 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedaVinci-LLM:Towards the Science of Pretraining
Mar 28, 2026The foundational pretraining phase determines a model's capability ceiling, as post-training struggles to overcome capability foundations established during pretraining, yet it remains critically under-explored. This stems from a structural paradox: organizations with computational resources operate under commercial pressures that inhibit transparent disclosure, while academic institutions possess research freedom but lack pretraining-scale computational resources. daVinci-LLM occupies this unexplored intersection, combining industrial-scale resources with full research freedom to advance the science of pretraining. We adopt a fully-open paradigm that treats openness as scientific methodology, releasing complete data processing pipelines, full training processes, and systematic exploration results. Recognizing that the field lacks systematic methodology for data processing, we employ the Data Darwinism framework, a principled L0-L9 taxonomy from filtering to synthesis. We train a 3B-parameter model from random initialization across 8T tokens using a two-stage adaptive curriculum that progressively shifts from foundational capabilities to reasoning-intensive enhancement. Through 200+ controlled ablations, we establish that: processing depth systematically enhances capabilities, establishing it as a critical dimension alongside volume scaling; different domains exhibit distinct saturation dynamics, necessitating adaptive strategies from proportion adjustments to format shifts; compositional balance enables targeted intensification while preventing performance collapse; how evaluation protocol choices shape our understanding of pretraining progress. By releasing the complete exploration process, we enable the community to build upon our findings and systematic methodologies to form accumulative scientific knowledge in pretraining.
daVinci-Env: Open SWE Environment Synthesis at Scale
Mar 16, 2026Training capable software engineering (SWE) agents demands large-scale, executable, and verifiable environments that provide dynamic feedback loops for iterative code editing, test execution, and solution refinement. However, existing open-source datasets remain limited in scale and repository diversity, while industrial solutions are opaque with unreleased infrastructure, creating a prohibitive barrier for most academic research groups. We present OpenSWE, the largest fully transparent framework for SWE agent training in Python, comprising 45,320 executable Docker environments spanning over 12.8k repositories, with all Dockerfiles, evaluation scripts, and infrastructure fully open-sourced for reproducibility. OpenSWE is built through a multi-agent synthesis pipeline deployed across a 64-node distributed cluster, automating repository exploration, Dockerfile construction, evaluation script generation, and iterative test analysis. Beyond scale, we propose a quality-centric filtering pipeline that characterizes the inherent difficulty of each environment, filtering out instances that are either unsolvable or insufficiently challenging and retaining only those that maximize learning efficiency. With $891K spent on environment construction and an additional $576K on trajectory sampling and difficulty-aware curation, the entire project represents a total investment of approximately $1.47 million, yielding about 13,000 curated trajectories from roughly 9,000 quality guaranteed environments. Extensive experiments validate OpenSWE's effectiveness: OpenSWE-32B and OpenSWE-72B achieve 62.4% and 66.0% on SWE-bench Verified, establishing SOTA among Qwen2.5 series. Moreover, SWE-focused training yields substantial out-of-domain improvements, including up to 12 points on mathematical reasoning and 5 points on science benchmarks, without degrading factual recall.
The Curse and Blessing of Mean Bias in FP4-Quantized LLM Training
Mar 11, 2026Large language models trained on natural language exhibit pronounced anisotropy: a small number of directions concentrate disproportionate energy, while the remaining dimensions form a broad semantic tail. In low-bit training regimes, this geometry becomes numerically unstable. Because blockwise quantization scales are determined by extreme elementwise magnitudes, dominant directions stretch the dynamic range, compressing long-tail semantic variation into narrow numerical bins. We show that this instability is primarily driven by a coherent rank-one mean bias, which constitutes the dominant component of spectral anisotropy in LLM representations. This mean component emerges systematically across layers and training stages and accounts for the majority of extreme activation magnitudes, making it the principal driver of dynamic-range inflation under low precision. Crucially, because the dominant instability is rank-one, it can be eliminated through a simple source-level mean-subtraction operation. This bias-centric conditioning recovers most of the stability benefits of SVD-based spectral methods while requiring only reduction operations and standard quantization kernels. Empirical results on FP4 (W4A4G4) training show that mean removal substantially narrows the loss gap to BF16 and restores downstream performance, providing a hardware-efficient path to stable low-bit LLM training.
SD-MoE: Spectral Decomposition for Effective Expert Specialization
Feb 13, 2026Mixture-of-Experts (MoE) architectures scale Large Language Models via expert specialization induced by conditional computation. In practice, however, expert specialization often fails: some experts become functionally similar, while others functioning as de facto shared experts, limiting the effective capacity and model performance. In this work, we analysis from a spectral perspective on parameter and gradient spaces, uncover that (1) experts share highly overlapping dominant spectral components in their parameters, (2) dominant gradient subspaces are strongly aligned across experts, driven by ubiquitous low-rank structure in human corpus, and (3) gating mechanisms preferentially route inputs along these dominant directions, further limiting specialization. To address this, we propose Spectral-Decoupled MoE (SD-MoE), which decomposes both parameter and gradient in the spectral space. SD-MoE improves performance across downstream tasks, enables effective expert specialization, incurring minimal additional computation, and can be seamlessly integrated into a wide range of existing MoE architectures, including Qwen and DeepSeek.
Multi-Head Attention as a Source of Catastrophic Forgetting in MoE Transformers
Feb 13, 2026Mixture-of-Experts (MoE) architectures are often considered a natural fit for continual learning because sparse routing should localize updates and reduce interference, yet MoE Transformers still forget substantially even with sparse, well-balanced expert utilization. We attribute this gap to a pre-routing bottleneck: multi-head attention concatenates head-specific signals into a single post-attention router input, forcing routing to act on co-occurring feature compositions rather than separable head channels. We show that this router input simultaneously encodes multiple separately decodable semantic and structural factors with uneven head support, and that different feature compositions induce weakly aligned parameter-gradient directions; as a result, routing maps many distinct compositions to the same route. We quantify this collision effect via a route-wise effective composition number $N_{eff}$ and find that higher $N_{eff}$ is associated with larger old-task loss increases after continual training. Motivated by these findings, we propose MH-MoE, which performs head-wise routing over sub-representations to increase routing granularity and reduce composition collisions. On TRACE with Qwen3-0.6B/8B, MH-MoE effectively mitigates forgetting, reducing BWT on Qwen3-0.6B from 11.2% (LoRAMoE) to 4.5%.
SRPO: Self-Referential Policy Optimization for Vision-Language-Action Models
Nov 19, 2025Vision-Language-Action (VLA) models excel in robotic manipulation but are constrained by their heavy reliance on expert demonstrations, leading to demonstration bias and limiting performance. Reinforcement learning (RL) is a vital post-training strategy to overcome these limits, yet current VLA-RL methods, including group-based optimization approaches, are crippled by severe reward sparsity. Relying on binary success indicators wastes valuable information in failed trajectories, resulting in low training efficiency. To solve this, we propose Self-Referential Policy Optimization (SRPO), a novel VLA-RL framework. SRPO eliminates the need for external demonstrations or manual reward engineering by leveraging the model's own successful trajectories, generated within the current training batch, as a self-reference. This allows us to assign a progress-wise reward to failed attempts. A core innovation is the use of latent world representations to measure behavioral progress robustly. Instead of relying on raw pixels or requiring domain-specific fine-tuning, we utilize the compressed, transferable encodings from a world model's latent space. These representations naturally capture progress patterns across environments, enabling accurate, generalized trajectory comparison. Empirical evaluations on the LIBERO benchmark demonstrate SRPO's efficiency and effectiveness. Starting from a supervised baseline with 48.9% success, SRPO achieves a new state-of-the-art success rate of 99.2% in just 200 RL steps, representing a 103% relative improvement without any extra supervision. Furthermore, SRPO shows substantial robustness, achieving a 167% performance improvement on the LIBERO-Plus benchmark.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
LLMCL-GEC: Advancing Grammatical Error Correction with LLM-Driven Curriculum Learning
Dec 17, 2024While large-scale language models (LLMs) have demonstrated remarkable capabilities in specific natural language processing (NLP) tasks, they may still lack proficiency compared to specialized models in certain domains, such as grammatical error correction (GEC). Drawing inspiration from the concept of curriculum learning, we have delved into refining LLMs into proficient GEC experts by devising effective curriculum learning (CL) strategies. In this paper, we introduce a novel approach, termed LLM-based curriculum learning, which capitalizes on the robust semantic comprehension and discriminative prowess inherent in LLMs to gauge the complexity of GEC training data. Unlike traditional curriculum learning techniques, our method closely mirrors human expert-designed curriculums. Leveraging the proposed LLM-based CL method, we sequentially select varying levels of curriculums ranging from easy to hard, and iteratively train and refine using the pretrianed T5 and LLaMA series models. Through rigorous testing and analysis across diverse benchmark assessments in English GEC, including the CoNLL14 test, BEA19 test, and BEA19 development sets, our approach showcases a significant performance boost over baseline models and conventional curriculum learning methodologies.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
Tencent ML-Images: A Large-Scale Multi-Label Image Database for Visual Representation Learning
Jan 08, 2019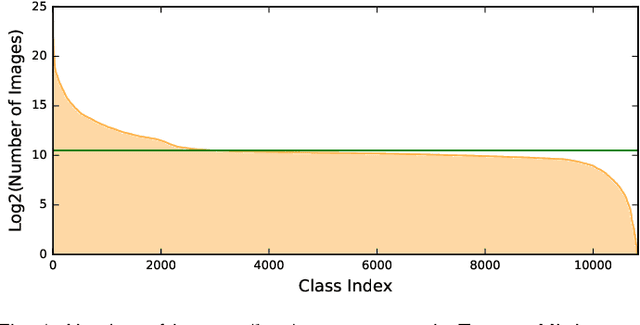
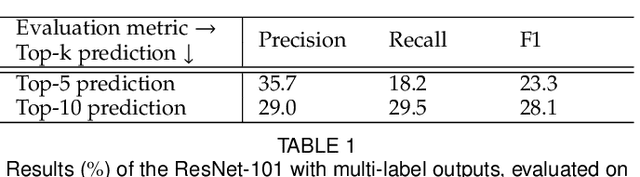
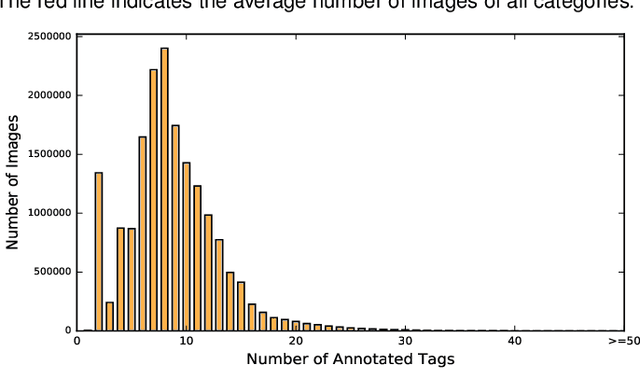
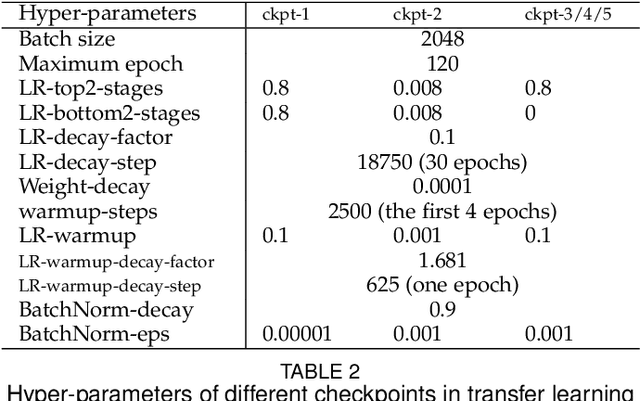
In existing visual representation learning tasks, deep convolutional neural networks (CNNs) are often trained on images annotated with single tags, such as ImageNet. However, a single tag cannot describe all important contents of one image, and some useful visual information may be wasted during training. In this work, we propose to train CNNs from images annotated with multiple tags, to enhance the quality of visual representation of the trained CNN model. To this end, we build a large-scale multi-label image database with 18M images and 11K categories, dubbed Tencent ML-Images. We efficiently train the ResNet-101 model with multi-label outputs on Tencent ML-Images, taking 90 hours for 60 epochs, based on a large-scale distributed deep learning framework,i.e.,TFplus. The good quality of the visual representation of the Tencent ML-Images checkpoint is verified through three transfer learning tasks, including single-label image classification on ImageNet and Caltech-256, object detection on PASCAL VOC 2007, and semantic segmentation on PASCAL VOC 2012. The Tencent ML-Images database, the checkpoints of ResNet-101, and all the training codehave been released at https://github.com/Tencent/tencent-ml-images. It is expected to promote other vision tasks in the research and industry community.