 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Alignment Between Language Model Layers and Human Sentence Processing
Apr 20, 2026A recent study (Kuribayashi et al., 2025) has shown that human sentence processing behavior, typically measured on syntactically unchallenging constructions, can be effectively modeled using surprisal from early layers of large language models (LLMs). This raises the question of whether such advantages of internal layers extend to more syntactically challenging constructions, where surprisal has been reported to underestimate human cognitive effort. In this paper, we begin by exploring internal layers that better estimate human cognitive effort observed in syntactic ambiguity processing in English. Our experiments show that, in contrast to naturalistic reading, later layers better estimate such a cognitive effort, but still underestimate the human data. This dual alignment sheds light on different modes of sentence processing in humans and LMs: naturalistic reading employs a somewhat weak prediction akin to earlier layers of LMs, while syntactically challenging processing requires more fully-contextualized representations, better modeled by later layers of LMs. Motivated by these findings, we also explore several probability-update measures using shallow and deep layers of LMs, showing a complementary advantage to single-layer's surprisal in reading time modeling.
An Existence Proof for Neural Language Models That Can Explain Garden-Path Effects via Surprisal
Apr 20, 2026Surprisal theory hypothesizes that the difficulty of human sentence processing increases linearly with surprisal, the negative log-probability of a word given its context. Computational psycholinguistics has tested this hypothesis using language models (LMs) as proxies for human prediction. While surprisal derived from recent neural LMs generally captures human processing difficulty on naturalistic corpora that predominantly consist of simple sentences, it severely underestimates processing difficulty on sentences that require syntactic disambiguation (garden-path effects). This leads to the claim that the processing difficulty of such sentences cannot be reduced to surprisal, although it remains possible that neural LMs simply differ from humans in next-word prediction. In this paper, we investigate whether it is truly impossible to construct a neural LM that can explain garden-path effects via surprisal. Specifically, instead of evaluating off-the-shelf neural LMs, we fine-tune these LMs on garden-path sentences so as to better align surprisal-based reading-time estimates with actual human reading times. Our results show that fine-tuned LMs do not overfit and successfully capture human reading slowdowns on held-out garden-path items; they even improve predictive power for human reading times on naturalistic corpora and preserve their general LM capabilities. These results provide an existence proof for a neural LM that can explain both garden-path effects and naturalistic reading times via surprisal, but also raise a theoretical question: what kind of evidence can truly falsify surprisal theory?
Transformer Key-Value Memories Are Nearly as Interpretable as Sparse Autoencoders
Oct 25, 2025



Recent interpretability work on large language models (LLMs) has been increasingly dominated by a feature-discovery approach with the help of proxy modules. Then, the quality of features learned by, e.g., sparse auto-encoders (SAEs), is evaluated. This paradigm naturally raises a critical question: do such learned features have better properties than those already represented within the original model parameters, and unfortunately, only a few studies have made such comparisons systematically so far. In this work, we revisit the interpretability of feature vectors stored in feed-forward (FF) layers, given the perspective of FF as key-value memories, with modern interpretability benchmarks. Our extensive evaluation revealed that SAE and FFs exhibits a similar range of interpretability, although SAEs displayed an observable but minimal improvement in some aspects. Furthermore, in certain aspects, surprisingly, even vanilla FFs yielded better interpretability than the SAEs, and features discovered in SAEs and FFs diverged. These bring questions about the advantage of SAEs from both perspectives of feature quality and faithfulness, compared to directly interpreting FF feature vectors, and FF key-value parameters serve as a strong baseline in modern interpretability research.
Which Word Orders Facilitate Length Generalization in LMs? An Investigation with GCG-Based Artificial Languages
Oct 14, 2025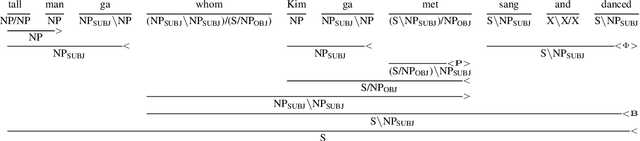


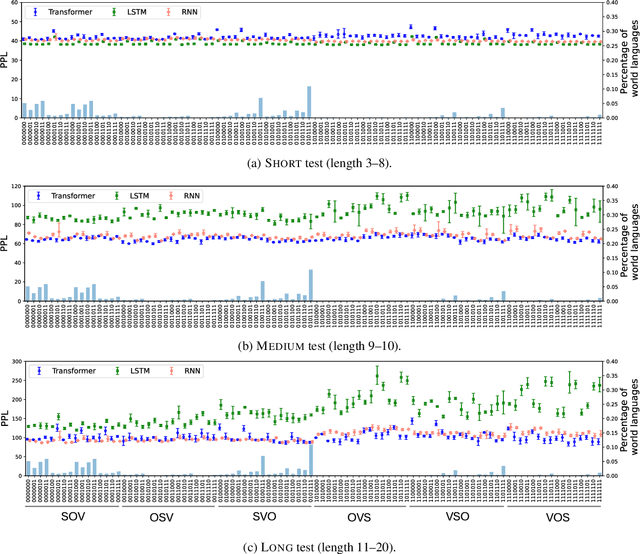
Whether language models (LMs) have inductive biases that favor typologically frequent grammatical properties over rare, implausible ones has been investigated, typically using artificial languages (ALs) (White and Cotterell, 2021; Kuribayashi et al., 2024). In this paper, we extend these works from two perspectives. First, we extend their context-free AL formalization by adopting Generalized Categorial Grammar (GCG) (Wood, 2014), which allows ALs to cover attested but previously overlooked constructions, such as unbounded dependency and mildly context-sensitive structures. Second, our evaluation focuses more on the generalization ability of LMs to process unseen longer test sentences. Thus, our ALs better capture features of natural languages and our experimental paradigm leads to clearer conclusions -- typologically plausible word orders tend to be easier for LMs to productively generalize.
Syntactic Learnability of Echo State Neural Language Models at Scale
Mar 03, 2025What is a neural model with minimum architectural complexity that exhibits reasonable language learning capability? To explore such a simple but sufficient neural language model, we revisit a basic reservoir computing (RC) model, Echo State Network (ESN), a restricted class of simple Recurrent Neural Networks. Our experiments showed that ESN with a large hidden state is comparable or superior to Transformer in grammaticality judgment tasks when trained with about 100M words, suggesting that architectures as complex as that of Transformer may not always be necessary for syntactic learning.
Can LLMs Simulate L2-English Dialogue? An Information-Theoretic Analysis of L1-Dependent Biases
Feb 20, 2025This study evaluates Large Language Models' (LLMs) ability to simulate non-native-like English use observed in human second language (L2) learners interfered with by their native first language (L1). In dialogue-based interviews, we prompt LLMs to mimic L2 English learners with specific L1s (e.g., Japanese, Thai, Urdu) across seven languages, comparing their outputs to real L2 learner data. Our analysis examines L1-driven linguistic biases, such as reference word usage and avoidance behaviors, using information-theoretic and distributional density measures. Results show that modern LLMs (e.g., Qwen2.5, LLAMA3.3, DeepseekV3, GPT-4o) replicate L1-dependent patterns observed in human L2 data, with distinct influences from various languages (e.g., Japanese, Korean, and Mandarin significantly affect tense agreement, and Urdu influences noun-verb collocations). Our results reveal the potential of LLMs for L2 dialogue generation and evaluation for future educational applications.
On Representational Dissociation of Language and Arithmetic in Large Language Models
Feb 17, 2025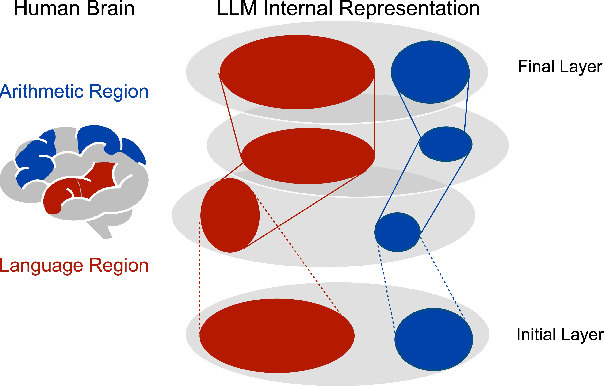
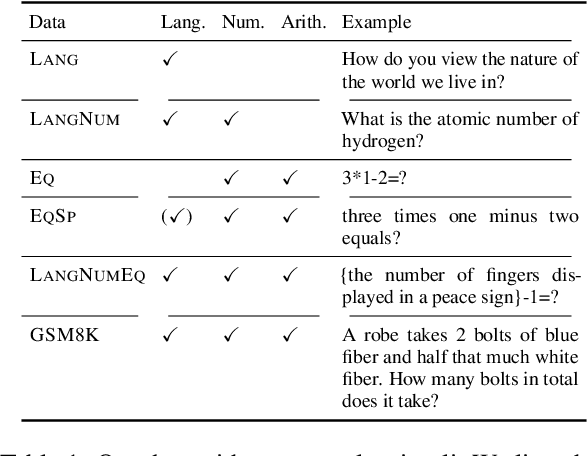
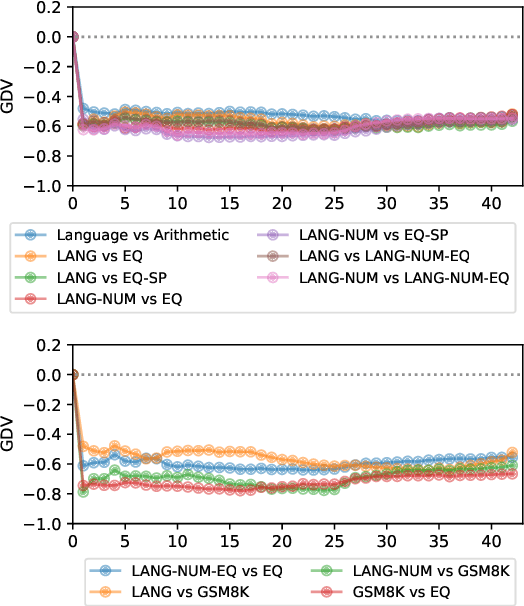

The association between language and (non-linguistic) thinking ability in humans has long been debated, and recently, neuroscientific evidence of brain activity patterns has been considered. Such a scientific context naturally raises an interdisciplinary question -- what about such a language-thought dissociation in large language models (LLMs)? In this paper, as an initial foray, we explore this question by focusing on simple arithmetic skills (e.g., $1+2=$ ?) as a thinking ability and analyzing the geometry of their encoding in LLMs' representation space. Our experiments with linear classifiers and cluster separability tests demonstrate that simple arithmetic equations and general language input are encoded in completely separated regions in LLMs' internal representation space across all the layers, which is also supported with more controlled stimuli (e.g., spelled-out equations). These tentatively suggest that arithmetic reasoning is mapped into a distinct region from general language input, which is in line with the neuroscientific observations of human brain activations, while we also point out their somewhat cognitively implausible geometric properties.
Can Language Models Learn Typologically Implausible Languages?
Feb 17, 2025Grammatical features across human languages show intriguing correlations often attributed to learning biases in humans. However, empirical evidence has been limited to experiments with highly simplified artificial languages, and whether these correlations arise from domain-general or language-specific biases remains a matter of debate. Language models (LMs) provide an opportunity to study artificial language learning at a large scale and with a high degree of naturalism. In this paper, we begin with an in-depth discussion of how LMs allow us to better determine the role of domain-general learning biases in language universals. We then assess learnability differences for LMs resulting from typologically plausible and implausible languages closely following the word-order universals identified by linguistic typologists. We conduct a symmetrical cross-lingual study training and testing LMs on an array of highly naturalistic but counterfactual versions of the English (head-initial) and Japanese (head-final) languages. Compared to similar work, our datasets are more naturalistic and fall closer to the boundary of plausibility. Our experiments show that these LMs are often slower to learn these subtly implausible languages, while ultimately achieving similar performance on some metrics regardless of typological plausibility. These findings lend credence to the conclusion that LMs do show some typologically-aligned learning preferences, and that the typological patterns may result from, at least to some degree, domain-general learning biases.
Large Language Models Are Human-Like Internally
Feb 03, 2025



Recent cognitive modeling studies have reported that larger language models (LMs) exhibit a poorer fit to human reading behavior, leading to claims of their cognitive implausibility. In this paper, we revisit this argument through the lens of mechanistic interpretability and argue that prior conclusions were skewed by an exclusive focus on the final layers of LMs. Our analysis reveals that next-word probabilities derived from internal layers of larger LMs align with human sentence processing data as well as, or better than, those from smaller LMs. This alignment holds consistently across behavioral (self-paced reading times, gaze durations, MAZE task processing times) and neurophysiological (N400 brain potentials) measures, challenging earlier mixed results and suggesting that the cognitive plausibility of larger LMs has been underestimated. Furthermore, we first identify an intriguing relationship between LM layers and human measures: earlier layers correspond more closely with fast gaze durations, while later layers better align with relatively slower signals such as N400 potentials and MAZE processing times. Our work opens new avenues for interdisciplinary research at the intersection of mechanistic interpretability and cognitive modeling.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.