 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoBLEURT Submission for the WMT2021 Metrics Task
Apr 28, 2022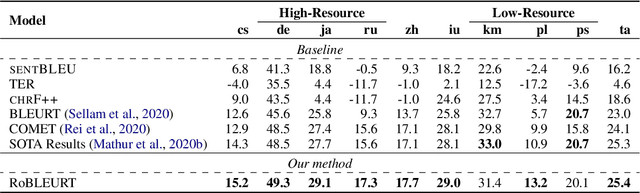

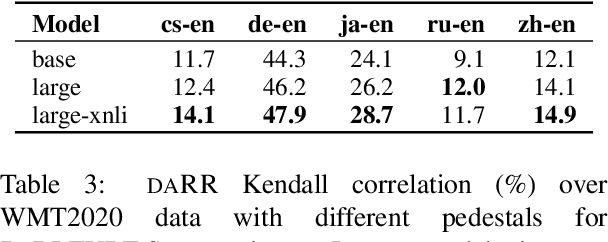
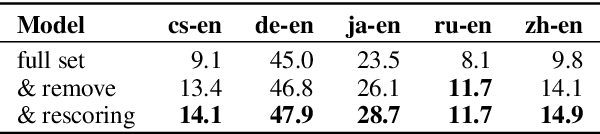
In this paper, we present our submission to Shared Metrics Task: RoBLEURT (Robustly Optimizing the training of BLEURT). After investigating the recent advances of trainable metrics, we conclude several aspects of vital importance to obtain a well-performed metric model by: 1) jointly leveraging the advantages of source-included model and reference-only model, 2) continuously pre-training the model with massive synthetic data pairs, and 3) fine-tuning the model with data denoising strategy. Experimental results show that our model reaching state-of-the-art correlations with the WMT2020 human annotations upon 8 out of 10 to-English language pairs.
Leveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval
Nov 03, 2021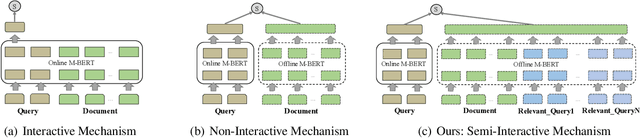
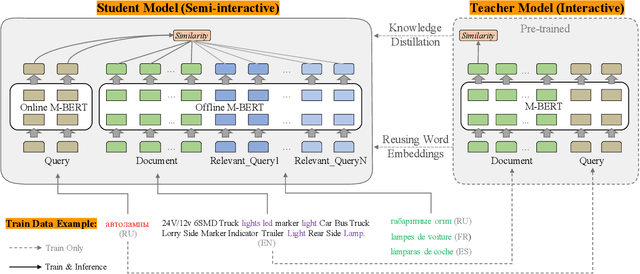

Interactive and non-interactive model are the two de-facto standard frameworks in vector-based cross-lingual information retrieval (V-CLIR), which embed queries and documents in synchronous and asynchronous fashions, respectively. From the retrieval accuracy and computational efficiency perspectives, each model has its own superiority and shortcoming. In this paper, we propose a novel framework to leverage the advantages of these two paradigms. Concretely, we introduce semi-interactive mechanism, which builds our model upon non-interactive architecture but encodes each document together with its associated multilingual queries. Accordingly, cross-lingual features can be better learned like an interactive model. Besides, we further transfer knowledge from a well-trained interactive model to ours by reusing its word embeddings and adopting knowledge distillation. Our model is initialized from a multilingual pre-trained language model M-BERT, and evaluated on two open-resource CLIR datasets derived from Wikipedia and an in-house dataset collected from a real-world search engine. Extensive analyses reveal that our methods significantly boost the retrieval accuracy while maintaining the computational efficiency.
Constraint Translation Candidates: A Bridge between Neural Query Translation and Cross-lingual Information Retrieval
Oct 26, 2020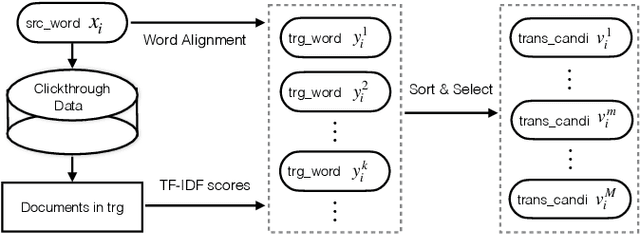
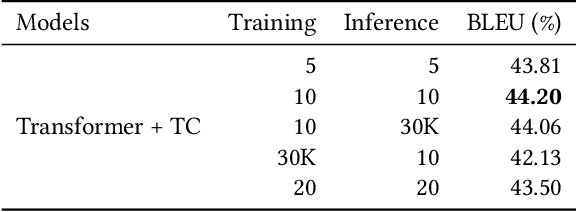
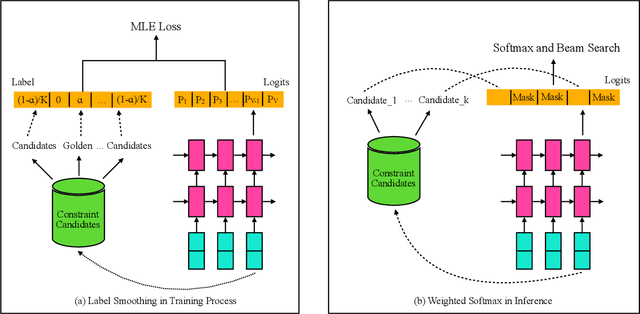
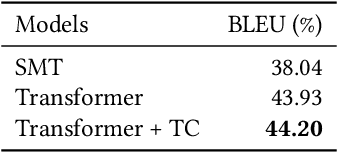
Query translation (QT) is a key component in cross-lingual information retrieval system (CLIR). With the help of deep learning, neural machine translation (NMT) has shown promising results on various tasks. However, NMT is generally trained with large-scale out-of-domain data rather than in-domain query translation pairs. Besides, the translation model lacks a mechanism at the inference time to guarantee the generated words to match the search index. The two shortages of QT result in readable texts for human but inadequate candidates for the downstream retrieval task. In this paper, we propose a novel approach to alleviate these problems by limiting the open target vocabulary search space of QT to a set of important words mined from search index database. The constraint translation candidates are employed at both of training and inference time, thus guiding the translation model to learn and generate well performing target queries. The proposed methods are exploited and examined in a real-word CLIR system--Aliexpress e-Commerce search engine. Experimental results demonstrate that our approach yields better performance on both translation quality and retrieval accuracy than the strong NMT baseline.
Multi-agent Learning for Neural Machine Translation
Sep 03, 2019
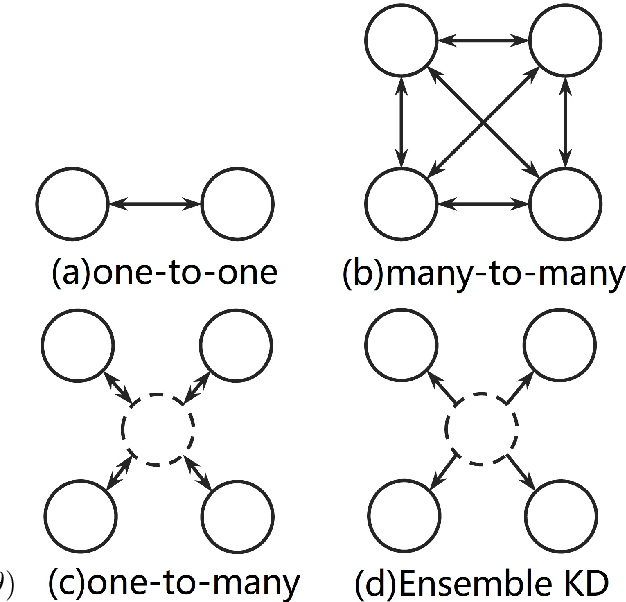
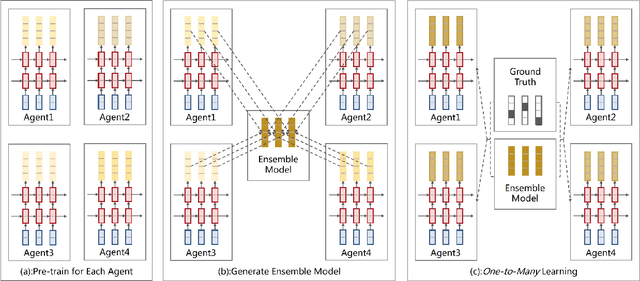
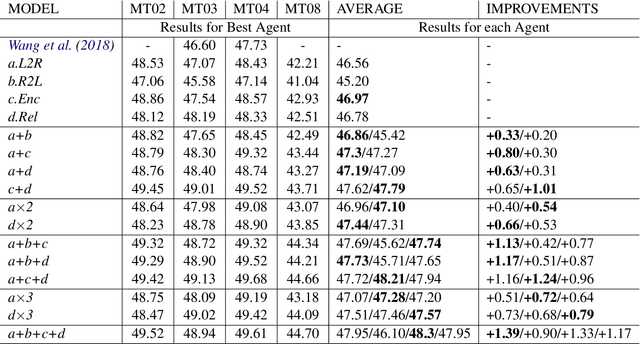
Conventional Neural Machine Translation (NMT) models benefit from the training with an additional agent, e.g., dual learning, and bidirectional decoding with one agent decoding from left to right and the other decoding in the opposite direction. In this paper, we extend the training framework to the multi-agent scenario by introducing diverse agents in an interactive updating process. At training time, each agent learns advanced knowledge from others, and they work together to improve translation quality. Experimental results on NIST Chinese-English, IWSLT 2014 German-English, WMT 2014 English-German and large-scale Chinese-English translation tasks indicate that our approach achieves absolute improvements over the strong baseline systems and shows competitive performance on all tasks.