 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Translation Switch: Discovering and Exploiting the Task-Initiation Features in LLMs
Jan 16, 2026Large Language Models (LLMs) frequently exhibit strong translation abilities, even without task-specific fine-tuning. However, the internal mechanisms governing this innate capability remain largely opaque. To demystify this process, we leverage Sparse Autoencoders (SAEs) and introduce a novel framework for identifying task-specific features. Our method first recalls features that are frequently co-activated on translation inputs and then filters them for functional coherence using a PCA-based consistency metric. This framework successfully isolates a small set of **translation initiation** features. Causal interventions demonstrate that amplifying these features steers the model towards correct translation, while ablating them induces hallucinations and off-task outputs, confirming they represent a core component of the model's innate translation competency. Moving from analysis to application, we leverage this mechanistic insight to propose a new data selection strategy for efficient fine-tuning. Specifically, we prioritize training on **mechanistically hard** samples-those that fail to naturally activate the translation initiation features. Experiments show this approach significantly improves data efficiency and suppresses hallucinations. Furthermore, we find these mechanisms are transferable to larger models of the same family. Our work not only decodes a core component of the translation mechanism in LLMs but also provides a blueprint for using internal model mechanism to create more robust and efficient models. The codes are available at https://github.com/flamewei123/AAAI26-translation-Initiation-Features.
Rethinking Multilingual Vision-Language Translation: Dataset, Evaluation, and Adaptation
Jun 13, 2025Vision-Language Translation (VLT) is a challenging task that requires accurately recognizing multilingual text embedded in images and translating it into the target language with the support of visual context. While recent Large Vision-Language Models (LVLMs) have demonstrated strong multilingual and visual understanding capabilities, there is a lack of systematic evaluation and understanding of their performance on VLT. In this work, we present a comprehensive study of VLT from three key perspectives: data quality, model architecture, and evaluation metrics. (1) We identify critical limitations in existing datasets, particularly in semantic and cultural fidelity, and introduce AibTrans -- a multilingual, parallel, human-verified dataset with OCR-corrected annotations. (2) We benchmark 11 commercial LVLMs/LLMs and 6 state-of-the-art open-source models across end-to-end and cascaded architectures, revealing their OCR dependency and contrasting generation versus reasoning behaviors. (3) We propose Density-Aware Evaluation to address metric reliability issues under varying contextual complexity, introducing the DA Score as a more robust measure of translation quality. Building upon these findings, we establish a new evaluation benchmark for VLT. Notably, we observe that fine-tuning LVLMs on high-resource language pairs degrades cross-lingual performance, and we propose a balanced multilingual fine-tuning strategy that effectively adapts LVLMs to VLT without sacrificing their generalization ability.
TransBench: Benchmarking Machine Translation for Industrial-Scale Applications
May 20, 2025Machine translation (MT) has become indispensable for cross-border communication in globalized industries like e-commerce, finance, and legal services, with recent advancements in large language models (LLMs) significantly enhancing translation quality. However, applying general-purpose MT models to industrial scenarios reveals critical limitations due to domain-specific terminology, cultural nuances, and stylistic conventions absent in generic benchmarks. Existing evaluation frameworks inadequately assess performance in specialized contexts, creating a gap between academic benchmarks and real-world efficacy. To address this, we propose a three-level translation capability framework: (1) Basic Linguistic Competence, (2) Domain-Specific Proficiency, and (3) Cultural Adaptation, emphasizing the need for holistic evaluation across these dimensions. We introduce TransBench, a benchmark tailored for industrial MT, initially targeting international e-commerce with 17,000 professionally translated sentences spanning 4 main scenarios and 33 language pairs. TransBench integrates traditional metrics (BLEU, TER) with Marco-MOS, a domain-specific evaluation model, and provides guidelines for reproducible benchmark construction. Our contributions include: (1) a structured framework for industrial MT evaluation, (2) the first publicly available benchmark for e-commerce translation, (3) novel metrics probing multi-level translation quality, and (4) open-sourced evaluation tools. This work bridges the evaluation gap, enabling researchers and practitioners to systematically assess and enhance MT systems for industry-specific needs.
Marco-LLM: Bridging Languages via Massive Multilingual Training for Cross-Lingual Enhancement
Dec 05, 2024Large Language Models (LLMs) have achieved remarkable progress in recent years; however, their excellent performance is still largely limited to major world languages, primarily English. Many LLMs continue to face challenges with multilingual tasks, especially when it comes to low-resource languages. To address this issue, we introduced Marco-LLM: Massive multilingual training for cross-lingual enhancement LLM. We have collected a substantial amount of multilingual data for several low-resource languages and conducted extensive continual pre-training using the Qwen2 models. This effort has resulted in a multilingual LLM named Marco-LLM. Through comprehensive evaluations on various multilingual benchmarks, including MMMLU, AGIEval, Belebele, Flores-200, XCOPA and many others, Marco-LLM has demonstrated substantial improvements over state-of-the-art LLMs. Furthermore, Marco-LLM achieved substantial enhancements in any-to-any machine translation tasks, showing the effectiveness of our multilingual LLM. Marco-LLM is a pioneering multilingual LLM designed to not only perform exceptionally well in multilingual tasks, including low-resource languages, but also maintain strong performance in English and other major languages, closing the performance gap between high- and low-resource language capabilities. By bridging languages, this effort demonstrates our dedication to ensuring LLMs work accurately across various languages.
Leveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval
Nov 03, 2021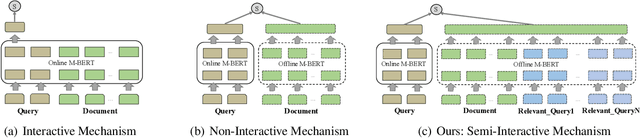
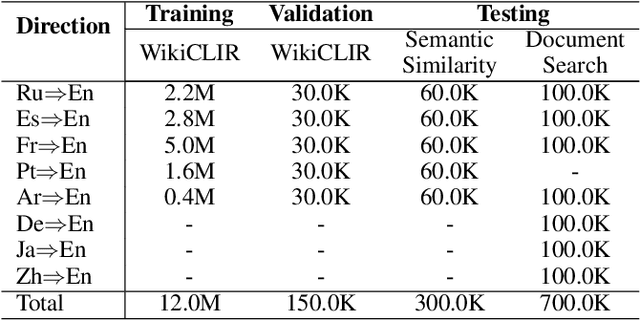
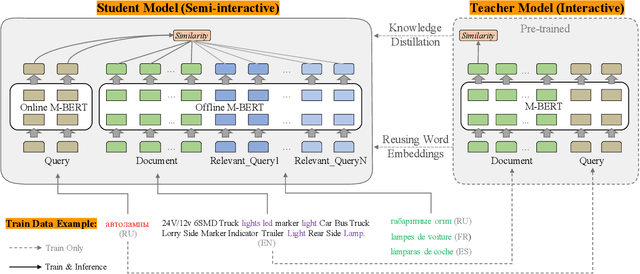

Interactive and non-interactive model are the two de-facto standard frameworks in vector-based cross-lingual information retrieval (V-CLIR), which embed queries and documents in synchronous and asynchronous fashions, respectively. From the retrieval accuracy and computational efficiency perspectives, each model has its own superiority and shortcoming. In this paper, we propose a novel framework to leverage the advantages of these two paradigms. Concretely, we introduce semi-interactive mechanism, which builds our model upon non-interactive architecture but encodes each document together with its associated multilingual queries. Accordingly, cross-lingual features can be better learned like an interactive model. Besides, we further transfer knowledge from a well-trained interactive model to ours by reusing its word embeddings and adopting knowledge distillation. Our model is initialized from a multilingual pre-trained language model M-BERT, and evaluated on two open-resource CLIR datasets derived from Wikipedia and an in-house dataset collected from a real-world search engine. Extensive analyses reveal that our methods significantly boost the retrieval accuracy while maintaining the computational efficiency.