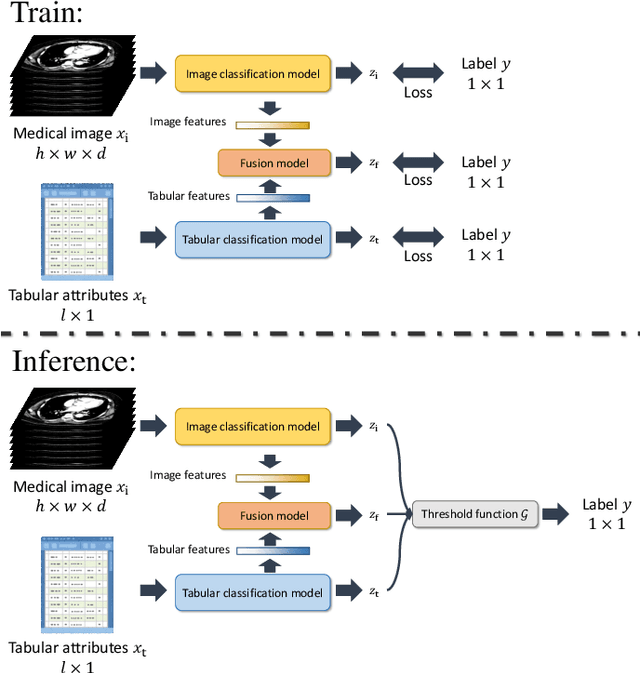
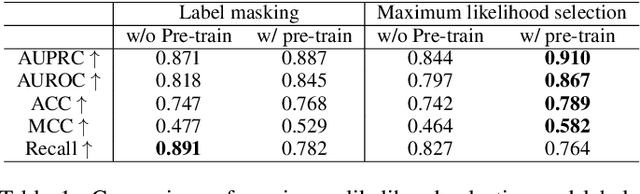

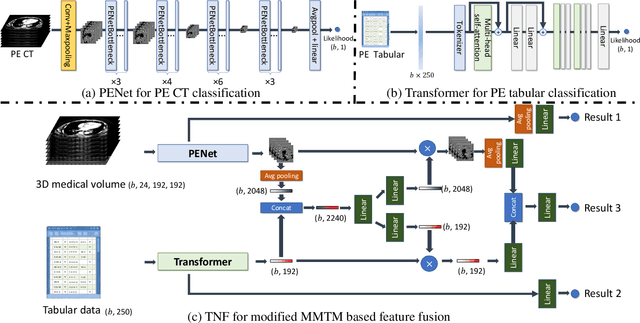
This paper presents a Tri-branch Neural Fusion (TNF) approach designed for classifying multimodal medical images and tabular data. It also introduces two solutions to address the challenge of label inconsistency in multimodal classification. Traditional methods in multi-modality medical data classification often rely on single-label approaches, typically merging features from two distinct input modalities. This becomes problematic when features are mutually exclusive or labels differ across modalities, leading to reduced accuracy. To overcome this, our TNF approach implements a tri-branch framework that manages three separate outputs: one for image modality, another for tabular modality, and a third hybrid output that fuses both image and tabular data. The final decision is made through an ensemble method that integrates likelihoods from all three branches. We validate the effectiveness of TNF through extensive experiments, which illustrate its superiority over traditional fusion and ensemble methods in various convolutional neural networks and transformer-based architectures across multiple datasets.
WeaveNet for Approximating Two-sided Matching Problems
Oct 19, 2023Matching, a task to optimally assign limited resources under constraints, is a fundamental technology for society. The task potentially has various objectives, conditions, and constraints; however, the efficient neural network architecture for matching is underexplored. This paper proposes a novel graph neural network (GNN), \textit{WeaveNet}, designed for bipartite graphs. Since a bipartite graph is generally dense, general GNN architectures lose node-wise information by over-smoothing when deeply stacked. Such a phenomenon is undesirable for solving matching problems. WeaveNet avoids it by preserving edge-wise information while passing messages densely to reach a better solution. To evaluate the model, we approximated one of the \textit{strongly NP-hard} problems, \textit{fair stable matching}. Despite its inherent difficulties and the network's general purpose design, our model reached a comparative performance with state-of-the-art algorithms specially designed for stable matching for small numbers of agents.
Edge-Selective Feature Weaving for Point Cloud Matching
Feb 08, 2022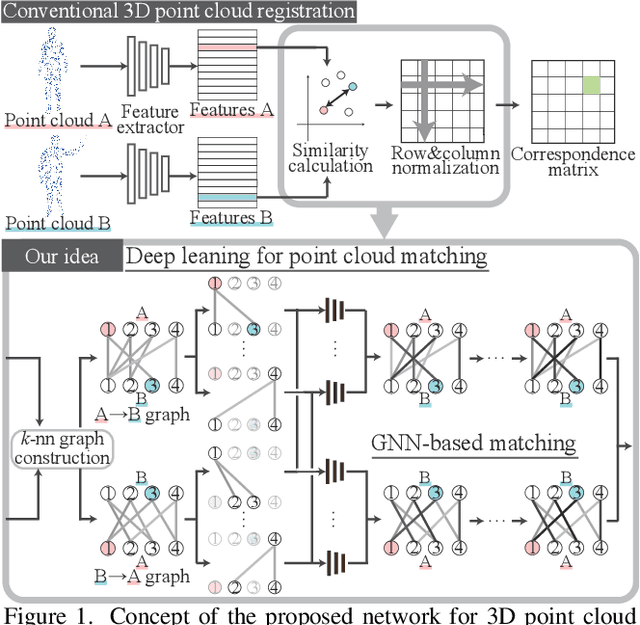
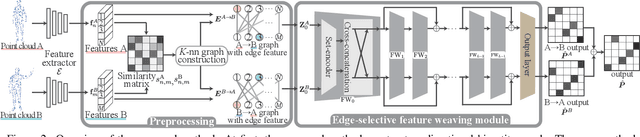
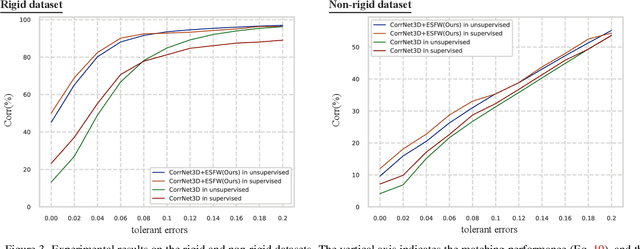

This paper tackles the problem of accurately matching the points of two 3D point clouds. Most conventional methods improve their performance by extracting representative features from each point via deep-learning-based algorithms. On the other hand, the correspondence calculation between the extracted features has not been examined in depth, and non-trainable algorithms (e.g. the Sinkhorn algorithm) are frequently applied. As a result, the extracted features may be forcibly fitted to a non-trainable algorithm. Furthermore, the extracted features frequently contain stochastically unavoidable errors, which degrades the matching accuracy. In this paper, instead of using a non-trainable algorithm, we propose a differentiable matching network that can be jointly optimized with the feature extraction procedure. Our network first constructs graphs with edges connecting the points of each point cloud and then extracts discriminative edge features by using two main components: a shared set-encoder and an edge-selective cross-concatenation. These components enable us to symmetrically consider two point clouds and to extract discriminative edge features, respectively. By using the extracted discriminative edge features, our network can accurately calculate the correspondence between points. Our experimental results show that the proposed network can significantly improve the performance of point cloud matching. Our code is available at https://github.com/yanarin/ESFW