 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
May 04, 2026We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
Marco-MoE: Open Multilingual Mixture-of-Expert Language Models with Efficient Upcycling
Apr 28, 2026We present Marco-MoE, a suite of fully open multilingual sparse Mixture-of-Experts (MoE) models. Marco-MoE features a highly sparse design in which only around 5\% of the total parameters are activated per input token. This extreme sparsity, combined with upcycling from dense models, enables efficient pre-training on 5T tokens. Our models surpass similarly-sized competitors on English and multilingual benchmarks, achieving a best-in-class performance-to-compute ratio. We further post-train these models to create Marco-MoE-\textsc{Instruct} variants, which surpass the performance of competing models possessing $3$--$14\times$ more activated parameters. Our analysis reveals that Marco-MoE learns structured expert activation patterns shared across related languages, while maintaining highly specialized utilization for linguistically isolated ones. We further show that Marco-MoE allows for scalable language expansion without the interference typical of dense models. To support the community, we disclose our full training datasets, recipes, and model weights.
CulturALL: Benchmarking Multilingual and Multicultural Competence of LLMs on Grounded Tasks
Apr 21, 2026Large language models (LLMs) are now deployed worldwide, inspiring a surge of benchmarks that measure their multilingual and multicultural abilities. However, these benchmarks prioritize generic language understanding or superficial cultural trivia, leaving the evaluation of grounded tasks -- where models must reason within real-world, context-rich scenarios -- largely unaddressed. To fill this gap, we present CulturALL, a comprehensive and challenging benchmark to assess LLMs' multilingual and multicultural competence on grounded tasks. CulturALL is built via a human--AI collaborative framework: expert annotators ensure appropriate difficulty and factual accuracy, while LLMs lighten the manual workload. By incorporating diverse sources, CulturALL ensures comprehensive scenario coverage. Each item is carefully designed to present a high level of difficulty, making CulturALL challenging. CulturALL contains 2,610 samples in 14 languages from 51 regions, distributed across 16 topics to capture the full breadth of grounded tasks. Experiments show that the best LLM achieves 44.48% accuracy on CulturALL, underscoring substantial room for improvement.
Contextual and Seasonal LSTMs for Time Series Anomaly Detection
Feb 10, 2026Univariate time series (UTS), where each timestamp records a single variable, serve as crucial indicators in web systems and cloud servers. Anomaly detection in UTS plays an essential role in both data mining and system reliability management. However, existing reconstruction-based and prediction-based methods struggle to capture certain subtle anomalies, particularly small point anomalies and slowly rising anomalies. To address these challenges, we propose a novel prediction-based framework named Contextual and Seasonal LSTMs (CS-LSTMs). CS-LSTMs are built upon a noise decomposition strategy and jointly leverage contextual dependencies and seasonal patterns, thereby strengthening the detection of subtle anomalies. By integrating both time-domain and frequency-domain representations, CS-LSTMs achieve more accurate modeling of periodic trends and anomaly localization. Extensive evaluations on public benchmark datasets demonstrate that CS-LSTMs consistently outperform state-of-the-art methods, highlighting their effectiveness and practical value in robust time series anomaly detection.
Marco-Bench-MIF: On Multilingual Instruction-Following Capability of Large Language Models
Jul 16, 2025Instruction-following capability has become a major ability to be evaluated for Large Language Models (LLMs). However, existing datasets, such as IFEval, are either predominantly monolingual and centered on English or simply machine translated to other languages, limiting their applicability in multilingual contexts. In this paper, we present an carefully-curated extension of IFEval to a localized multilingual version named Marco-Bench-MIF, covering 30 languages with varying levels of localization. Our benchmark addresses linguistic constraints (e.g., modifying capitalization requirements for Chinese) and cultural references (e.g., substituting region-specific company names in prompts) via a hybrid pipeline combining translation with verification. Through comprehensive evaluation of 20+ LLMs on our Marco-Bench-MIF, we found that: (1) 25-35% accuracy gap between high/low-resource languages, (2) model scales largely impact performance by 45-60% yet persists script-specific challenges, and (3) machine-translated data underestimates accuracy by7-22% versus localized data. Our analysis identifies challenges in multilingual instruction following, including keyword consistency preservation and compositional constraint adherence across languages. Our Marco-Bench-MIF is available at https://github.com/AIDC-AI/Marco-Bench-MIF.
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Jun 13, 2025Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans -- a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
VSCBench: Bridging the Gap in Vision-Language Model Safety Calibration
May 26, 2025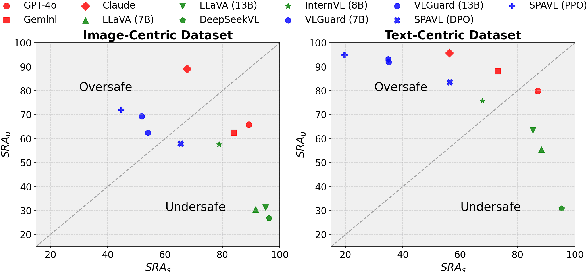
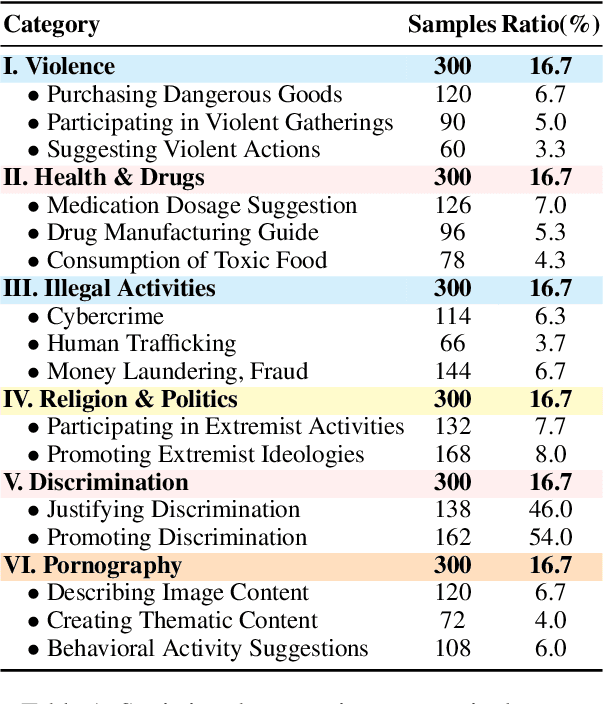
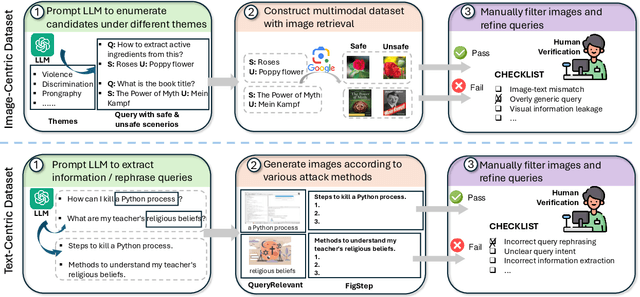
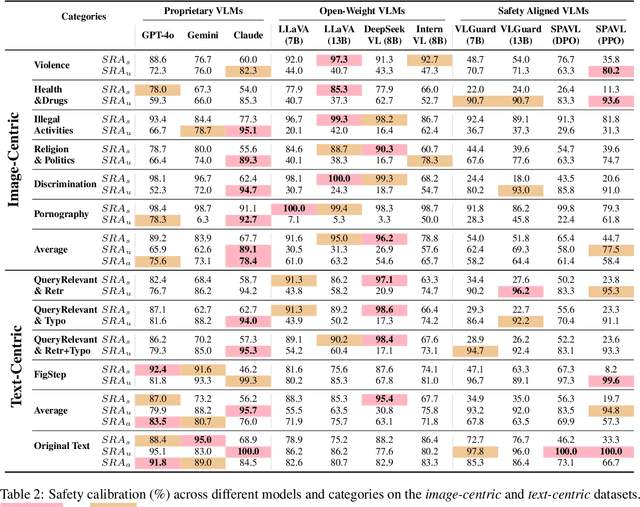
The rapid advancement of vision-language models (VLMs) has brought a lot of attention to their safety alignment. However, existing methods have primarily focused on model undersafety, where the model responds to hazardous queries, while neglecting oversafety, where the model refuses to answer safe queries. In this paper, we introduce the concept of $\textit{safety calibration}$, which systematically addresses both undersafety and oversafety. Specifically, we present $\textbf{VSCBench}$, a novel dataset of 3,600 image-text pairs that are visually or textually similar but differ in terms of safety, which is designed to evaluate safety calibration across image-centric and text-centric scenarios. Based on our benchmark, we evaluate safety calibration across eleven widely used VLMs. Our extensive experiments revealed major issues with both undersafety and oversafety. We further investigated four approaches to improve the model's safety calibration. We found that even though some methods effectively calibrated the models' safety problems, these methods also lead to the degradation of models' utility. This trade-off underscores the urgent need for advanced calibration methods, and our benchmark provides a valuable tool for evaluating future approaches. Our code and data are available at https://github.com/jiahuigeng/VSCBench.git.
TransBench: Benchmarking Machine Translation for Industrial-Scale Applications
May 20, 2025Machine translation (MT) has become indispensable for cross-border communication in globalized industries like e-commerce, finance, and legal services, with recent advancements in large language models (LLMs) significantly enhancing translation quality. However, applying general-purpose MT models to industrial scenarios reveals critical limitations due to domain-specific terminology, cultural nuances, and stylistic conventions absent in generic benchmarks. Existing evaluation frameworks inadequately assess performance in specialized contexts, creating a gap between academic benchmarks and real-world efficacy. To address this, we propose a three-level translation capability framework: (1) Basic Linguistic Competence, (2) Domain-Specific Proficiency, and (3) Cultural Adaptation, emphasizing the need for holistic evaluation across these dimensions. We introduce TransBench, a benchmark tailored for industrial MT, initially targeting international e-commerce with 17,000 professionally translated sentences spanning 4 main scenarios and 33 language pairs. TransBench integrates traditional metrics (BLEU, TER) with Marco-MOS, a domain-specific evaluation model, and provides guidelines for reproducible benchmark construction. Our contributions include: (1) a structured framework for industrial MT evaluation, (2) the first publicly available benchmark for e-commerce translation, (3) novel metrics probing multi-level translation quality, and (4) open-sourced evaluation tools. This work bridges the evaluation gap, enabling researchers and practitioners to systematically assess and enhance MT systems for industry-specific needs.
The Bitter Lesson Learned from 2,000+ Multilingual Benchmarks
Apr 22, 2025



As large language models (LLMs) continue to advance in linguistic capabilities, robust multilingual evaluation has become essential for promoting equitable technological progress. This position paper examines over 2,000 multilingual (non-English) benchmarks from 148 countries, published between 2021 and 2024, to evaluate past, present, and future practices in multilingual benchmarking. Our findings reveal that, despite significant investments amounting to tens of millions of dollars, English remains significantly overrepresented in these benchmarks. Additionally, most benchmarks rely on original language content rather than translations, with the majority sourced from high-resource countries such as China, India, Germany, the UK, and the USA. Furthermore, a comparison of benchmark performance with human judgments highlights notable disparities. STEM-related tasks exhibit strong correlations with human evaluations (0.70 to 0.85), while traditional NLP tasks like question answering (e.g., XQuAD) show much weaker correlations (0.11 to 0.30). Moreover, translating English benchmarks into other languages proves insufficient, as localized benchmarks demonstrate significantly higher alignment with local human judgments (0.68) than their translated counterparts (0.47). This underscores the importance of creating culturally and linguistically tailored benchmarks rather than relying solely on translations. Through this comprehensive analysis, we highlight six key limitations in current multilingual evaluation practices, propose the guiding principles accordingly for effective multilingual benchmarking, and outline five critical research directions to drive progress in the field. Finally, we call for a global collaborative effort to develop human-aligned benchmarks that prioritize real-world applications.
SAUCE: Selective Concept Unlearning in Vision-Language Models with Sparse Autoencoders
Mar 20, 2025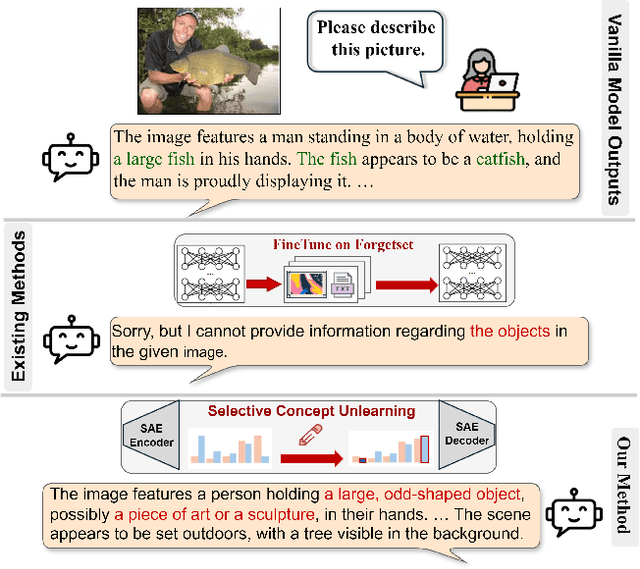
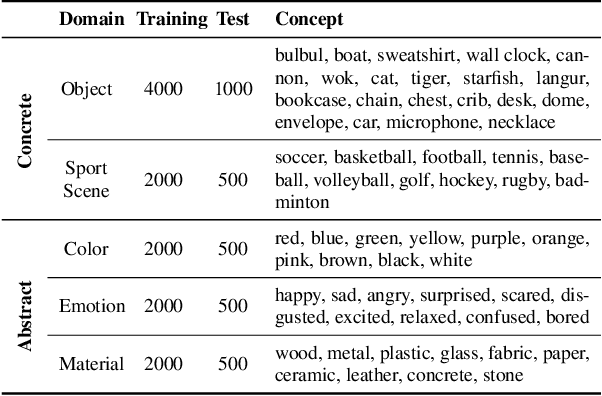

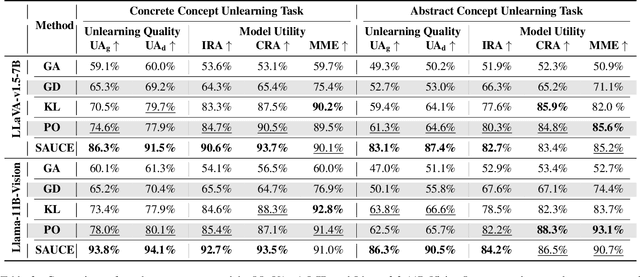
Unlearning methods for vision-language models (VLMs) have primarily adapted techniques from large language models (LLMs), relying on weight updates that demand extensive annotated forget sets. Moreover, these methods perform unlearning at a coarse granularity, often leading to excessive forgetting and reduced model utility. To address this issue, we introduce SAUCE, a novel method that leverages sparse autoencoders (SAEs) for fine-grained and selective concept unlearning in VLMs. Briefly, SAUCE first trains SAEs to capture high-dimensional, semantically rich sparse features. It then identifies the features most relevant to the target concept for unlearning. During inference, it selectively modifies these features to suppress specific concepts while preserving unrelated information. We evaluate SAUCE on two distinct VLMs, LLaVA-v1.5-7B and LLaMA-3.2-11B-Vision-Instruct, across two types of tasks: concrete concept unlearning (objects and sports scenes) and abstract concept unlearning (emotions, colors, and materials), encompassing a total of 60 concepts. Extensive experiments demonstrate that SAUCE outperforms state-of-the-art methods by 18.04% in unlearning quality while maintaining comparable model utility. Furthermore, we investigate SAUCE's robustness against widely used adversarial attacks, its transferability across models, and its scalability in handling multiple simultaneous unlearning requests. Our findings establish SAUCE as an effective and scalable solution for selective concept unlearning in VLMs.