 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval
Paper and Code
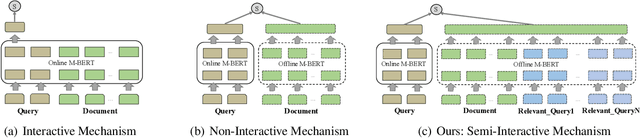
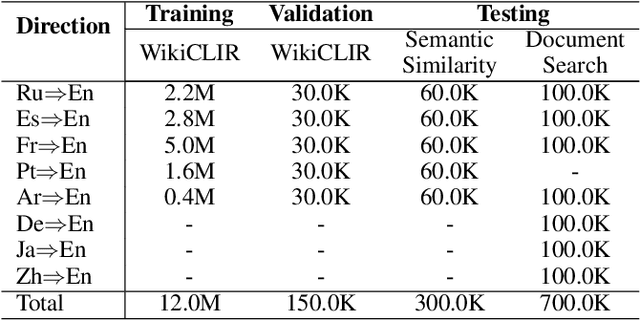
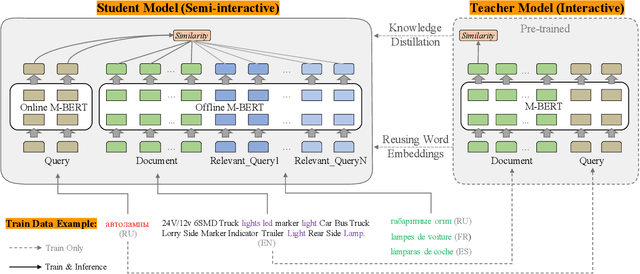

Interactive and non-interactive model are the two de-facto standard frameworks in vector-based cross-lingual information retrieval (V-CLIR), which embed queries and documents in synchronous and asynchronous fashions, respectively. From the retrieval accuracy and computational efficiency perspectives, each model has its own superiority and shortcoming. In this paper, we propose a novel framework to leverage the advantages of these two paradigms. Concretely, we introduce semi-interactive mechanism, which builds our model upon non-interactive architecture but encodes each document together with its associated multilingual queries. Accordingly, cross-lingual features can be better learned like an interactive model. Besides, we further transfer knowledge from a well-trained interactive model to ours by reusing its word embeddings and adopting knowledge distillation. Our model is initialized from a multilingual pre-trained language model M-BERT, and evaluated on two open-resource CLIR datasets derived from Wikipedia and an in-house dataset collected from a real-world search engine. Extensive analyses reveal that our methods significantly boost the retrieval accuracy while maintaining the computational efficiency.