 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Handle a Non-Gregorian Calendar?
Sep 04, 2025Temporal reasoning and knowledge are essential capabilities for language models (LMs). While much prior work has analyzed and improved temporal reasoning in LMs, most studies have focused solely on the Gregorian calendar. However, many non-Gregorian systems, such as the Japanese, Hijri, and Hebrew calendars, are in active use and reflect culturally grounded conceptions of time. If and how well current LMs can accurately handle such non-Gregorian calendars has not been evaluated so far. Here, we present a systematic evaluation of how well open-source LMs handle one such non-Gregorian system: the Japanese calendar. For our evaluation, we create datasets for four tasks that require both temporal knowledge and temporal reasoning. Evaluating a range of English-centric and Japanese-centric LMs, we find that some models can perform calendar conversions, but even Japanese-centric models struggle with Japanese-calendar arithmetic and with maintaining consistency across calendars. Our results highlight the importance of developing LMs that are better equipped for culture-specific calendar understanding.
Rubrik's Cube: Testing a New Rubric for Evaluating Explanations on the CUBE dataset
Mar 31, 2025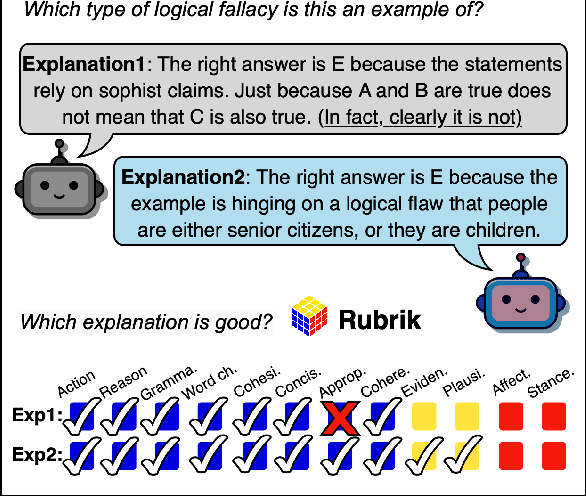

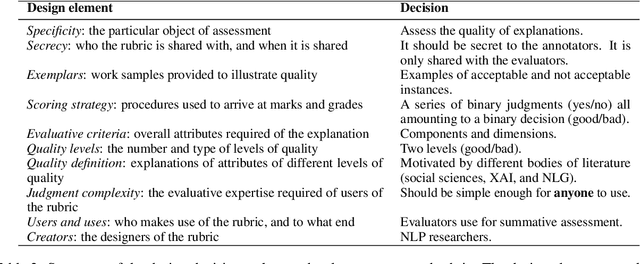
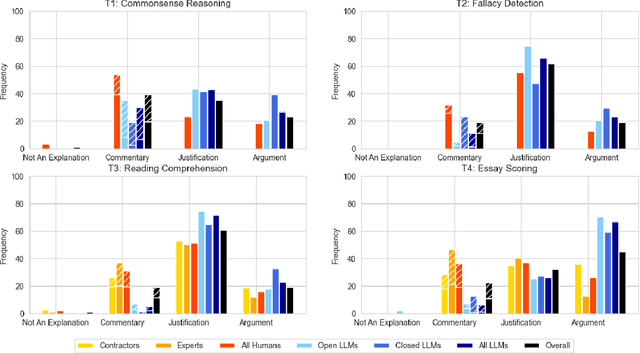
The performance and usability of Large-Language Models (LLMs) are driving their use in explanation generation tasks. However, despite their widespread adoption, LLM explanations have been found to be unreliable, making it difficult for users to distinguish good from bad explanations. To address this issue, we present Rubrik's CUBE, an education-inspired rubric and a dataset of 26k explanations, written and later quality-annotated using the rubric by both humans and six open- and closed-source LLMs. The CUBE dataset focuses on two reasoning and two language tasks, providing the necessary diversity for us to effectively test our proposed rubric. Using Rubrik, we find that explanations are influenced by both task and perceived difficulty. Low quality stems primarily from a lack of conciseness in LLM-generated explanations, rather than cohesion and word choice. The full dataset, rubric, and code will be made available upon acceptance.
Weight-based Analysis of Detokenization in Language Models: Understanding the First Stage of Inference Without Inference
Jan 27, 2025



According to the stages-of-inference hypothesis, early layers of language models map their subword-tokenized input, which does not necessarily correspond to a linguistically meaningful segmentation, to more meaningful representations that form the model's ``inner vocabulary''. Prior analysis of this detokenization stage has predominantly relied on probing and interventions such as path patching, which involve selecting particular inputs, choosing a subset of components that will be patched, and then observing changes in model behavior. Here, we show that several important aspects of the detokenization stage can be understood purely by analyzing model weights, without performing any model inference steps. Specifically, we introduce an analytical decomposition of first-layer attention in GPT-2. Our decomposition yields interpretable terms that quantify the relative contributions of position-related, token-related, and mixed effects. By focusing on terms in this decomposition, we discover weight-based explanations of attention bias toward close tokens and attention for detokenization.
Think-to-Talk or Talk-to-Think? When LLMs Come Up with an Answer in Multi-Step Reasoning
Dec 02, 2024



This study investigates the internal reasoning mechanism of language models during symbolic multi-step reasoning, motivated by the question of whether chain-of-thought (CoT) outputs are faithful to the model's internals. Specifically, we inspect when they internally determine their answers, particularly before or after CoT begins, to determine whether models follow a post-hoc "think-to-talk" mode or a step-by-step "talk-to-think" mode of explanation. Through causal probing experiments in controlled arithmetic reasoning tasks, we found systematic internal reasoning patterns across models; for example, simple subproblems are solved before CoT begins, and more complicated multi-hop calculations are performed during CoT.
Self-Training Meets Consistency: Improving LLMs' Reasoning With Consistency-Driven Rationale Evaluation
Nov 22, 2024



Self-training approach for large language models (LLMs) improves reasoning abilities by training the models on their self-generated rationales. Previous approaches have labeled rationales that produce correct answers for a given question as appropriate for training. However, a single measure risks misjudging rationale quality, leading the models to learn flawed reasoning patterns. To address this issue, we propose CREST (Consistency-driven Rationale Evaluation for Self-Training), a self-training framework that further evaluates each rationale through follow-up questions and leverages this evaluation to guide its training. Specifically, we introduce two methods: (1) filtering out rationales that frequently result in incorrect answers on follow-up questions and (2) preference learning based on mixed preferences from rationale evaluation results of both original and follow-up questions. Experiments on three question-answering datasets using open LLMs show that CREST not only improves the logical robustness and correctness of rationales but also improves reasoning abilities compared to previous self-training approaches.
Empirical Analysis of Large Vision-Language Models against Goal Hijacking via Visual Prompt Injection
Aug 07, 2024We explore visual prompt injection (VPI) that maliciously exploits the ability of large vision-language models (LVLMs) to follow instructions drawn onto the input image. We propose a new VPI method, "goal hijacking via visual prompt injection" (GHVPI), that swaps the execution task of LVLMs from an original task to an alternative task designated by an attacker. The quantitative analysis indicates that GPT-4V is vulnerable to the GHVPI and demonstrates a notable attack success rate of 15.8%, which is an unignorable security risk. Our analysis also shows that successful GHVPI requires high character recognition capability and instruction-following ability in LVLMs.
LLM-jp: A Cross-organizational Project for the Research and Development of Fully Open Japanese LLMs
Jul 04, 2024



This paper introduces LLM-jp, a cross-organizational project for the research and development of Japanese large language models (LLMs). LLM-jp aims to develop open-source and strong Japanese LLMs, and as of this writing, more than 1,500 participants from academia and industry are working together for this purpose. This paper presents the background of the establishment of LLM-jp, summaries of its activities, and technical reports on the LLMs developed by LLM-jp. For the latest activities, visit https://llm-jp.nii.ac.jp/en/.
First Heuristic Then Rational: Dynamic Use of Heuristics in Language Model Reasoning
Jun 23, 2024



Multi-step reasoning is widely adopted in the community to explore the better performance of language models (LMs). We report on the systematic strategy that LMs use in this process. Our controlled experiments reveal that LMs rely more heavily on heuristics, such as lexical overlap, in the earlier stages of reasoning when more steps are required to reach an answer. Conversely, as LMs progress closer to the final answer, their reliance on heuristics decreases. This suggests that LMs track only a limited number of future steps and dynamically combine heuristic strategies with logical ones in tasks involving multi-step reasoning.
The Curse of Popularity: Popular Entities have Catastrophic Side Effects when Deleting Knowledge from Language Models
Jun 10, 2024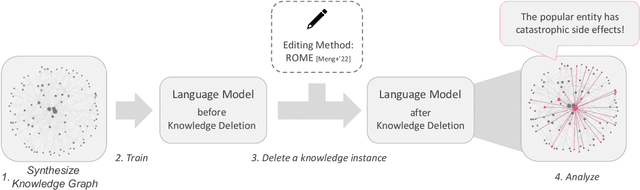
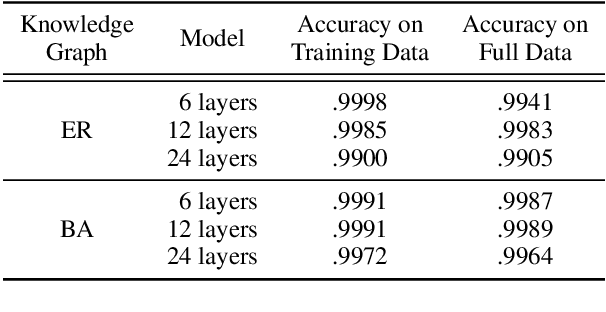
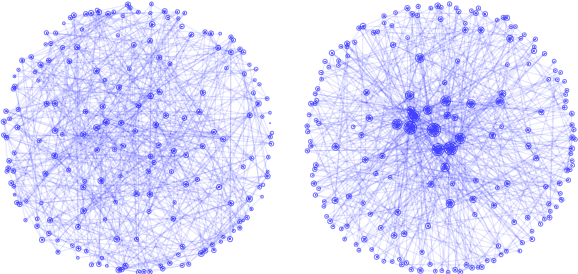
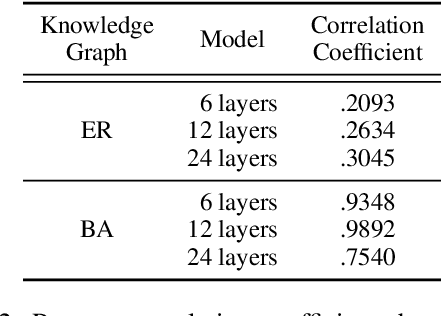
Language models (LMs) encode world knowledge in their internal parameters through training. However, LMs may learn personal and confidential information from the training data, leading to privacy concerns such as data leakage. Therefore, research on knowledge deletion from LMs is essential. This study focuses on the knowledge stored in LMs and analyzes the relationship between the side effects of knowledge deletion and the entities related to the knowledge. Our findings reveal that deleting knowledge related to popular entities can have catastrophic side effects. Furthermore, this research is the first to analyze knowledge deletion in models trained on synthetic knowledge graphs, indicating a new direction for controlled experiments.
ACORN: Aspect-wise Commonsense Reasoning Explanation Evaluation
May 08, 2024



Evaluating free-text explanations is a multifaceted, subjective, and labor-intensive task. Large language models (LLMs) present an appealing alternative due to their potential for consistency, scalability, and cost-efficiency. In this work, we present ACORN, a new dataset of 3,500 free-text explanations and aspect-wise quality ratings, and use it to gain insights into how LLMs evaluate explanations. We observed that replacing one of the human ratings sometimes maintained, but more often lowered the inter-annotator agreement across different settings and quality aspects, suggesting that their judgments are not always consistent with human raters. We further quantified this difference by comparing the correlation between LLM-generated ratings with majority-voted human ratings across different quality aspects. With the best system, Spearman's rank correlation ranged between 0.53 to 0.95, averaging 0.72 across aspects, indicating moderately high but imperfect alignment. Finally, we considered the alternative of using an LLM as an additional rater when human raters are scarce, and measured the correlation between majority-voted labels with a limited human pool and LLMs as an additional rater, compared to the original gold labels. While GPT-4 improved the outcome when there were only two human raters, in all other observed cases, LLMs were neutral to detrimental when there were three or more human raters. We publicly release the dataset to support future improvements in LLM-in-the-loop evaluation here: https://github.com/a-brassard/ACORN.