 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring Affinity between Attention-Head Weight Subspaces via the Projection Kernel
Jan 15, 2026Understanding relationships between attention heads is essential for interpreting the internal structure of Transformers, yet existing metrics do not capture this structure well. We focus on the subspaces spanned by attention-head weight matrices and quantify head-to-head relationships using the Projection Kernel (PK), a principal-angle-based measure of subspace similarity. Experiments show that PK reproduces known head-to-head interactions on the IOI task more clearly than prior metrics such as the Composition Score. We further introduce a framework to quantify the informativeness of PK distributions by comparing them with a reference distribution derived from random orthogonal subspaces. As an application, we analyze a directed graph constructed from PK and show that, in GPT2-small, L4H7 acts as a hub by functioning as an identity head.
Revealing Language Model Trajectories via Kullback-Leibler Divergence
May 21, 2025A recently proposed method enables efficient estimation of the KL divergence between language models, including models with different architectures, by assigning coordinates based on log-likelihood vectors. To better understand the behavior of this metric, we systematically evaluate KL divergence across a wide range of conditions using publicly available language models. Our analysis covers comparisons between pretraining checkpoints, fine-tuned and base models, and layers via the logit lens. We find that trajectories of language models, as measured by KL divergence, exhibit a spiral structure during pretraining and thread-like progressions across layers. Furthermore, we show that, in terms of diffusion exponents, model trajectories in the log-likelihood space are more constrained than those in weight space.
Likelihood Variance as Text Importance for Resampling Texts to Map Language Models
May 21, 2025We address the computational cost of constructing a model map, which embeds diverse language models into a common space for comparison via KL divergence. The map relies on log-likelihoods over a large text set, making the cost proportional to the number of texts. To reduce this cost, we propose a resampling method that selects important texts with weights proportional to the variance of log-likelihoods across models for each text. Our method significantly reduces the number of required texts while preserving the accuracy of KL divergence estimates. Experiments show that it achieves comparable performance to uniform sampling with about half as many texts, and also facilitates efficient incorporation of new models into an existing map. These results enable scalable and efficient construction of language model maps.
Mapping 1,000+ Language Models via the Log-Likelihood Vector
Feb 22, 2025To compare autoregressive language models at scale, we propose using log-likelihood vectors computed on a predefined text set as model features. This approach has a solid theoretical basis: when treated as model coordinates, their squared Euclidean distance approximates the Kullback-Leibler divergence of text-generation probabilities. Our method is highly scalable, with computational cost growing linearly in both the number of models and text samples, and is easy to implement as the required features are derived from cross-entropy loss. Applying this method to over 1,000 language models, we constructed a "model map," providing a new perspective on large-scale model analysis.
Quantifying Lexical Semantic Shift via Unbalanced Optimal Transport
Dec 17, 2024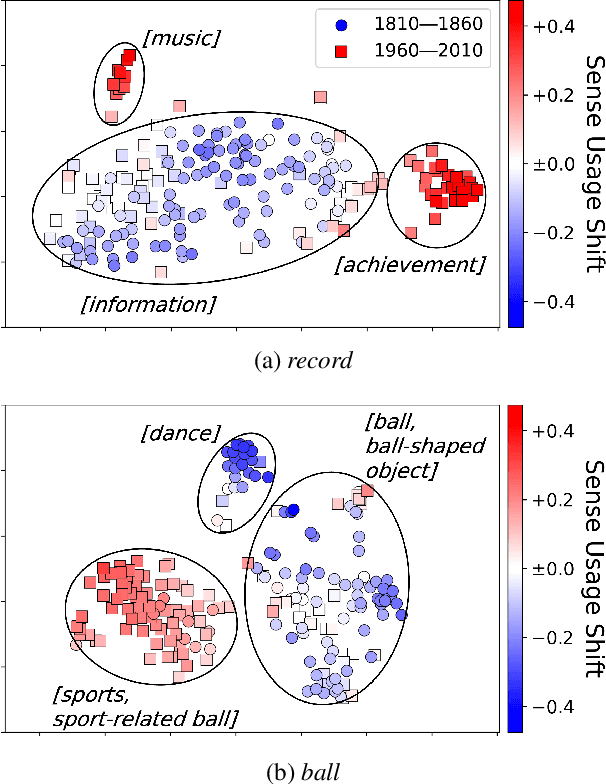



Lexical semantic change detection aims to identify shifts in word meanings over time. While existing methods using embeddings from a diachronic corpus pair estimate the degree of change for target words, they offer limited insight into changes at the level of individual usage instances. To address this, we apply Unbalanced Optimal Transport (UOT) to sets of contextualized word embeddings, capturing semantic change through the excess and deficit in the alignment between usage instances. In particular, we propose Sense Usage Shift (SUS), a measure that quantifies changes in the usage frequency of a word sense at each usage instance. By leveraging SUS, we demonstrate that several challenges in semantic change detection can be addressed in a unified manner, including quantifying instance-level semantic change and word-level tasks such as measuring the magnitude of semantic change and the broadening or narrowing of meaning.
Understanding Higher-Order Correlations Among Semantic Components in Embeddings
Sep 30, 2024Independent Component Analysis (ICA) is an effective method for interpreting the intrinsic geometric structure of embeddings as semantic components. While ICA theory assumes that embeddings can be linearly decomposed into independent components, real-world data often do not satisfy this assumption. Consequently, there are remaining non-independencies between the estimated components that ICA cannot eliminate. We quantified these non-independencies using higher-order correlations and demonstrated that when the higher-order correlation between two components is large, it indicates a strong semantic association between them. The entire structure was revealed through visualization using a maximum spanning tree of semantic components. These findings allow for further understanding of embeddings through ICA.
Norm of Mean Contextualized Embeddings Determines their Variance
Sep 17, 2024



Contextualized embeddings vary by context, even for the same token, and form a distribution in the embedding space. To analyze this distribution, we focus on the norm of the mean embedding and the variance of the embeddings. In this study, we first demonstrate that these values follow the well-known formula for variance in statistics and provide an efficient sequential computation method. Then, by observing embeddings from intermediate layers of several Transformer models, we found a strong trade-off relationship between the norm and the variance: as the mean embedding becomes closer to the origin, the variance increases. This trade-off is likely influenced by the layer normalization mechanism used in Transformer models. Furthermore, when the sets of token embeddings are treated as clusters, we show that the variance of the entire embedding set can theoretically be decomposed into the within-cluster variance and the between-cluster variance. We found experimentally that as the layers of Transformer models deepen, the embeddings move farther from the origin, the between-cluster variance relatively decreases, and the within-cluster variance relatively increases. These results are consistent with existing studies on the anisotropy of the embedding spaces across layers.
Shimo Lab at "Discharge Me!": Discharge Summarization by Prompt-Driven Concatenation of Electronic Health Record Sections
Jun 26, 2024In this paper, we present our approach to the shared task "Discharge Me!" at the BioNLP Workshop 2024. The primary goal of this task is to reduce the time and effort clinicians spend on writing detailed notes in the electronic health record (EHR). Participants develop a pipeline to generate the "Brief Hospital Course" and "Discharge Instructions" sections from the EHR. Our approach involves a first step of extracting the relevant sections from the EHR. We then add explanatory prompts to these sections and concatenate them with separate tokens to create the input text. To train a text generation model, we perform LoRA fine-tuning on the ClinicalT5-large model. On the final test data, our approach achieved a ROUGE-1 score of $0.394$, which is comparable to the top solutions.
Revisiting Cosine Similarity via Normalized ICA-transformed Embeddings
Jun 16, 2024Cosine similarity is widely used to measure the similarity between two embeddings, while interpretations based on angle and correlation coefficient are common. In this study, we focus on the interpretable axes of embeddings transformed by Independent Component Analysis (ICA), and propose a novel interpretation of cosine similarity as the sum of semantic similarities over axes. To investigate this, we first show experimentally that unnormalized embeddings contain norm-derived artifacts. We then demonstrate that normalized ICA-transformed embeddings exhibit sparsity, with a few large values in each axis and across embeddings, thereby enhancing interpretability by delineating clear semantic contributions. Finally, to validate our interpretation, we perform retrieval experiments using ideal embeddings with and without specific semantic components.
Predicting Drug-Gene Relations via Analogy Tasks with Word Embeddings
Jun 03, 2024Natural language processing (NLP) is utilized in a wide range of fields, where words in text are typically transformed into feature vectors called embeddings. BioConceptVec is a specific example of embeddings tailored for biology, trained on approximately 30 million PubMed abstracts using models such as skip-gram. Generally, word embeddings are known to solve analogy tasks through simple vector arithmetic. For instance, $\mathrm{\textit{king}} - \mathrm{\textit{man}} + \mathrm{\textit{woman}}$ predicts $\mathrm{\textit{queen}}$. In this study, we demonstrate that BioConceptVec embeddings, along with our own embeddings trained on PubMed abstracts, contain information about drug-gene relations and can predict target genes from a given drug through analogy computations. We also show that categorizing drugs and genes using biological pathways improves performance. Furthermore, we illustrate that vectors derived from known relations in the past can predict unknown future relations in datasets divided by year.