 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentCoMa: A Compositional Benchmark Mixing Commonsense and Mathematical Reasoning in Real-World Scenarios
Aug 27, 2025Large Language Models (LLMs) have achieved high accuracy on complex commonsense and mathematical problems that involve the composition of multiple reasoning steps. However, current compositional benchmarks testing these skills tend to focus on either commonsense or math reasoning, whereas LLM agents solving real-world tasks would require a combination of both. In this work, we introduce an Agentic Commonsense and Math benchmark (AgentCoMa), where each compositional task requires a commonsense reasoning step and a math reasoning step. We test it on 61 LLMs of different sizes, model families, and training strategies. We find that LLMs can usually solve both steps in isolation, yet their accuracy drops by ~30% on average when the two are combined. This is a substantially greater performance gap than the one we observe in prior compositional benchmarks that combine multiple steps of the same reasoning type. In contrast, non-expert human annotators can solve the compositional questions and the individual steps in AgentCoMa with similarly high accuracy. Furthermore, we conduct a series of interpretability studies to better understand the performance gap, examining neuron patterns, attention maps and membership inference. Our work underscores a substantial degree of model brittleness in the context of mixed-type compositional reasoning and offers a test bed for future improvement.
Think-to-Talk or Talk-to-Think? When LLMs Come Up with an Answer in Multi-Step Reasoning
Dec 02, 2024



This study investigates the internal reasoning mechanism of language models during symbolic multi-step reasoning, motivated by the question of whether chain-of-thought (CoT) outputs are faithful to the model's internals. Specifically, we inspect when they internally determine their answers, particularly before or after CoT begins, to determine whether models follow a post-hoc "think-to-talk" mode or a step-by-step "talk-to-think" mode of explanation. Through causal probing experiments in controlled arithmetic reasoning tasks, we found systematic internal reasoning patterns across models; for example, simple subproblems are solved before CoT begins, and more complicated multi-hop calculations are performed during CoT.
ACORN: Aspect-wise Commonsense Reasoning Explanation Evaluation
May 08, 2024



Evaluating free-text explanations is a multifaceted, subjective, and labor-intensive task. Large language models (LLMs) present an appealing alternative due to their potential for consistency, scalability, and cost-efficiency. In this work, we present ACORN, a new dataset of 3,500 free-text explanations and aspect-wise quality ratings, and use it to gain insights into how LLMs evaluate explanations. We observed that replacing one of the human ratings sometimes maintained, but more often lowered the inter-annotator agreement across different settings and quality aspects, suggesting that their judgments are not always consistent with human raters. We further quantified this difference by comparing the correlation between LLM-generated ratings with majority-voted human ratings across different quality aspects. With the best system, Spearman's rank correlation ranged between 0.53 to 0.95, averaging 0.72 across aspects, indicating moderately high but imperfect alignment. Finally, we considered the alternative of using an LLM as an additional rater when human raters are scarce, and measured the correlation between majority-voted labels with a limited human pool and LLMs as an additional rater, compared to the original gold labels. While GPT-4 improved the outcome when there were only two human raters, in all other observed cases, LLMs were neutral to detrimental when there were three or more human raters. We publicly release the dataset to support future improvements in LLM-in-the-loop evaluation here: https://github.com/a-brassard/ACORN.
Chat Translation Error Detection for Assisting Cross-lingual Communications
Aug 02, 2023In this paper, we describe the development of a communication support system that detects erroneous translations to facilitate crosslingual communications due to the limitations of current machine chat translation methods. We trained an error detector as the baseline of the system and constructed a new Japanese-English bilingual chat corpus, BPersona-chat, which comprises multiturn colloquial chats augmented with crowdsourced quality ratings. The error detector can serve as an encouraging foundation for more advanced erroneous translation detection systems.
Empirical Investigation of Neural Symbolic Reasoning Strategies
Feb 16, 2023Neural reasoning accuracy improves when generating intermediate reasoning steps. However, the source of this improvement is yet unclear. Here, we investigate and factorize the benefit of generating intermediate steps for symbolic reasoning. Specifically, we decompose the reasoning strategy w.r.t. step granularity and chaining strategy. With a purely symbolic numerical reasoning dataset (e.g., A=1, B=3, C=A+3, C?), we found that the choice of reasoning strategies significantly affects the performance, with the gap becoming even larger as the extrapolation length becomes longer. Surprisingly, we also found that certain configurations lead to nearly perfect performance, even in the case of length extrapolation. Our results indicate the importance of further exploring effective strategies for neural reasoning models.
Do Deep Neural Networks Capture Compositionality in Arithmetic Reasoning?
Feb 15, 2023Compositionality is a pivotal property of symbolic reasoning. However, how well recent neural models capture compositionality remains underexplored in the symbolic reasoning tasks. This study empirically addresses this question by systematically examining recently published pre-trained seq2seq models with a carefully controlled dataset of multi-hop arithmetic symbolic reasoning. We introduce a skill tree on compositionality in arithmetic symbolic reasoning that defines the hierarchical levels of complexity along with three compositionality dimensions: systematicity, productivity, and substitutivity. Our experiments revealed that among the three types of composition, the models struggled most with systematicity, performing poorly even with relatively simple compositions. That difficulty was not resolved even after training the models with intermediate reasoning steps.
Context Limitations Make Neural Language Models More Human-Like
May 23, 2022


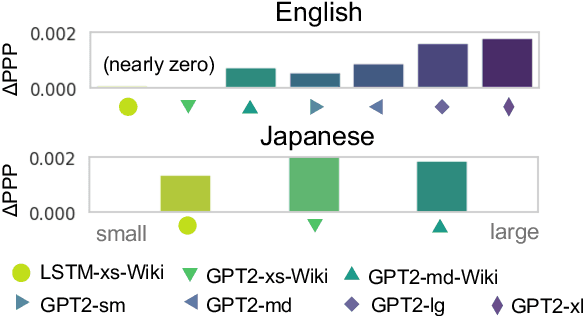
Do modern natural language processing (NLP) models exhibit human-like language processing? How can they be made more human-like? These questions are motivated by psycholinguistic studies for understanding human language processing as well as engineering efforts. In this study, we demonstrate the discrepancies in context access between modern neural language models (LMs) and humans in incremental sentence processing. Additional context limitation was needed to make LMs better simulate human reading behavior. Our analyses also showed that human-LM gaps in memory access are associated with specific syntactic constructions; incorporating additional syntactic factors into LMs' context access could enhance their cognitive plausibility.
COPA-SSE: Semi-structured Explanations for Commonsense Reasoning
Jan 19, 2022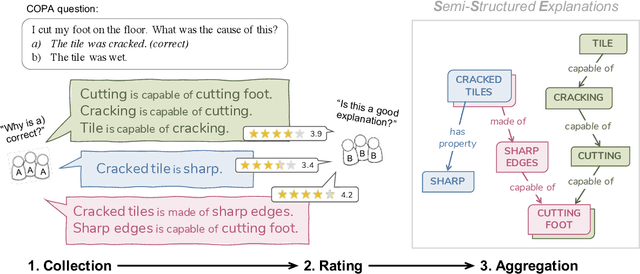

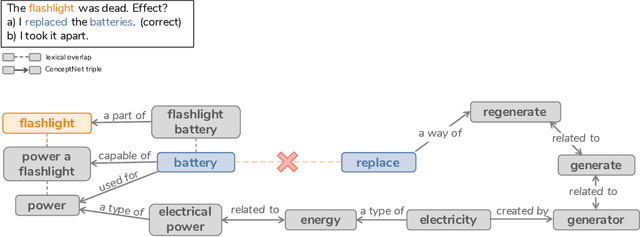

We present Semi-Structured Explanations for COPA (COPA-SSE), a new crowdsourced dataset of 9,747 semi-structured, English common sense explanations for COPA questions. The explanations are formatted as a set of triple-like common sense statements with ConceptNet relations but freely written concepts. This semi-structured format strikes a balance between the high quality but low coverage of structured data and the lower quality but high coverage of free-form crowdsourcing. Each explanation also includes a set of human-given quality ratings. With their familiar format, the explanations are geared towards commonsense reasoners operating on knowledge graphs and serve as a starting point for ongoing work on improving such systems.
Learning to Learn to be Right for the Right Reasons
Apr 23, 2021


Improving model generalization on held-out data is one of the core objectives in commonsense reasoning. Recent work has shown that models trained on the dataset with superficial cues tend to perform well on the easy test set with superficial cues but perform poorly on the hard test set without superficial cues. Previous approaches have resorted to manual methods of encouraging models not to overfit to superficial cues. While some of the methods have improved performance on hard instances, they also lead to degraded performance on easy instances. Here, we propose to explicitly learn a model that does well on both the easy test set with superficial cues and hard test set without superficial cues. Using a meta-learning objective, we learn such a model that improves performance on both the easy test set and the hard test set. By evaluating our models on Choice of Plausible Alternatives (COPA) and Commonsense Explanation, we show that our proposed method leads to improved performance on both the easy test set and the hard test set upon which we observe up to 16.5 percentage points improvement over the baseline.
Diamonds in the Rough: Generating Fluent Sentences from Early-Stage Drafts for Academic Writing Assistance
Oct 21, 2019
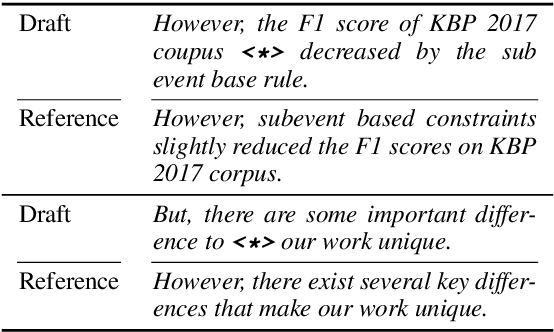


The writing process consists of several stages such as drafting, revising, editing, and proofreading. Studies on writing assistance, such as grammatical error correction (GEC), have mainly focused on sentence editing and proofreading, where surface-level issues such as typographical, spelling, or grammatical errors should be corrected. We broaden this focus to include the earlier revising stage, where sentences require adjustment to the information included or major rewriting and propose Sentence-level Revision (SentRev) as a new writing assistance task. Well-performing systems in this task can help inexperienced authors by producing fluent, complete sentences given their rough, incomplete drafts. We build a new freely available crowdsourced evaluation dataset consisting of incomplete sentences authored by non-native writers paired with their final versions extracted from published academic papers for developing and evaluating SentRev models. We also establish baseline performance on SentRev using our newly built evaluation dataset.