 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLaMo 2 Technical Report
Sep 05, 2025In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
Can Input Attributions Interpret the Inductive Reasoning Process Elicited in In-Context Learning?
Dec 20, 2024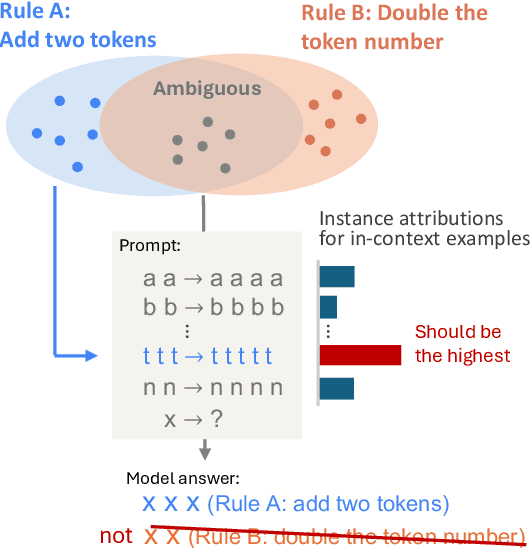
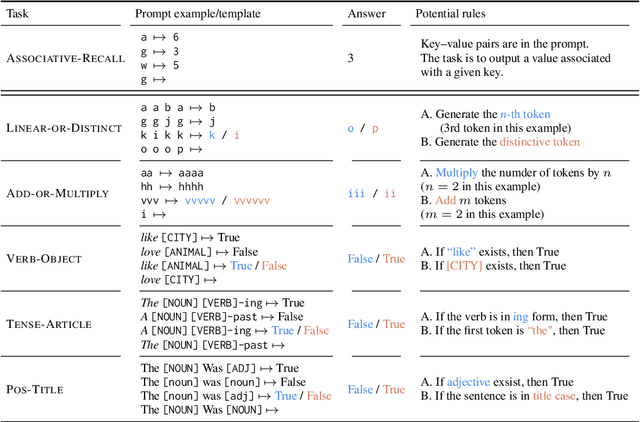
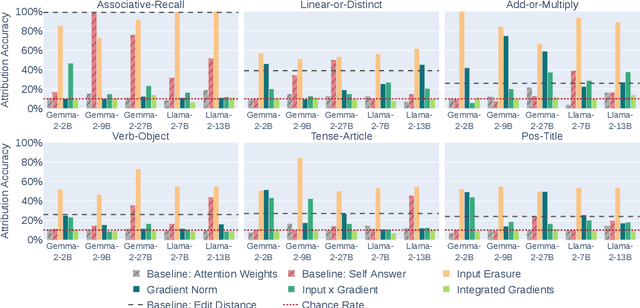
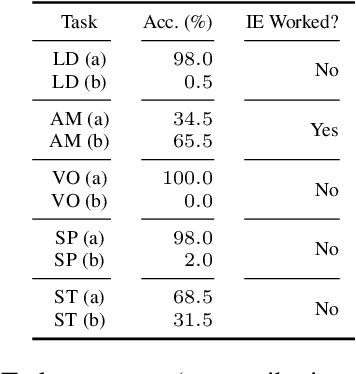
Elucidating the rationale behind neural models' outputs has been challenging in the machine learning field, which is indeed applicable in this age of large language models (LLMs) and in-context learning (ICL). When it comes to estimating input attributions (IA), ICL poses a new issue of interpreting which example in the prompt, consisting of a set of examples, contributed to identifying the task/rule to be solved. To this end, in this paper, we introduce synthetic diagnostic tasks inspired by the poverty of the stimulus design in inductive reasoning; here, most in-context examples are ambiguous w.r.t. their underlying rule, and one critical example disambiguates the task demonstrated. The question is whether conventional IA methods can identify such an example in interpreting the inductive reasoning process in ICL. Our experiments provide several practical findings; for example, a certain simple IA method works the best, and the larger the model, the generally harder it is to interpret the ICL with gradient-based IA methods.
Contrastive Learning-based Sentence Encoders Implicitly Weight Informative Words
Oct 24, 2023The performance of sentence encoders can be significantly improved through the simple practice of fine-tuning using contrastive loss. A natural question arises: what characteristics do models acquire during contrastive learning? This paper theoretically and experimentally shows that contrastive-based sentence encoders implicitly weight words based on information-theoretic quantities; that is, more informative words receive greater weight, while others receive less. The theory states that, in the lower bound of the optimal value of the contrastive learning objective, the norm of word embedding reflects the information gain associated with the distribution of surrounding words. We also conduct comprehensive experiments using various models, multiple datasets, two methods to measure the implicit weighting of models (Integrated Gradients and SHAP), and two information-theoretic quantities (information gain and self-information). The results provide empirical evidence that contrastive fine-tuning emphasizes informative words.
Assessing Step-by-Step Reasoning against Lexical Negation: A Case Study on Syllogism
Oct 23, 2023



Large language models (LLMs) take advantage of step-by-step reasoning instructions, e.g., chain-of-thought (CoT) prompting. Building on this, their ability to perform CoT-style reasoning robustly is of interest from a probing perspective. In this study, we inspect the step-by-step reasoning ability of LLMs with a focus on negation, which is a core linguistic phenomenon that is difficult to process. In particular, we introduce several controlled settings (e.g., reasoning in case of fictional entities) to evaluate the logical reasoning abilities of the models. We observed that dozens of modern LLMs were not robust against lexical negation (e.g., plausible ->implausible) when performing CoT-style reasoning, and the results highlight unique limitations in each LLM family.
Transformer Language Models Handle Word Frequency in Prediction Head
May 29, 2023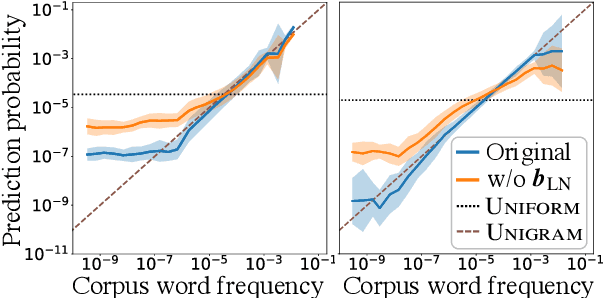
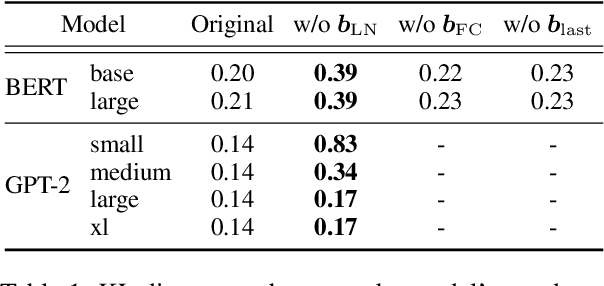
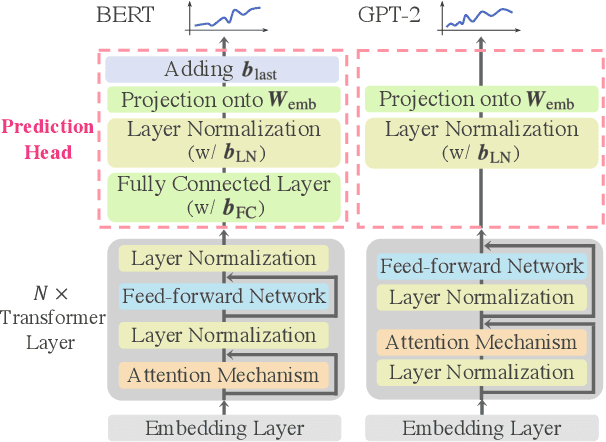
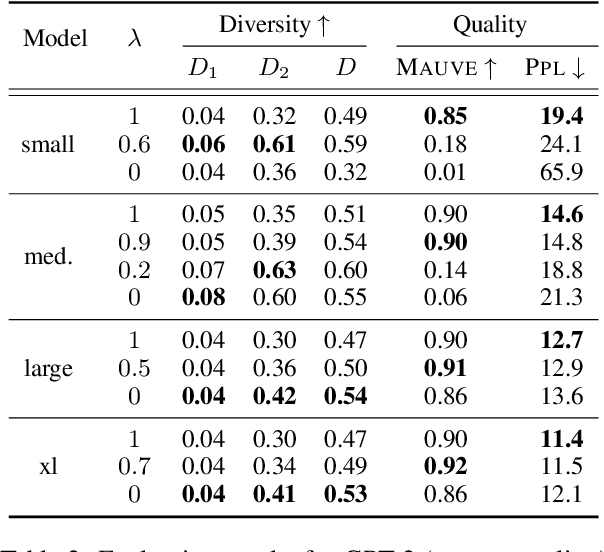
Prediction head is a crucial component of Transformer language models. Despite its direct impact on prediction, this component has often been overlooked in analyzing Transformers. In this study, we investigate the inner workings of the prediction head, specifically focusing on bias parameters. Our experiments with BERT and GPT-2 models reveal that the biases in their word prediction heads play a significant role in the models' ability to reflect word frequency in a corpus, aligning with the logit adjustment method commonly used in long-tailed learning. We also quantify the effect of controlling the biases in practical auto-regressive text generation scenarios; under a particular setting, more diverse text can be generated without compromising text quality.
Feed-Forward Blocks Control Contextualization in Masked Language Models
Feb 01, 2023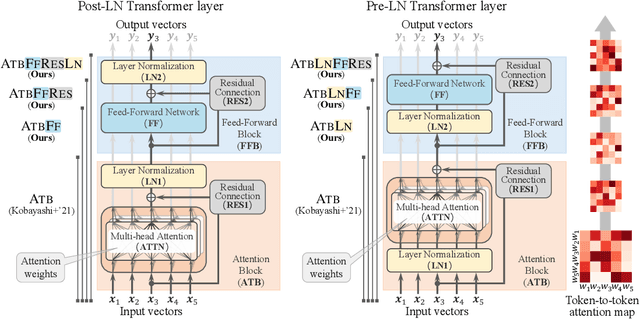
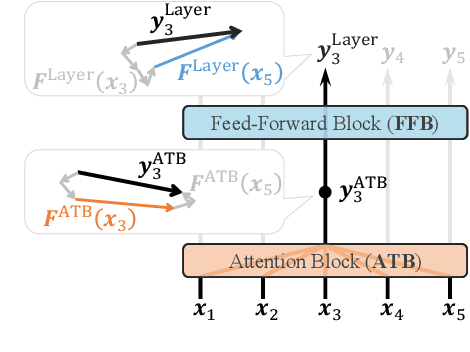

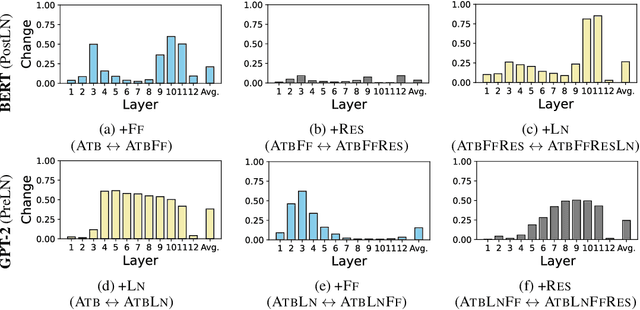
Understanding the inner workings of neural network models is a crucial step for rationalizing their output and refining their architecture. Transformer-based models are the core of recent natural language processing and have been analyzed typically with attention patterns as their epoch-making feature is contextualizing surrounding input words via attention mechanisms. In this study, we analyze their inner contextualization by considering all the components, including the feed-forward block (i.e., a feed-forward layer and its surrounding residual and normalization layers) as well as the attention. Our experiments with masked language models show that each of the previously overlooked components did modify the degree of the contextualization in case of processing special word-word pairs (e.g., consisting of named entities). Furthermore, we find that some components cancel each other's effects. Our results could update the typical view about each component's roles (e.g., attention performs contextualization, and the other components serve different roles) in the Transformer layer.
Incorporating Residual and Normalization Layers into Analysis of Masked Language Models
Sep 15, 2021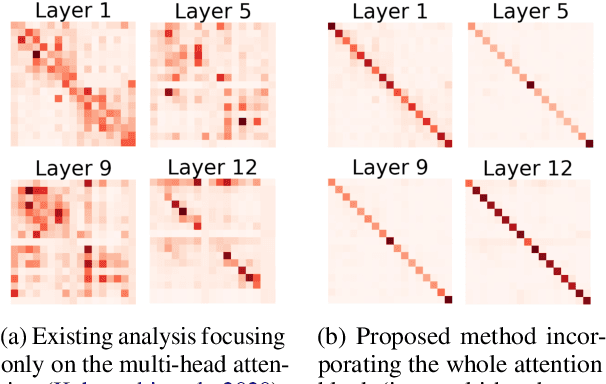
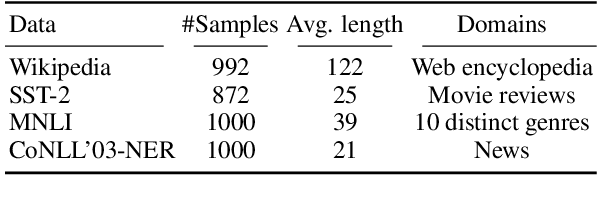
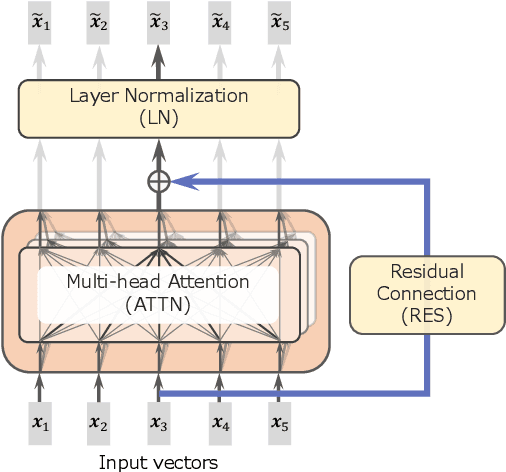
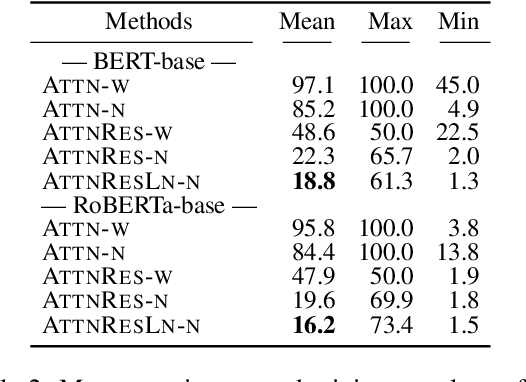
Transformer architecture has become ubiquitous in the natural language processing field. To interpret the Transformer-based models, their attention patterns have been extensively analyzed. However, the Transformer architecture is not only composed of the multi-head attention; other components can also contribute to Transformers' progressive performance. In this study, we extended the scope of the analysis of Transformers from solely the attention patterns to the whole attention block, i.e., multi-head attention, residual connection, and layer normalization. Our analysis of Transformer-based masked language models shows that the token-to-token interaction performed via attention has less impact on the intermediate representations than previously assumed. These results provide new intuitive explanations of existing reports; for example, discarding the learned attention patterns tends not to adversely affect the performance. The codes of our experiments are publicly available.
Attention Module is Not Only a Weight: Analyzing Transformers with Vector Norms
Apr 21, 2020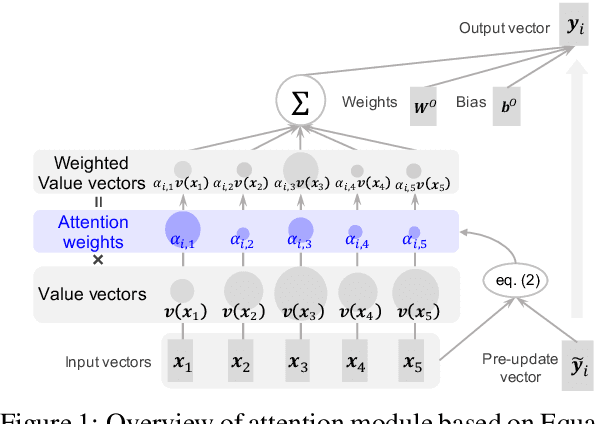

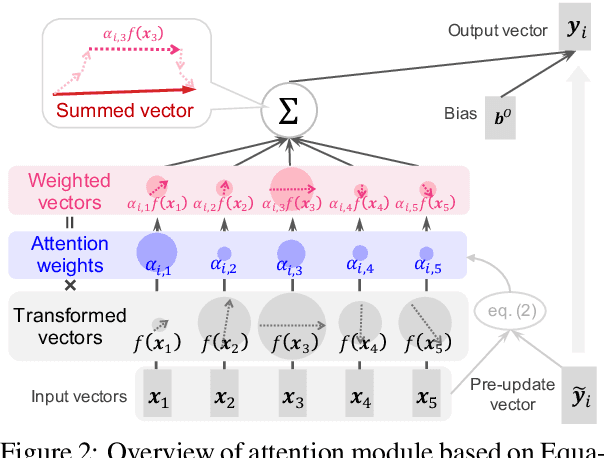
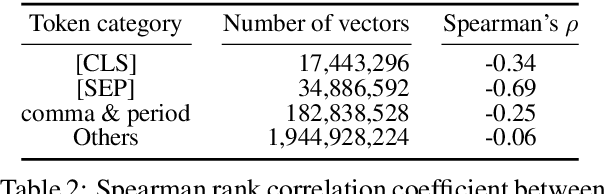
Because attention modules are core components of Transformer-based models that have recently achieved considerable success in natural language processing, the community has a great deal of interest in why attention modules are successful and what kind of linguistic information they capture. In particular, previous studies have mainly analyzed attention weights to see how much information the attention modules gather from each input to produce an output. In this study, we point out that attention weights alone are only one of the two factors determining the output of self-attention modules, and we propose to incorporate the other factor as well, namely, the transformed input vectors into the analysis. That is, we measure the norm of the weighted vectors as the contribution of each input to an output. Our analysis of self-attention modules in BERT and the Transformer-based neural machine translation system shows that the attention modules behave very intuitively, contrary to previous findings. That is, our analysis reveals that (1) BERT's attention modules do not pay so much attention to special tokens, and (2) Transformer's attention modules capture word alignment quite well.