 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Lexical Semantic Shift via Unbalanced Optimal Transport
Dec 17, 2024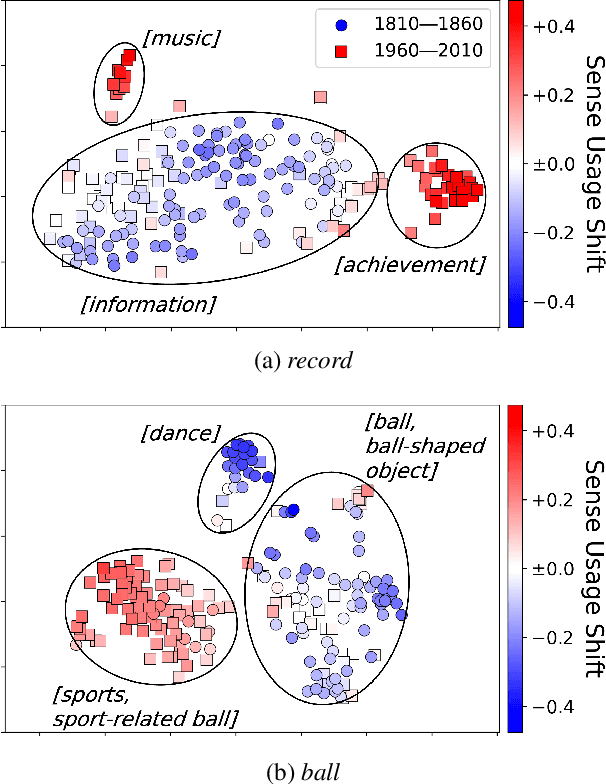



Lexical semantic change detection aims to identify shifts in word meanings over time. While existing methods using embeddings from a diachronic corpus pair estimate the degree of change for target words, they offer limited insight into changes at the level of individual usage instances. To address this, we apply Unbalanced Optimal Transport (UOT) to sets of contextualized word embeddings, capturing semantic change through the excess and deficit in the alignment between usage instances. In particular, we propose Sense Usage Shift (SUS), a measure that quantifies changes in the usage frequency of a word sense at each usage instance. By leveraging SUS, we demonstrate that several challenges in semantic change detection can be addressed in a unified manner, including quantifying instance-level semantic change and word-level tasks such as measuring the magnitude of semantic change and the broadening or narrowing of meaning.
Contextualized Word Vector-based Methods for Discovering Semantic Differences with No Training nor Word Alignment
May 19, 2023



In this paper, we propose methods for discovering semantic differences in words appearing in two corpora based on the norms of contextualized word vectors. The key idea is that the coverage of meanings is reflected in the norm of its mean word vector. The proposed methods do not require the assumptions concerning words and corpora for comparison that the previous methods do. All they require are to compute the mean vector of contextualized word vectors and its norm for each word type. Nevertheless, they are (i) robust for the skew in corpus size; (ii) capable of detecting semantic differences in infrequent words; and (iii) effective in pinpointing word instances that have a meaning missing in one of the two corpora for comparison. We show these advantages for native and non-native English corpora and also for historical corpora.
Exploring the Capacity of a Large-scale Masked Language Model to Recognize Grammatical Errors
Aug 27, 2021
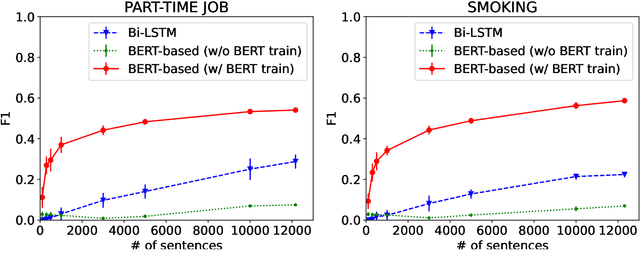
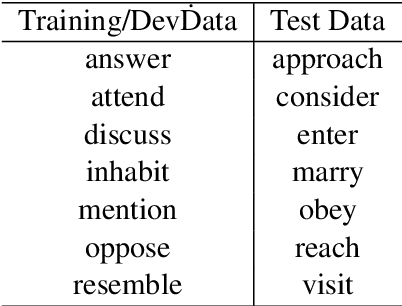
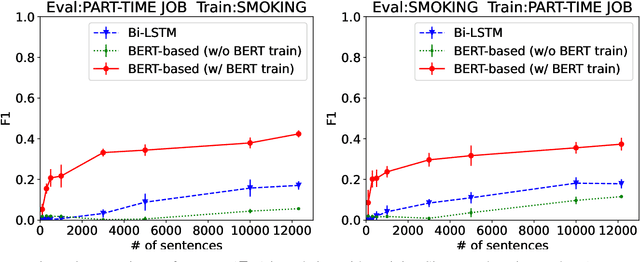
In this paper, we explore the capacity of a language model-based method for grammatical error detection in detail. We first show that 5 to 10% of training data are enough for a BERT-based error detection method to achieve performance equivalent to a non-language model-based method can achieve with the full training data; recall improves much faster with respect to training data size in the BERT-based method than in the non-language model method while precision behaves similarly. These suggest that (i) the BERT-based method should have a good knowledge of grammar required to recognize certain types of error and that (ii) it can transform the knowledge into error detection rules by fine-tuning with a few training samples, which explains its high generalization ability in grammatical error detection. We further show with pseudo error data that it actually exhibits such nice properties in learning rules for recognizing various types of error. Finally, based on these findings, we explore a cost-effective method for detecting grammatical errors with feedback comments explaining relevant grammatical rules to learners.
Cross-Corpora Evaluation and Analysis of Grammatical Error Correction Models --- Is Single-Corpus Evaluation Enough?
Apr 05, 2019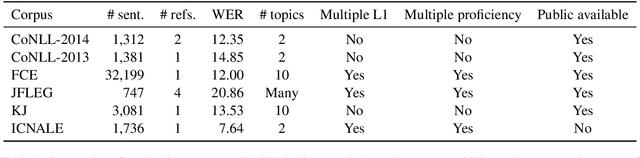



This study explores the necessity of performing cross-corpora evaluation for grammatical error correction (GEC) models. GEC models have been previously evaluated based on a single commonly applied corpus: the CoNLL-2014 benchmark. However, the evaluation remains incomplete because the task difficulty varies depending on the test corpus and conditions such as the proficiency levels of the writers and essay topics. To overcome this limitation, we evaluate the performance of several GEC models, including NMT-based (LSTM, CNN, and transformer) and an SMT-based model, against various learner corpora (CoNLL-2013, CoNLL-2014, FCE, JFLEG, ICNALE, and KJ). Evaluation results reveal that the models' rankings considerably vary depending on the corpus, indicating that single-corpus evaluation is insufficient for GEC models.