 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMQM-Chat: Multidimensional Quality Metrics for Chat Translation
Aug 29, 2024The complexities of chats pose significant challenges for machine translation models. Recognizing the need for a precise evaluation metric to address the issues of chat translation, this study introduces Multidimensional Quality Metrics for Chat Translation (MQM-Chat). Through the experiments of five models using MQM-Chat, we observed that all models generated certain fundamental errors, while each of them has different shortcomings, such as omission, overly correcting ambiguous source content, and buzzword issues, resulting in the loss of stylized information. Our findings underscore the effectiveness of MQM-Chat in evaluating chat translation, emphasizing the importance of stylized content and dialogue consistency for future studies.
An Investigation of Warning Erroneous Chat Translations in Cross-lingual Communication
Aug 28, 2024



The complexities of chats pose significant challenges for machine translation models. Recognizing the need for a precise evaluation metric to address the issues of chat translation, this study introduces Multidimensional Quality Metrics for Chat Translation (MQM-Chat). Through the experiments of five models using MQM-Chat, we observed that all models generated certain fundamental errors, while each of them has different shortcomings, such as omission, overly correcting ambiguous source content, and buzzword issues, resulting in the loss of stylized information. Our findings underscore the effectiveness of MQM-Chat in evaluating chat translation, emphasizing the importance of stylized content and dialogue consistency for future studies.
Chat Translation Error Detection for Assisting Cross-lingual Communications
Aug 02, 2023In this paper, we describe the development of a communication support system that detects erroneous translations to facilitate crosslingual communications due to the limitations of current machine chat translation methods. We trained an error detector as the baseline of the system and constructed a new Japanese-English bilingual chat corpus, BPersona-chat, which comprises multiturn colloquial chats augmented with crowdsourced quality ratings. The error detector can serve as an encouraging foundation for more advanced erroneous translation detection systems.
PheMT: A Phenomenon-wise Dataset for Machine Translation Robustness on User-Generated Contents
Nov 04, 2020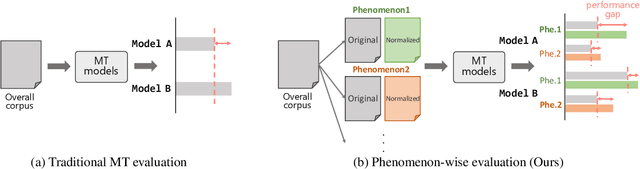

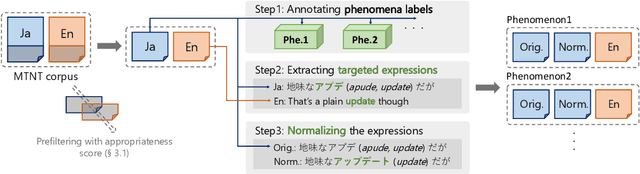

Neural Machine Translation (NMT) has shown drastic improvement in its quality when translating clean input, such as text from the news domain. However, existing studies suggest that NMT still struggles with certain kinds of input with considerable noise, such as User-Generated Contents (UGC) on the Internet. To make better use of NMT for cross-cultural communication, one of the most promising directions is to develop a model that correctly handles these expressions. Though its importance has been recognized, it is still not clear as to what creates the great gap in performance between the translation of clean input and that of UGC. To answer the question, we present a new dataset, PheMT, for evaluating the robustness of MT systems against specific linguistic phenomena in Japanese-English translation. Our experiments with the created dataset revealed that not only our in-house models but even widely used off-the-shelf systems are greatly disturbed by the presence of certain phenomena.
Embeddings of Label Components for Sequence Labeling: A Case Study of Fine-grained Named Entity Recognition
Jun 04, 2020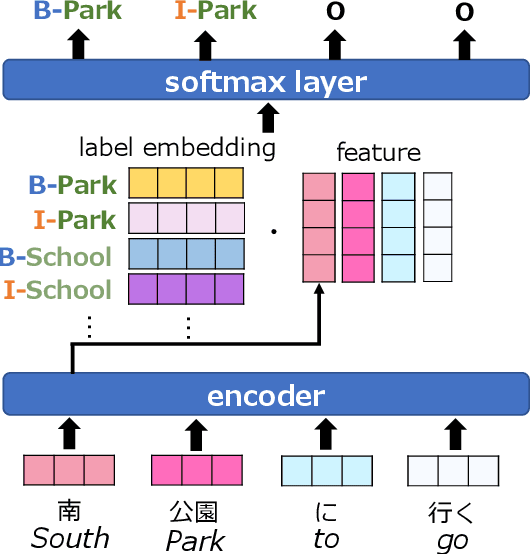
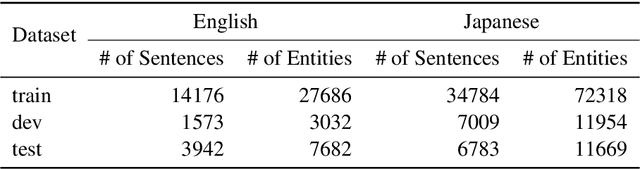
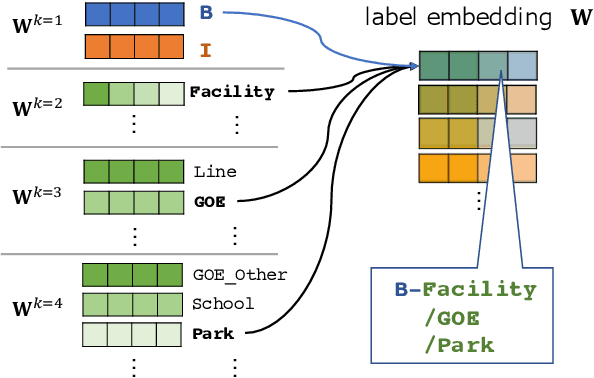
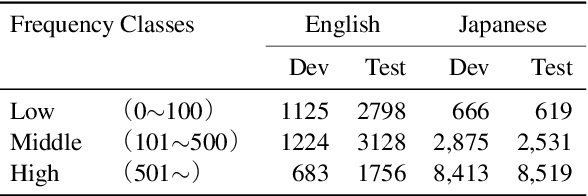
In general, the labels used in sequence labeling consist of different types of elements. For example, IOB-format entity labels, such as B-Person and I-Person, can be decomposed into span (B and I) and type information (Person). However, while most sequence labeling models do not consider such label components, the shared components across labels, such as Person, can be beneficial for label prediction. In this work, we propose to integrate label component information as embeddings into models. Through experiments on English and Japanese fine-grained named entity recognition, we demonstrate that the proposed method improves performance, especially for instances with low-frequency labels.
cvpaper.challenge in 2016: Futuristic Computer Vision through 1,600 Papers Survey
Jul 20, 2017



The paper gives futuristic challenges disscussed in the cvpaper.challenge. In 2015 and 2016, we thoroughly study 1,600+ papers in several conferences/journals such as CVPR/ICCV/ECCV/NIPS/PAMI/IJCV.
Collaborative Descriptors: Convolutional Maps for Preprocessing
May 10, 2017


The paper presents a novel concept for collaborative descriptors between deeply learned and hand-crafted features. To achieve this concept, we apply convolutional maps for pre-processing, namely the convovlutional maps are used as input of hand-crafted features. We recorded an increase in the performance rate of +17.06 % (multi-class object recognition) and +24.71 % (car detection) from grayscale input to convolutional maps. Although the framework is straight-forward, the concept should be inherited for an improved representation.
Changing Fashion Cultures
Mar 23, 2017


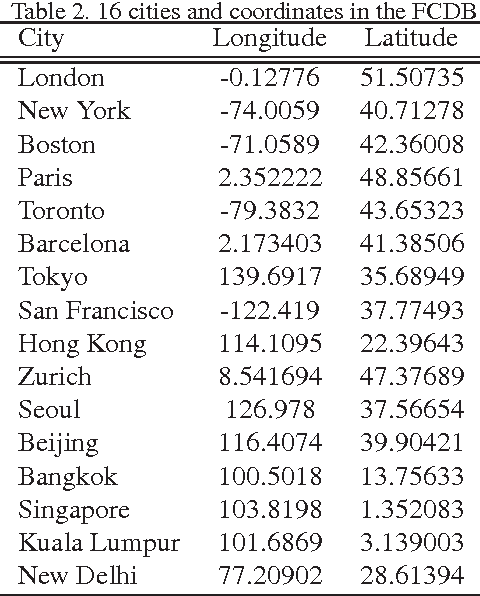
The paper presents a novel concept that analyzes and visualizes worldwide fashion trends. Our goal is to reveal cutting-edge fashion trends without displaying an ordinary fashion style. To achieve the fashion-based analysis, we created a new fashion culture database (FCDB), which consists of 76 million geo-tagged images in 16 cosmopolitan cities. By grasping a fashion trend of mixed fashion styles,the paper also proposes an unsupervised fashion trend descriptor (FTD) using a fashion descriptor, a codeword vetor, and temporal analysis. To unveil fashion trends in the FCDB, the temporal analysis in FTD effectively emphasizes consecutive features between two different times. In experiments, we clearly show the analysis of fashion trends and fashion-based city similarity. As the result of large-scale data collection and an unsupervised analyzer, the proposed approach achieves world-level fashion visualization in a time series. The code, model, and FCDB will be publicly available after the construction of the project page.
cvpaper.challenge in 2015 - A review of CVPR2015 and DeepSurvey
May 26, 2016
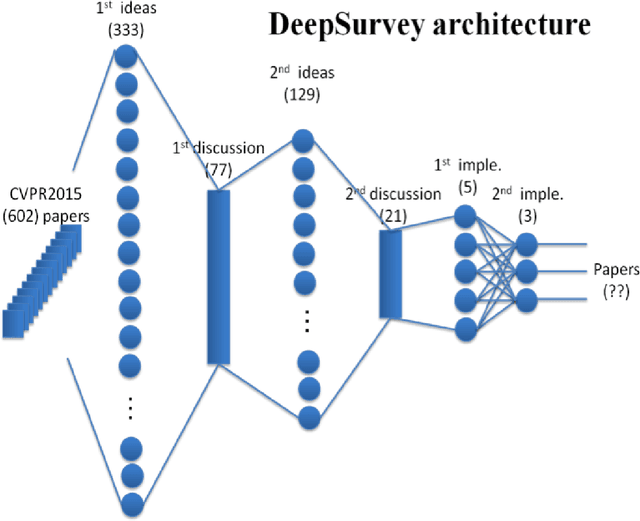
The "cvpaper.challenge" is a group composed of members from AIST, Tokyo Denki Univ. (TDU), and Univ. of Tsukuba that aims to systematically summarize papers on computer vision, pattern recognition, and related fields. For this particular review, we focused on reading the ALL 602 conference papers presented at the CVPR2015, the premier annual computer vision event held in June 2015, in order to grasp the trends in the field. Further, we are proposing "DeepSurvey" as a mechanism embodying the entire process from the reading through all the papers, the generation of ideas, and to the writing of paper.