 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoftMatcha 2: A Fast and Soft Pattern Matcher for Trillion-Scale Corpora
Feb 11, 2026We present an ultra-fast and flexible search algorithm that enables search over trillion-scale natural language corpora in under 0.3 seconds while handling semantic variations (substitution, insertion, and deletion). Our approach employs string matching based on suffix arrays that scales well with corpus size. To mitigate the combinatorial explosion induced by the semantic relaxation of queries, our method is built on two key algorithmic ideas: fast exact lookup enabled by a disk-aware design, and dynamic corpus-aware pruning. We theoretically show that the proposed method suppresses exponential growth in the search space with respect to query length by leveraging statistical properties of natural language. In experiments on FineWeb-Edu (Lozhkov et al., 2024) (1.4T tokens), we show that our method achieves significantly lower search latency than existing methods: infini-gram (Liu et al., 2024), infini-gram mini (Xu et al., 2025), and SoftMatcha (Deguchi et al., 2025). As a practical application, we demonstrate that our method identifies benchmark contamination in training corpora, unidentified by existing approaches. We also provide an online demo of fast, soft search across corpora in seven languages.
SoftMatcha: A Soft and Fast Pattern Matcher for Billion-Scale Corpus Searches
Mar 05, 2025Researchers and practitioners in natural language processing and computational linguistics frequently observe and analyze the real language usage in large-scale corpora. For that purpose, they often employ off-the-shelf pattern-matching tools, such as grep, and keyword-in-context concordancers, which is widely used in corpus linguistics for gathering examples. Nonetheless, these existing techniques rely on surface-level string matching, and thus they suffer from the major limitation of not being able to handle orthographic variations and paraphrasing -- notable and common phenomena in any natural language. In addition, existing continuous approaches such as dense vector search tend to be overly coarse, often retrieving texts that are unrelated but share similar topics. Given these challenges, we propose a novel algorithm that achieves \emph{soft} (or semantic) yet efficient pattern matching by relaxing a surface-level matching with word embeddings. Our algorithm is highly scalable with respect to the size of the corpus text utilizing inverted indexes. We have prepared an efficient implementation, and we provide an accessible web tool. Our experiments demonstrate that the proposed method (i) can execute searches on billion-scale corpora in less than a second, which is comparable in speed to surface-level string matching and dense vector search; (ii) can extract harmful instances that semantically match queries from a large set of English and Japanese Wikipedia articles; and (iii) can be effectively applied to corpus-linguistic analyses of Latin, a language with highly diverse inflections.
TAID: Temporally Adaptive Interpolated Distillation for Efficient Knowledge Transfer in Language Models
Jan 29, 2025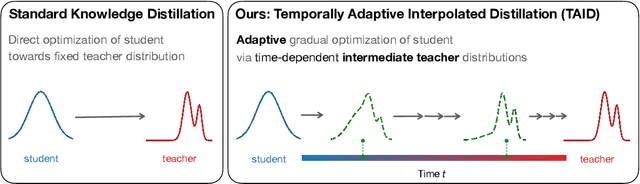
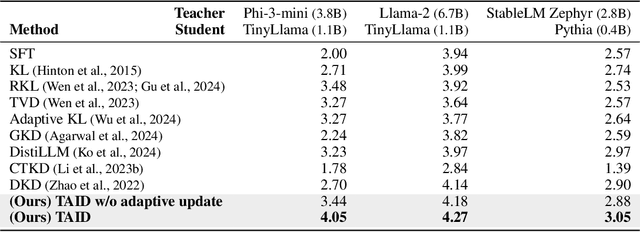
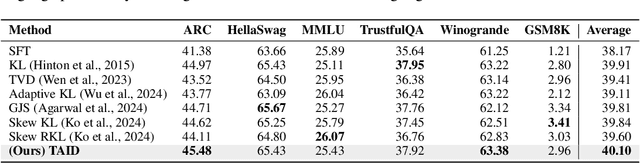
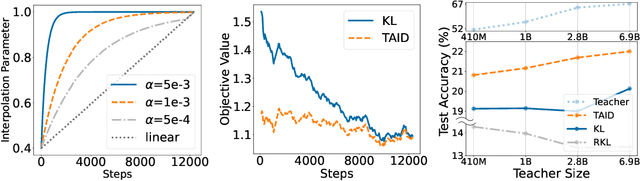
Causal language models have demonstrated remarkable capabilities, but their size poses significant challenges for deployment in resource-constrained environments. Knowledge distillation, a widely-used technique for transferring knowledge from a large teacher model to a small student model, presents a promising approach for model compression. A significant remaining issue lies in the major differences between teacher and student models, namely the substantial capacity gap, mode averaging, and mode collapse, which pose barriers during distillation. To address these issues, we introduce $\textit{Temporally Adaptive Interpolated Distillation (TAID)}$, a novel knowledge distillation approach that dynamically interpolates student and teacher distributions through an adaptive intermediate distribution, gradually shifting from the student's initial distribution towards the teacher's distribution. We provide a theoretical analysis demonstrating TAID's ability to prevent mode collapse and empirically show its effectiveness in addressing the capacity gap while balancing mode averaging and mode collapse. Our comprehensive experiments demonstrate TAID's superior performance across various model sizes and architectures in both instruction tuning and pre-training scenarios. Furthermore, we showcase TAID's practical impact by developing two state-of-the-art compact foundation models: $\texttt{TAID-LLM-1.5B}$ for language tasks and $\texttt{TAID-VLM-2B}$ for vision-language tasks. These results demonstrate TAID's effectiveness in creating high-performing and efficient models, advancing the development of more accessible AI technologies.
Quantifying Lexical Semantic Shift via Unbalanced Optimal Transport
Dec 17, 2024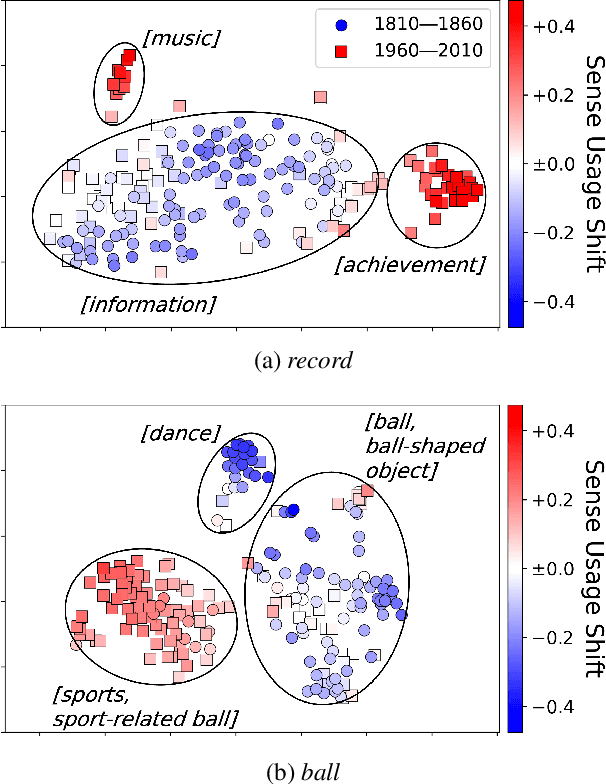



Lexical semantic change detection aims to identify shifts in word meanings over time. While existing methods using embeddings from a diachronic corpus pair estimate the degree of change for target words, they offer limited insight into changes at the level of individual usage instances. To address this, we apply Unbalanced Optimal Transport (UOT) to sets of contextualized word embeddings, capturing semantic change through the excess and deficit in the alignment between usage instances. In particular, we propose Sense Usage Shift (SUS), a measure that quantifies changes in the usage frequency of a word sense at each usage instance. By leveraging SUS, we demonstrate that several challenges in semantic change detection can be addressed in a unified manner, including quantifying instance-level semantic change and word-level tasks such as measuring the magnitude of semantic change and the broadening or narrowing of meaning.
Zipfian Whitening
Nov 01, 2024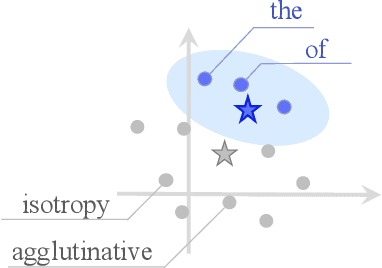

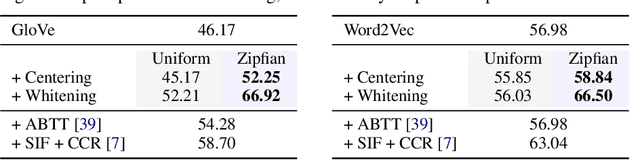
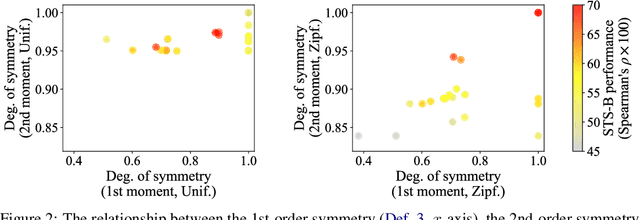
The word embedding space in neural models is skewed, and correcting this can improve task performance. We point out that most approaches for modeling, correcting, and measuring the symmetry of an embedding space implicitly assume that the word frequencies are uniform; in reality, word frequencies follow a highly non-uniform distribution, known as Zipf's law. Surprisingly, simply performing PCA whitening weighted by the empirical word frequency that follows Zipf's law significantly improves task performance, surpassing established baselines. From a theoretical perspective, both our approach and existing methods can be clearly categorized: word representations are distributed according to an exponential family with either uniform or Zipfian base measures. By adopting the latter approach, we can naturally emphasize informative low-frequency words in terms of their vector norm, which becomes evident from the information-geometric perspective, and in terms of the loss functions for imbalanced classification. Additionally, our theory corroborates that popular natural language processing methods, such as skip-gram negative sampling, WhiteningBERT, and headless language models, work well just because their word embeddings encode the empirical word frequency into the underlying probabilistic model.
Contrastive Learning-based Sentence Encoders Implicitly Weight Informative Words
Oct 24, 2023The performance of sentence encoders can be significantly improved through the simple practice of fine-tuning using contrastive loss. A natural question arises: what characteristics do models acquire during contrastive learning? This paper theoretically and experimentally shows that contrastive-based sentence encoders implicitly weight words based on information-theoretic quantities; that is, more informative words receive greater weight, while others receive less. The theory states that, in the lower bound of the optimal value of the contrastive learning objective, the norm of word embedding reflects the information gain associated with the distribution of surrounding words. We also conduct comprehensive experiments using various models, multiple datasets, two methods to measure the implicit weighting of models (Integrated Gradients and SHAP), and two information-theoretic quantities (information gain and self-information). The results provide empirical evidence that contrastive fine-tuning emphasizes informative words.
Unbalanced Optimal Transport for Unbalanced Word Alignment
Jun 07, 2023Monolingual word alignment is crucial to model semantic interactions between sentences. In particular, null alignment, a phenomenon in which words have no corresponding counterparts, is pervasive and critical in handling semantically divergent sentences. Identification of null alignment is useful on its own to reason about the semantic similarity of sentences by indicating there exists information inequality. To achieve unbalanced word alignment that values both alignment and null alignment, this study shows that the family of optimal transport (OT), i.e., balanced, partial, and unbalanced OT, are natural and powerful approaches even without tailor-made techniques. Our extensive experiments covering unsupervised and supervised settings indicate that our generic OT-based alignment methods are competitive against the state-of-the-arts specially designed for word alignment, remarkably on challenging datasets with high null alignment frequencies.
Transformer Language Models Handle Word Frequency in Prediction Head
May 29, 2023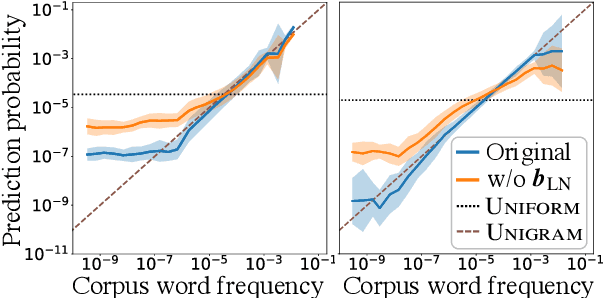
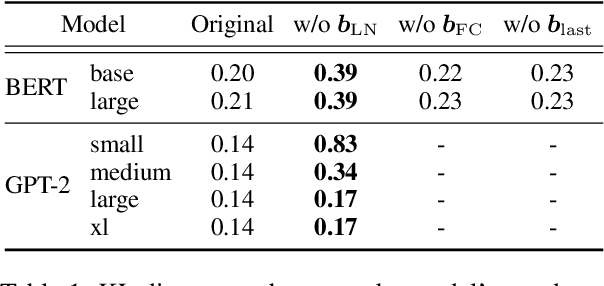
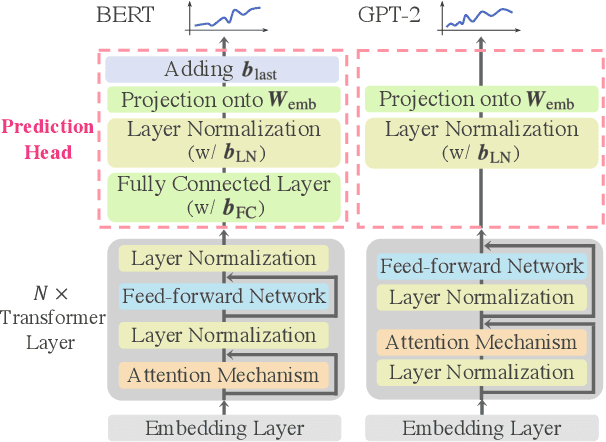
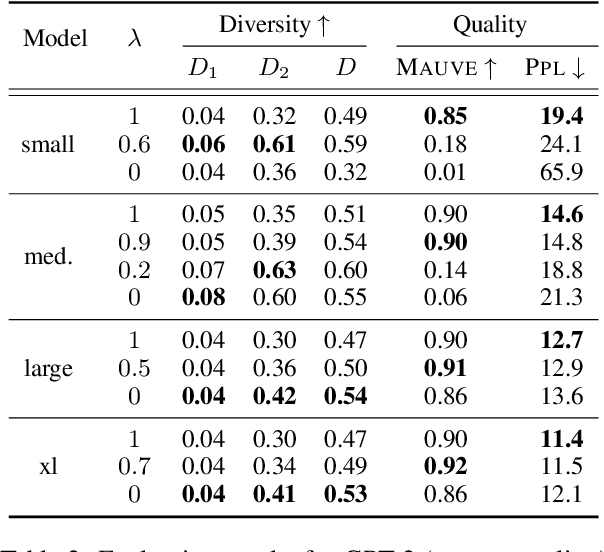
Prediction head is a crucial component of Transformer language models. Despite its direct impact on prediction, this component has often been overlooked in analyzing Transformers. In this study, we investigate the inner workings of the prediction head, specifically focusing on bias parameters. Our experiments with BERT and GPT-2 models reveal that the biases in their word prediction heads play a significant role in the models' ability to reflect word frequency in a corpus, aligning with the logit adjustment method commonly used in long-tailed learning. We also quantify the effect of controlling the biases in practical auto-regressive text generation scenarios; under a particular setting, more diverse text can be generated without compromising text quality.
Feed-Forward Blocks Control Contextualization in Masked Language Models
Feb 01, 2023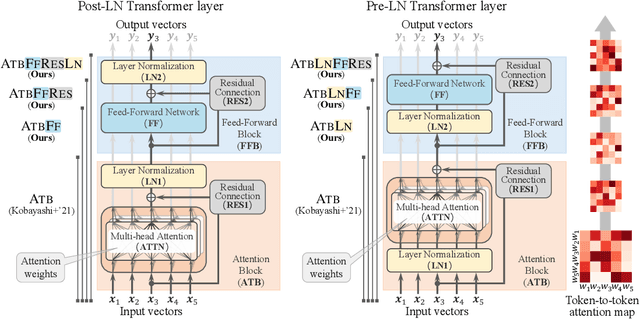
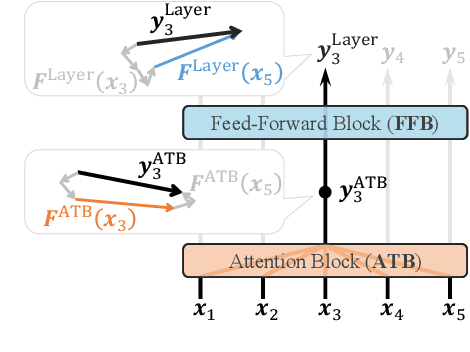

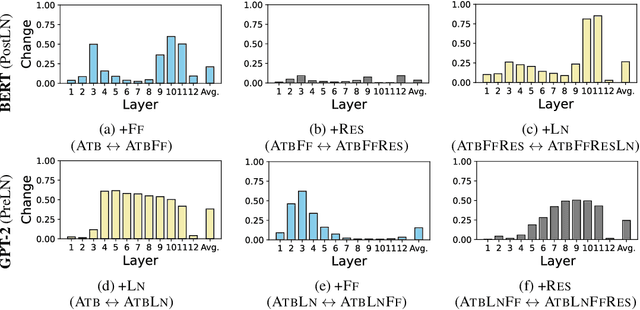
Understanding the inner workings of neural network models is a crucial step for rationalizing their output and refining their architecture. Transformer-based models are the core of recent natural language processing and have been analyzed typically with attention patterns as their epoch-making feature is contextualizing surrounding input words via attention mechanisms. In this study, we analyze their inner contextualization by considering all the components, including the feed-forward block (i.e., a feed-forward layer and its surrounding residual and normalization layers) as well as the attention. Our experiments with masked language models show that each of the previously overlooked components did modify the degree of the contextualization in case of processing special word-word pairs (e.g., consisting of named entities). Furthermore, we find that some components cancel each other's effects. Our results could update the typical view about each component's roles (e.g., attention performs contextualization, and the other components serve different roles) in the Transformer layer.
Norm of word embedding encodes information gain
Dec 19, 2022Distributed representations of words encode lexical semantic information, but how is that information encoded in word embeddings? Focusing on the skip-gram with negative-sampling method, we show theoretically and experimentally that the squared norm of word embedding encodes the information gain defined by the Kullback-Leibler divergence of the co-occurrence distribution of a word to the unigram distribution of the corpus. Furthermore, through experiments on tasks of keyword extraction, hypernym prediction, and part-of-speech discrimination, we confirmed that the KL divergence and the squared norm of embedding work as a measure of the informativeness of a word provided that the bias caused by word frequency is adequately corrected.