 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZipfian Whitening
Nov 01, 2024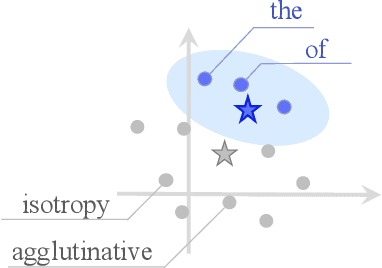

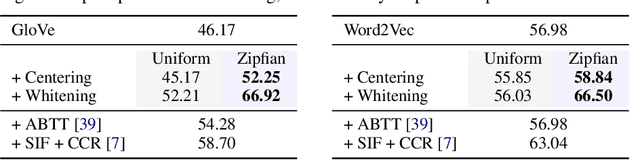
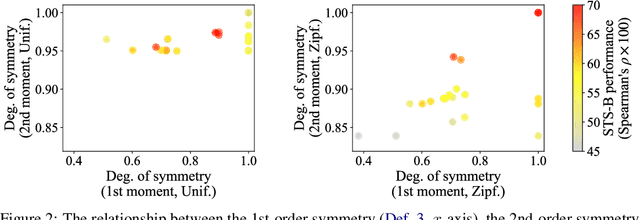
The word embedding space in neural models is skewed, and correcting this can improve task performance. We point out that most approaches for modeling, correcting, and measuring the symmetry of an embedding space implicitly assume that the word frequencies are uniform; in reality, word frequencies follow a highly non-uniform distribution, known as Zipf's law. Surprisingly, simply performing PCA whitening weighted by the empirical word frequency that follows Zipf's law significantly improves task performance, surpassing established baselines. From a theoretical perspective, both our approach and existing methods can be clearly categorized: word representations are distributed according to an exponential family with either uniform or Zipfian base measures. By adopting the latter approach, we can naturally emphasize informative low-frequency words in terms of their vector norm, which becomes evident from the information-geometric perspective, and in terms of the loss functions for imbalanced classification. Additionally, our theory corroborates that popular natural language processing methods, such as skip-gram negative sampling, WhiteningBERT, and headless language models, work well just because their word embeddings encode the empirical word frequency into the underlying probabilistic model.
Contrastive Learning-based Sentence Encoders Implicitly Weight Informative Words
Oct 24, 2023The performance of sentence encoders can be significantly improved through the simple practice of fine-tuning using contrastive loss. A natural question arises: what characteristics do models acquire during contrastive learning? This paper theoretically and experimentally shows that contrastive-based sentence encoders implicitly weight words based on information-theoretic quantities; that is, more informative words receive greater weight, while others receive less. The theory states that, in the lower bound of the optimal value of the contrastive learning objective, the norm of word embedding reflects the information gain associated with the distribution of surrounding words. We also conduct comprehensive experiments using various models, multiple datasets, two methods to measure the implicit weighting of models (Integrated Gradients and SHAP), and two information-theoretic quantities (information gain and self-information). The results provide empirical evidence that contrastive fine-tuning emphasizes informative words.