 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Module is Not Only a Weight: Analyzing Transformers with Vector Norms
Paper and Code
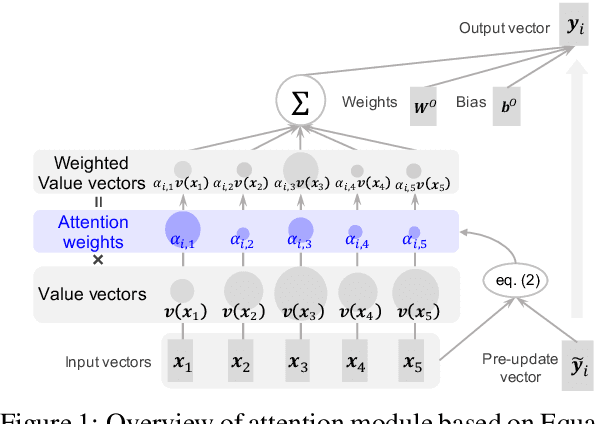

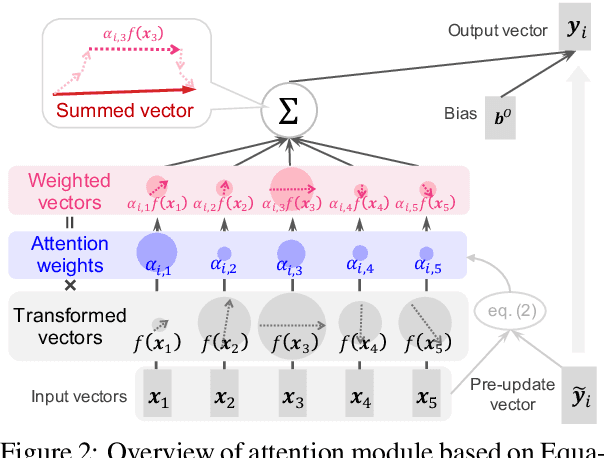
Because attention modules are core components of Transformer-based models that have recently achieved considerable success in natural language processing, the community has a great deal of interest in why attention modules are successful and what kind of linguistic information they capture. In particular, previous studies have mainly analyzed attention weights to see how much information the attention modules gather from each input to produce an output. In this study, we point out that attention weights alone are only one of the two factors determining the output of self-attention modules, and we propose to incorporate the other factor as well, namely, the transformed input vectors into the analysis. That is, we measure the norm of the weighted vectors as the contribution of each input to an output. Our analysis of self-attention modules in BERT and the Transformer-based neural machine translation system shows that the attention modules behave very intuitively, contrary to previous findings. That is, our analysis reveals that (1) BERT's attention modules do not pay so much attention to special tokens, and (2) Transformer's attention modules capture word alignment quite well.