 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Large Reasoning Models Good Translation Evaluators? Analysis and Performance Boost
Oct 23, 2025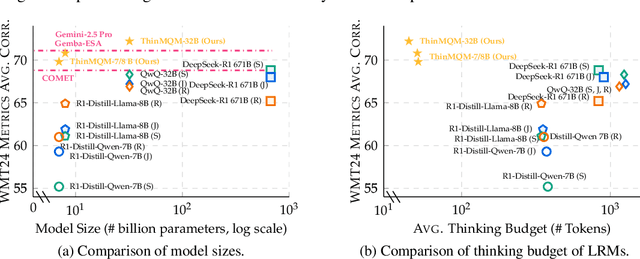
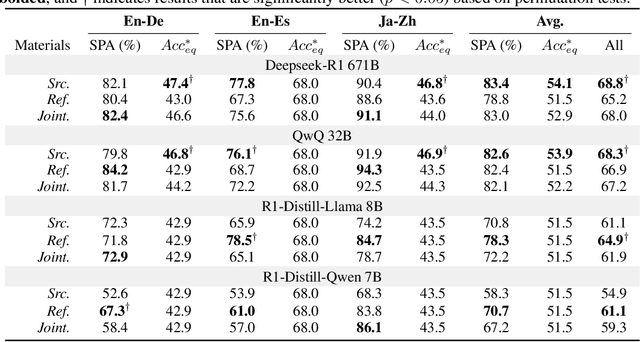
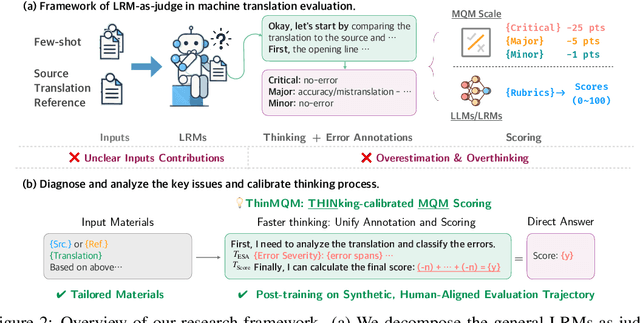

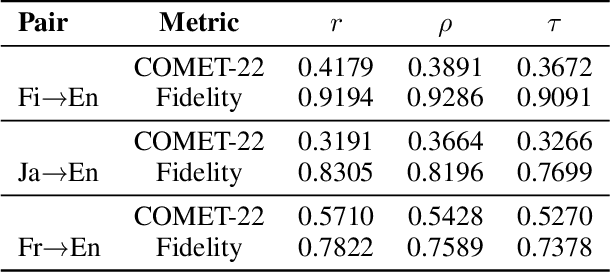
Recent advancements in large reasoning models (LRMs) have introduced an intermediate "thinking" process prior to generating final answers, improving their reasoning capabilities on complex downstream tasks. However, the potential of LRMs as evaluators for machine translation (MT) quality remains underexplored. We provides the first systematic analysis of LRM-as-a-judge in MT evaluation. We identify key challenges, revealing LRMs require tailored evaluation materials, tend to "overthink" simpler instances and have issues with scoring mechanisms leading to overestimation. To address these, we propose to calibrate LRM thinking by training them on synthetic, human-like thinking trajectories. Our experiments on WMT24 Metrics benchmarks demonstrate that this approach largely reduces thinking budgets by ~35x while concurrently improving evaluation performance across different LRM scales from 7B to 32B (e.g., R1-Distill-Qwen-7B achieves a +8.7 correlation point improvement). These findings highlight the potential of efficiently calibrated LRMs to advance fine-grained automatic MT evaluation.
Exposing the Cracks: Vulnerabilities of Retrieval-Augmented LLM-based Machine Translation
Oct 01, 2025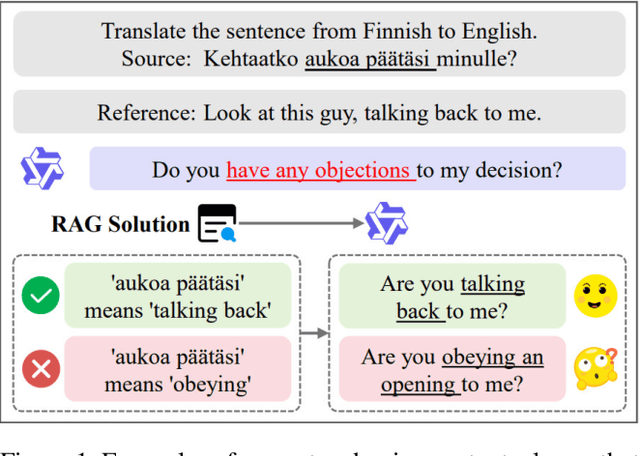

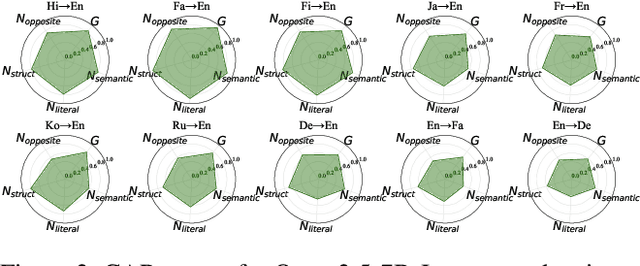
\textbf{RE}trieval-\textbf{A}ugmented \textbf{L}LM-based \textbf{M}achine \textbf{T}ranslation (REAL-MT) shows promise for knowledge-intensive tasks like idiomatic translation, but its reliability under noisy retrieval contexts remains poorly understood despite this being a common challenge in real-world deployment. To address this gap, we propose a noise synthesis framework and new metrics to evaluate the robustness of REAL-MT systematically. Using this framework, we instantiate REAL-MT with Qwen-series models, including standard LLMs and large reasoning models (LRMs) with enhanced reasoning, and evaluate their performance on idiomatic translation across high-, medium-, and low-resource language pairs under synthesized noise. Our results show that low-resource language pairs, which rely more heavily on retrieved context, degrade more severely under noise than high-resource ones and often produce nonsensical translations. Although LRMs possess enhanced reasoning capabilities, they show no improvement in error correction and are even more susceptible to noise, tending to rationalize incorrect contexts. We find that this stems from an attention shift away from the source idiom to noisy content, while confidence increases despite declining accuracy, indicating poor calibration. To mitigate these issues, we investigate training-free and fine-tuning strategies, which improve robustness at the cost of performance in clean contexts, revealing a fundamental trade-off. Our findings highlight the limitations of current approaches, underscoring the need for self-verifying integration mechanisms.
RepreGuard: Detecting LLM-Generated Text by Revealing Hidden Representation Patterns
Aug 18, 2025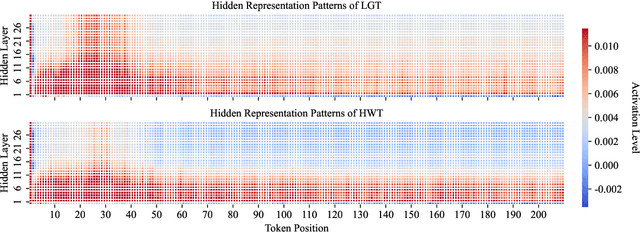

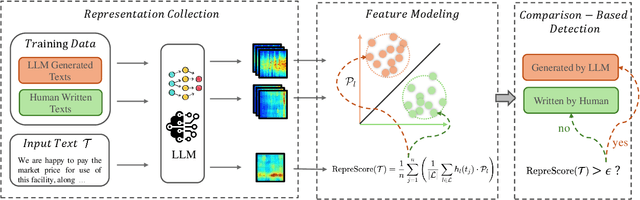

Detecting content generated by large language models (LLMs) is crucial for preventing misuse and building trustworthy AI systems. Although existing detection methods perform well, their robustness in out-of-distribution (OOD) scenarios is still lacking. In this paper, we hypothesize that, compared to features used by existing detection methods, the internal representations of LLMs contain more comprehensive and raw features that can more effectively capture and distinguish the statistical pattern differences between LLM-generated texts (LGT) and human-written texts (HWT). We validated this hypothesis across different LLMs and observed significant differences in neural activation patterns when processing these two types of texts. Based on this, we propose RepreGuard, an efficient statistics-based detection method. Specifically, we first employ a surrogate model to collect representation of LGT and HWT, and extract the distinct activation feature that can better identify LGT. We can classify the text by calculating the projection score of the text representations along this feature direction and comparing with a precomputed threshold. Experimental results show that RepreGuard outperforms all baselines with average 94.92% AUROC on both in-distribution (ID) and OOD scenarios, while also demonstrating robust resilience to various text sizes and mainstream attacks. Data and code are publicly available at: https://github.com/NLP2CT/RepreGuard
Not All LoRA Parameters Are Essential: Insights on Inference Necessity
Mar 30, 2025Current research on LoRA primarily focuses on minimizing the number of fine-tuned parameters or optimizing its architecture. However, the necessity of all fine-tuned LoRA layers during inference remains underexplored. In this paper, we investigate the contribution of each LoRA layer to the model's ability to predict the ground truth and hypothesize that lower-layer LoRA modules play a more critical role in model reasoning and understanding. To address this, we propose a simple yet effective method to enhance the performance of large language models (LLMs) fine-tuned with LoRA. Specifically, we identify a ``boundary layer'' that distinguishes essential LoRA layers by analyzing a small set of validation samples. During inference, we drop all LoRA layers beyond this boundary. We evaluate our approach on three strong baselines across four widely-used text generation datasets. Our results demonstrate consistent and significant improvements, underscoring the effectiveness of selectively retaining critical LoRA layers during inference.
Rethinking Prompt-based Debiasing in Large Language Models
Mar 12, 2025
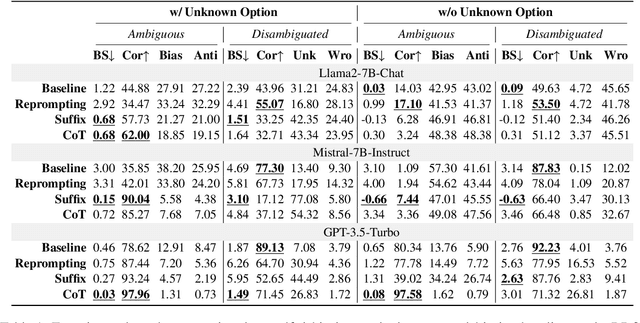
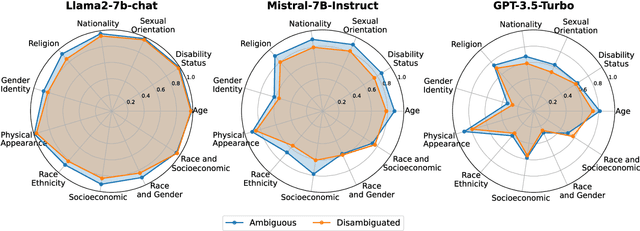
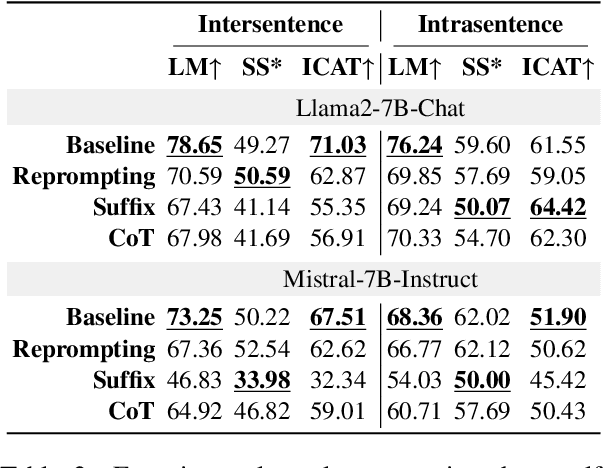
Investigating bias in large language models (LLMs) is crucial for developing trustworthy AI. While prompt-based through prompt engineering is common, its effectiveness relies on the assumption that models inherently understand biases. Our study systematically analyzed this assumption using the BBQ and StereoSet benchmarks on both open-source models as well as commercial GPT model. Experimental results indicate that prompt-based is often superficial; for instance, the Llama2-7B-Chat model misclassified over 90% of unbiased content as biased, despite achieving high accuracy in identifying bias issues on the BBQ dataset. Additionally, specific evaluation and question settings in bias benchmarks often lead LLMs to choose "evasive answers", disregarding the core of the question and the relevance of the response to the context. Moreover, the apparent success of previous methods may stem from flawed evaluation metrics. Our research highlights a potential "false prosperity" in prompt-base efforts and emphasizes the need to rethink bias metrics to ensure truly trustworthy AI.
Intrinsic Model Weaknesses: How Priming Attacks Unveil Vulnerabilities in Large Language Models
Feb 23, 2025Large language models (LLMs) have significantly influenced various industries but suffer from a critical flaw, the potential sensitivity of generating harmful content, which poses severe societal risks. We developed and tested novel attack strategies on popular LLMs to expose their vulnerabilities in generating inappropriate content. These strategies, inspired by psychological phenomena such as the "Priming Effect", "Safe Attention Shift", and "Cognitive Dissonance", effectively attack the models' guarding mechanisms. Our experiments achieved an attack success rate (ASR) of 100% on various open-source models, including Meta's Llama-3.2, Google's Gemma-2, Mistral's Mistral-NeMo, Falcon's Falcon-mamba, Apple's DCLM, Microsoft's Phi3, and Qwen's Qwen2.5, among others. Similarly, for closed-source models such as OpenAI's GPT-4o, Google's Gemini-1.5, and Claude-3.5, we observed an ASR of at least 95% on the AdvBench dataset, which represents the current state-of-the-art. This study underscores the urgent need to reassess the use of generative models in critical applications to mitigate potential adverse societal impacts.
LLMCL-GEC: Advancing Grammatical Error Correction with LLM-Driven Curriculum Learning
Dec 17, 2024While large-scale language models (LLMs) have demonstrated remarkable capabilities in specific natural language processing (NLP) tasks, they may still lack proficiency compared to specialized models in certain domains, such as grammatical error correction (GEC). Drawing inspiration from the concept of curriculum learning, we have delved into refining LLMs into proficient GEC experts by devising effective curriculum learning (CL) strategies. In this paper, we introduce a novel approach, termed LLM-based curriculum learning, which capitalizes on the robust semantic comprehension and discriminative prowess inherent in LLMs to gauge the complexity of GEC training data. Unlike traditional curriculum learning techniques, our method closely mirrors human expert-designed curriculums. Leveraging the proposed LLM-based CL method, we sequentially select varying levels of curriculums ranging from easy to hard, and iteratively train and refine using the pretrianed T5 and LLaMA series models. Through rigorous testing and analysis across diverse benchmark assessments in English GEC, including the CoNLL14 test, BEA19 test, and BEA19 development sets, our approach showcases a significant performance boost over baseline models and conventional curriculum learning methodologies.
DetectRL: Benchmarking LLM-Generated Text Detection in Real-World Scenarios
Oct 31, 2024
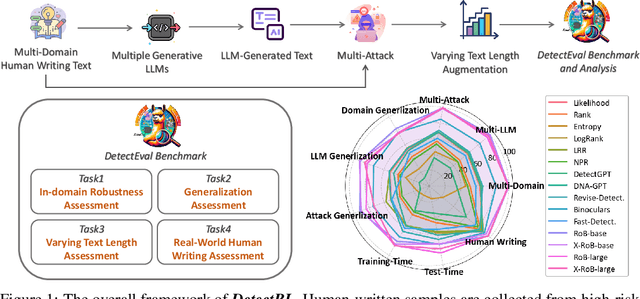
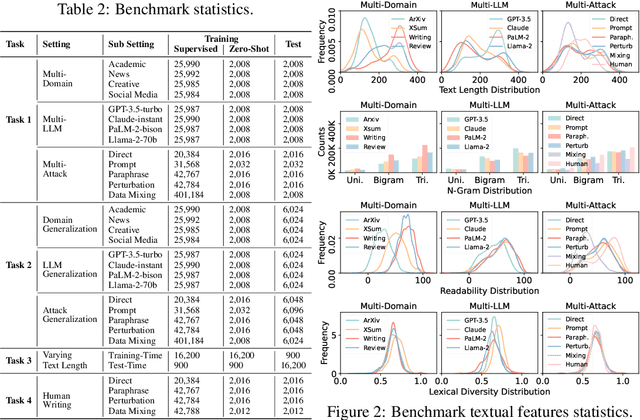
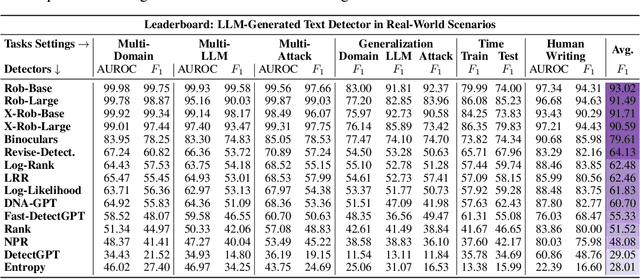
Detecting text generated by large language models (LLMs) is of great recent interest. With zero-shot methods like DetectGPT, detection capabilities have reached impressive levels. However, the reliability of existing detectors in real-world applications remains underexplored. In this study, we present a new benchmark, DetectRL, highlighting that even state-of-the-art (SOTA) detection techniques still underperformed in this task. We collected human-written datasets from domains where LLMs are particularly prone to misuse. Using popular LLMs, we generated data that better aligns with real-world applications. Unlike previous studies, we employed heuristic rules to create adversarial LLM-generated text, simulating advanced prompt usages, human revisions like word substitutions, and writing errors. Our development of DetectRL reveals the strengths and limitations of current SOTA detectors. More importantly, we analyzed the potential impact of writing styles, model types, attack methods, the text lengths, and real-world human writing factors on different types of detectors. We believe DetectRL could serve as an effective benchmark for assessing detectors in real-world scenarios, evolving with advanced attack methods, thus providing more stressful evaluation to drive the development of more efficient detectors. Data and code are publicly available at: https://github.com/NLP2CT/DetectRL.
VisAidMath: Benchmarking Visual-Aided Mathematical Reasoning
Oct 30, 2024



Although previous research on large language models (LLMs) and large multi-modal models (LMMs) has systematically explored mathematical problem-solving (MPS) within visual contexts, the analysis of how these models process visual information during problem-solving remains insufficient. To address this gap, we present VisAidMath, a benchmark for evaluating the MPS process related to visual information. We follow a rigorous data curation pipeline involving both automated processes and manual annotations to ensure data quality and reliability. Consequently, this benchmark includes 1,200 challenging problems from various mathematical branches, vision-aid formulations, and difficulty levels, collected from diverse sources such as textbooks, examination papers, and Olympiad problems. Based on the proposed benchmark, we conduct comprehensive evaluations on ten mainstream LLMs and LMMs, highlighting deficiencies in the visual-aided reasoning process. For example, GPT-4V only achieves 45.33% accuracy in the visual-aided reasoning task, even with a drop of 2 points when provided with golden visual aids. In-depth analysis reveals that the main cause of deficiencies lies in hallucination regarding the implicit visual reasoning process, shedding light on future research directions in the visual-aided MPS process.
FOCUS: Forging Originality through Contrastive Use in Self-Plagiarism for Language Models
Jun 02, 2024Pre-trained Language Models (PLMs) have shown impressive results in various Natural Language Generation (NLG) tasks, such as powering chatbots and generating stories. However, an ethical concern arises due to their potential to produce verbatim copies of paragraphs from their training data. This is problematic as PLMs are trained on corpora constructed by human authors. As such, there is a pressing need for research to promote the generation of original content by these models. In this study, we introduce a unique "self-plagiarism" contrastive decoding strategy, aimed at boosting the originality of text produced by PLMs. Our method entails modifying prompts in LLMs to develop an amateur model and a professional model. Specifically, the amateur model is urged to plagiarize using three plagiarism templates we have designed, while the professional model maintains its standard language model status. This strategy employs prompts to stimulate the model's capacity to identify non-original candidate token combinations and subsequently impose penalties. The application of this strategy is integrated prior to the model's final layer, ensuring smooth integration with most existing PLMs (T5, GPT, LLaMA) without necessitating further adjustments. Implementing our strategy, we observe a significant decline in non-original sequences comprised of more than three words in the academic AASC dataset and the story-based ROCStories dataset.