 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Capacity of a Large-scale Masked Language Model to Recognize Grammatical Errors
Aug 27, 2021
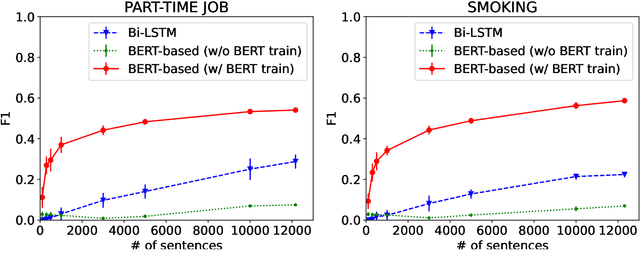
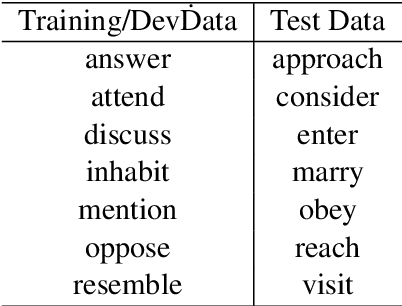
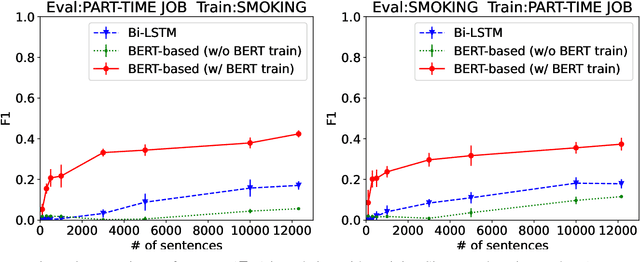
In this paper, we explore the capacity of a language model-based method for grammatical error detection in detail. We first show that 5 to 10% of training data are enough for a BERT-based error detection method to achieve performance equivalent to a non-language model-based method can achieve with the full training data; recall improves much faster with respect to training data size in the BERT-based method than in the non-language model method while precision behaves similarly. These suggest that (i) the BERT-based method should have a good knowledge of grammar required to recognize certain types of error and that (ii) it can transform the knowledge into error detection rules by fine-tuning with a few training samples, which explains its high generalization ability in grammatical error detection. We further show with pseudo error data that it actually exhibits such nice properties in learning rules for recognizing various types of error. Finally, based on these findings, we explore a cost-effective method for detecting grammatical errors with feedback comments explaining relevant grammatical rules to learners.
PheMT: A Phenomenon-wise Dataset for Machine Translation Robustness on User-Generated Contents
Nov 04, 2020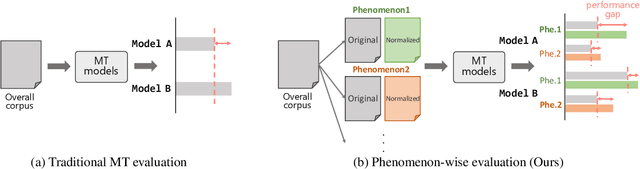

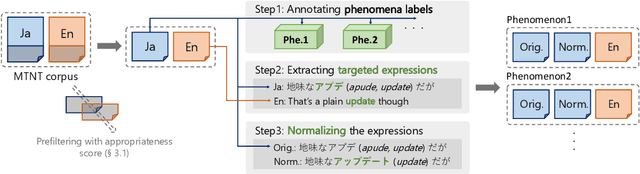

Neural Machine Translation (NMT) has shown drastic improvement in its quality when translating clean input, such as text from the news domain. However, existing studies suggest that NMT still struggles with certain kinds of input with considerable noise, such as User-Generated Contents (UGC) on the Internet. To make better use of NMT for cross-cultural communication, one of the most promising directions is to develop a model that correctly handles these expressions. Though its importance has been recognized, it is still not clear as to what creates the great gap in performance between the translation of clean input and that of UGC. To answer the question, we present a new dataset, PheMT, for evaluating the robustness of MT systems against specific linguistic phenomena in Japanese-English translation. Our experiments with the created dataset revealed that not only our in-house models but even widely used off-the-shelf systems are greatly disturbed by the presence of certain phenomena.
Evaluation Criteria for Instance-based Explanation
Jun 08, 2020

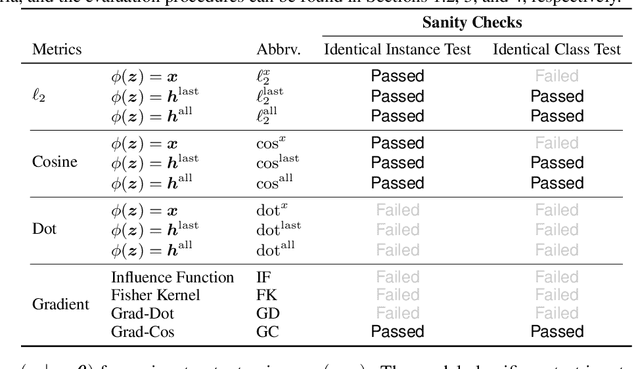

Explaining predictions made by complex machine learning models helps users understand and accept the predicted outputs with confidence. Instance-based explanation provides such help by identifying relevant instances as evidence to support a model's prediction result. To find relevant instances, several relevance metrics have been proposed. In this study, we ask the following research question: "Do the metrics actually work in practice?" To address this question, we propose two sanity check criteria that valid metrics should pass, and two additional criteria to evaluate the practical utility of the metrics. All criteria are designed in terms of whether the metric can pick up instances of desirable properties that the users expect in practice. Through experiments, we obtained two insights. First, some popular relevance metrics do not pass sanity check criteria. Second, some metrics based on cosine similarity perform better than other metrics, which would be recommended choices in practice. We also analyze why some metrics are successful and why some are not. We expect our insights to help further researches such as developing better explanation methods or designing new evaluation criteria.
Suspicious News Detection Using Micro Blog Text
Oct 27, 2018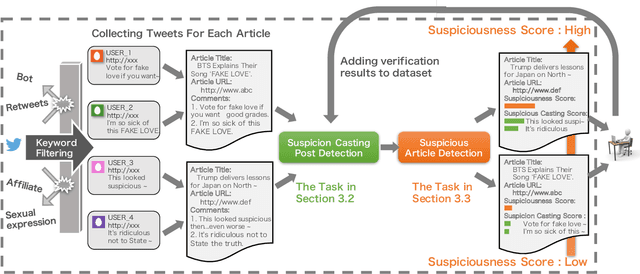
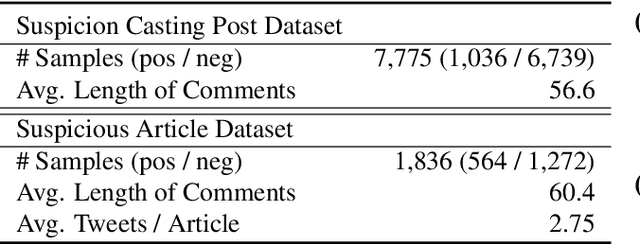
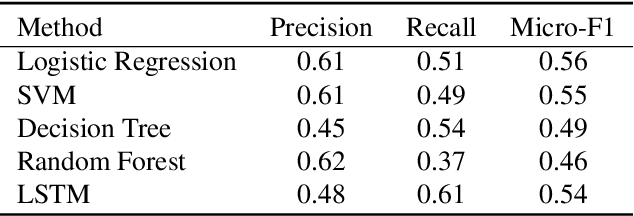
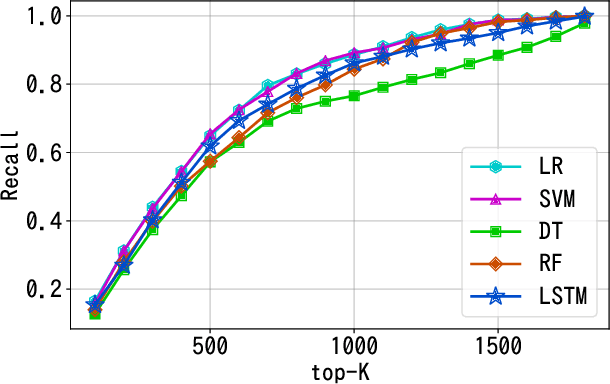
We present a new task, suspicious news detection using micro blog text. This task aims to support human experts to detect suspicious news articles to be verified, which is costly but a crucial step before verifying the truthfulness of the articles. Specifically, in this task, given a set of posts on SNS referring to a news article, the goal is to judge whether the article is to be verified or not. For this task, we create a publicly available dataset in Japanese and provide benchmark results by using several basic machine learning techniques. Experimental results show that our models can reduce the cost of manual fact-checking process.
Other Topics You May Also Agree or Disagree: Modeling Inter-Topic Preferences using Tweets and Matrix Factorization
Apr 26, 2017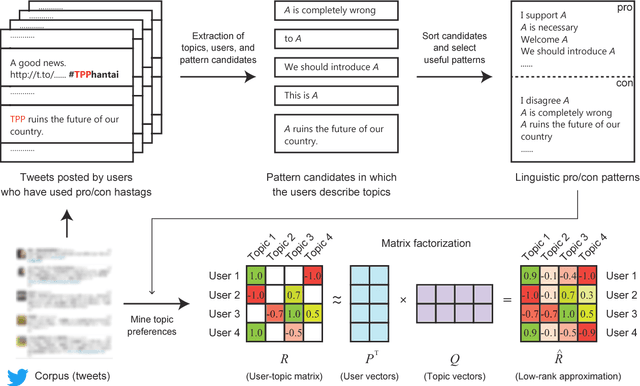

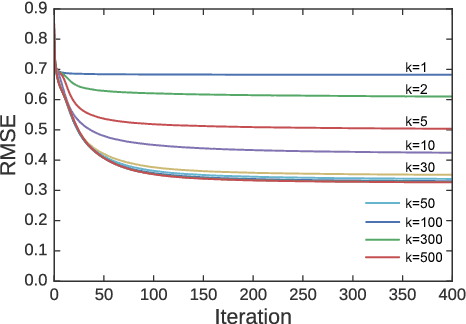

We present in this paper our approach for modeling inter-topic preferences of Twitter users: for example, those who agree with the Trans-Pacific Partnership (TPP) also agree with free trade. This kind of knowledge is useful not only for stance detection across multiple topics but also for various real-world applications including public opinion surveys, electoral predictions, electoral campaigns, and online debates. In order to extract users' preferences on Twitter, we design linguistic patterns in which people agree and disagree about specific topics (e.g., "A is completely wrong"). By applying these linguistic patterns to a collection of tweets, we extract statements agreeing and disagreeing with various topics. Inspired by previous work on item recommendation, we formalize the task of modeling inter-topic preferences as matrix factorization: representing users' preferences as a user-topic matrix and mapping both users and topics onto a latent feature space that abstracts the preferences. Our experimental results demonstrate both that our proposed approach is useful in predicting missing preferences of users and that the latent vector representations of topics successfully encode inter-topic preferences.