 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePheMT: A Phenomenon-wise Dataset for Machine Translation Robustness on User-Generated Contents
Paper and Code
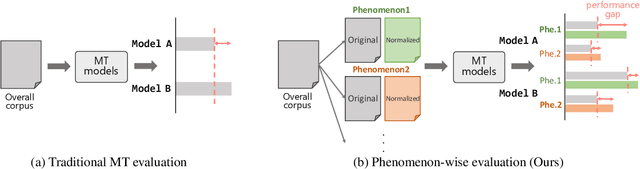

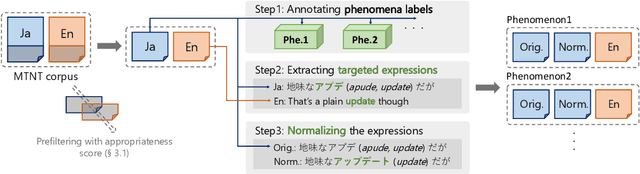

Neural Machine Translation (NMT) has shown drastic improvement in its quality when translating clean input, such as text from the news domain. However, existing studies suggest that NMT still struggles with certain kinds of input with considerable noise, such as User-Generated Contents (UGC) on the Internet. To make better use of NMT for cross-cultural communication, one of the most promising directions is to develop a model that correctly handles these expressions. Though its importance has been recognized, it is still not clear as to what creates the great gap in performance between the translation of clean input and that of UGC. To answer the question, we present a new dataset, PheMT, for evaluating the robustness of MT systems against specific linguistic phenomena in Japanese-English translation. Our experiments with the created dataset revealed that not only our in-house models but even widely used off-the-shelf systems are greatly disturbed by the presence of certain phenomena.