 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025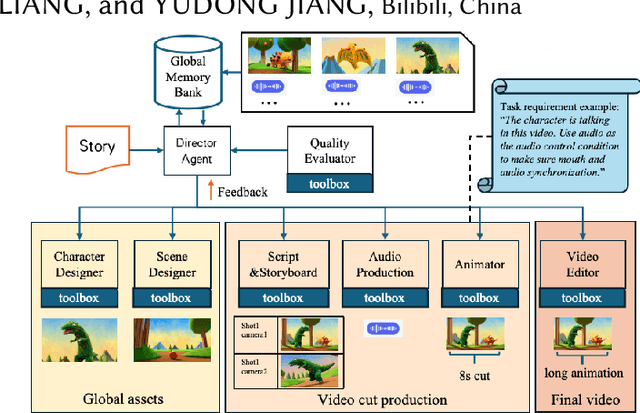

We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025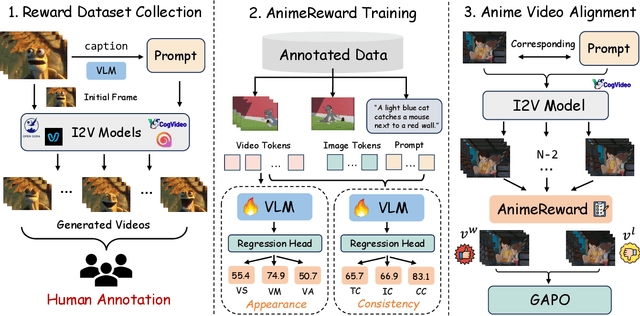

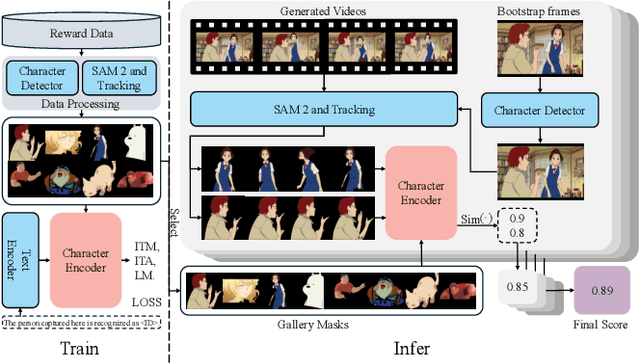
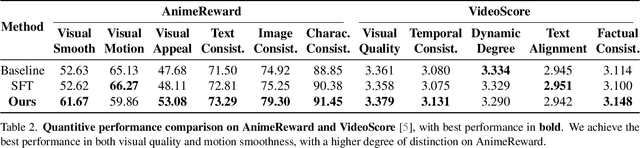
Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
Fast Automatic Feature Selection for Multi-Period Sliding Window Aggregate in Time Series
Dec 02, 2020
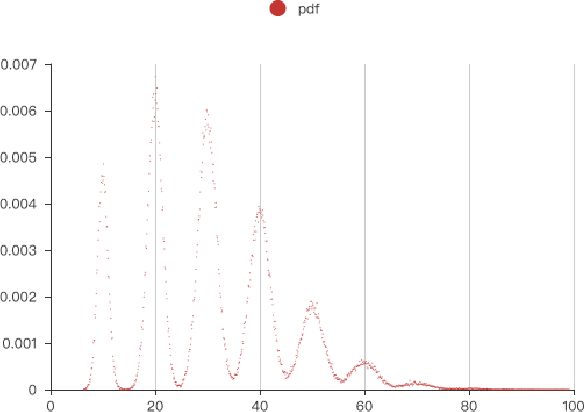
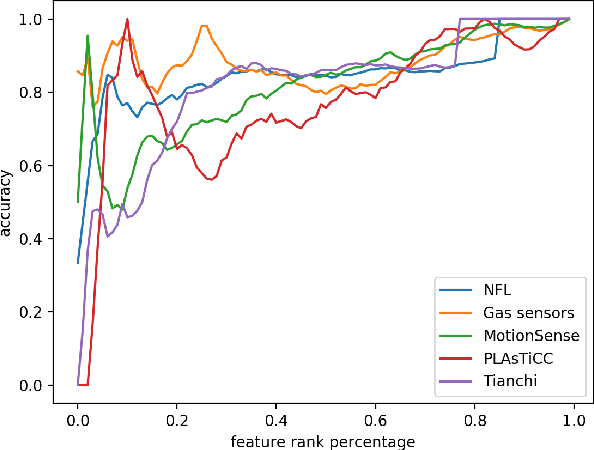
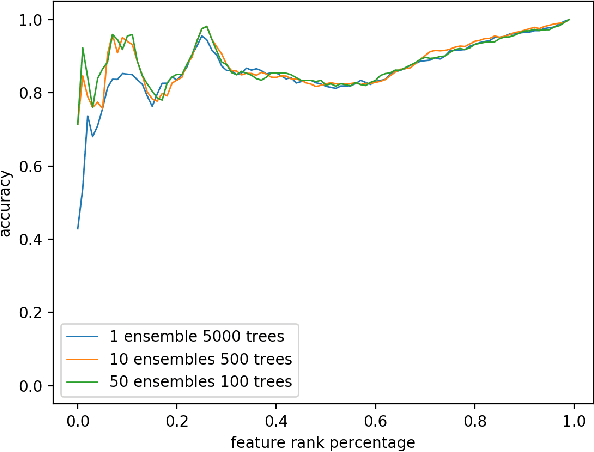
As one of the most well-known artificial feature sampler, the sliding window is widely used in scenarios where spatial and temporal information exists, such as computer vision, natural language process, data stream, and time series. Among which time series is common in many scenarios like credit card payment, user behavior, and sensors. General feature selection for features extracted by sliding window aggregate calls for time-consuming iteration to generate features, and then traditional feature selection methods are employed to rank them. The decision of key parameter, i.e. the period of sliding windows, depends on the domain knowledge and calls for trivial. Currently, there is no automatic method to handle the sliding window aggregate features selection. As the time consumption of feature generation with different periods and sliding windows is huge, it is very hard to enumerate them all and then select them. In this paper, we propose a general framework using Markov Chain to solve this problem. This framework is very efficient and has high accuracy, such that it is able to perform feature selection on a variety of features and period options. We show the detail by 2 common sliding windows and 3 types of aggregation operators. And it is easy to extend more sliding windows and aggregation operators in this framework by employing existing theory about Markov Chain.
Video Crowd Counting via Dynamic Temporal Modeling
Jul 04, 2019

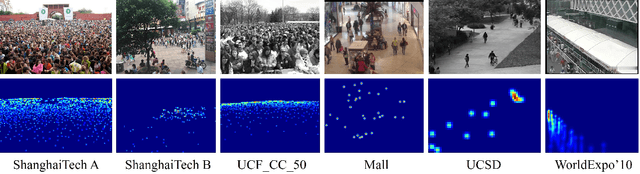
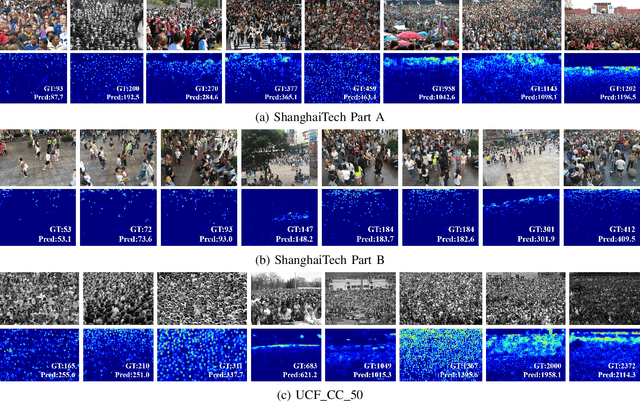
Crowd counting aims to count the number of instantaneous people in a crowded space, which plays an increasingly important role in the field of public safety. More and more researchers have already proposed many promising solutions to the crowd counting task on the image. With the continuous extension of the application of crowd counting, how to apply the technique to video content has become an urgent problem. At present, although researchers have collected and labeled some video clips, less attention has been drawn to the spatiotemporal characteristics of videos. In order to solve this problem, this paper proposes a novel framework based on dynamic temporal modeling of the relationship between video frames. We model the relationship between adjacent features by constructing a set of dilated residual blocks for crowd counting task, with each phase having an expanded set of time convolutions to generate an initial prediction which is then improved by the next prediction. We extract features from the density map as we find the adjacent density maps share more similar information than original video frames. We also propose a smaller basic network structure to balance the computational cost with a good feature representation. We conduct experiments using the proposed framework on five crowd counting datasets and demonstrate its superiority in terms of effectiveness and efficiency over previous approaches.
Heterogeneous Knowledge Transfer in Video Emotion Recognition, Attribution and Summarization
Feb 20, 2018


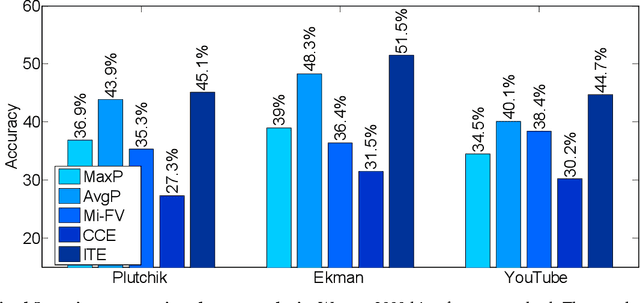
Emotion is a key element in user-generated videos. However, it is difficult to understand emotions conveyed in such videos due to the complex and unstructured nature of user-generated content and the sparsity of video frames expressing emotion. In this paper, for the first time, we study the problem of transferring knowledge from heterogeneous external sources, including image and textual data, to facilitate three related tasks in understanding video emotion: emotion recognition, emotion attribution and emotion-oriented summarization. Specifically, our framework (1) learns a video encoding from an auxiliary emotional image dataset in order to improve supervised video emotion recognition, and (2) transfers knowledge from an auxiliary textual corpora for zero-shot recognition of emotion classes unseen during training. The proposed technique for knowledge transfer facilitates novel applications of emotion attribution and emotion-oriented summarization. A comprehensive set of experiments on multiple datasets demonstrate the effectiveness of our framework.
* 13 pages, 11 figures. Published at the IEEE Transactions on Affective Computing