 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025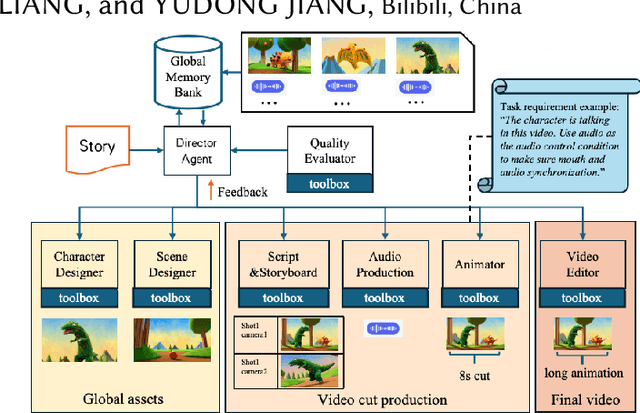
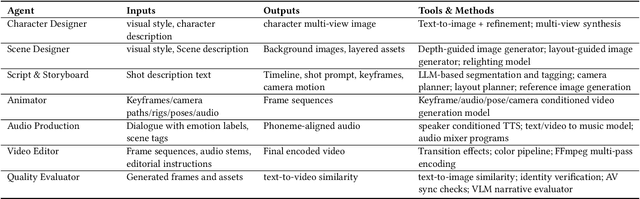

We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025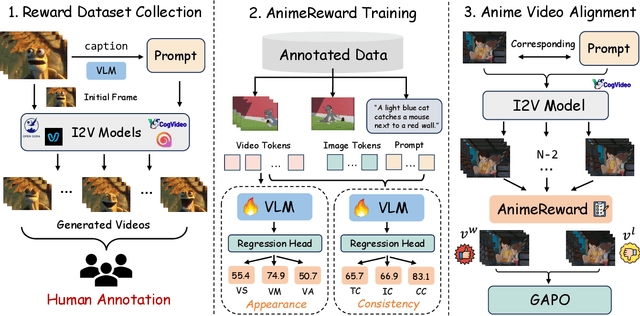

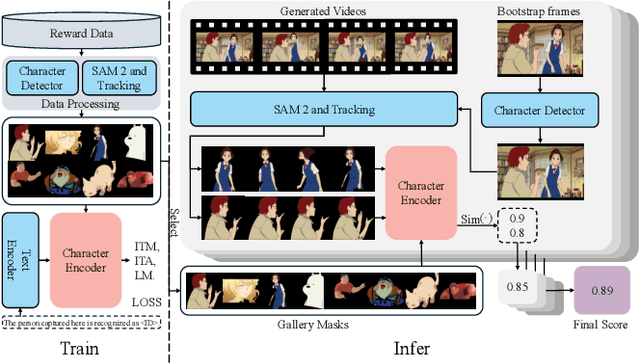
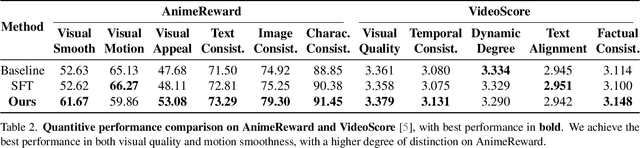
Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
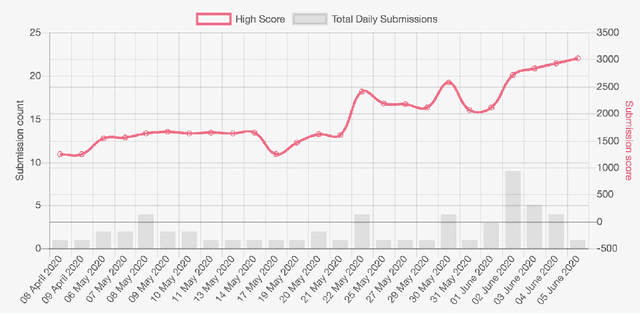
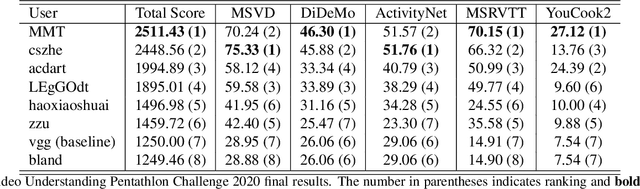
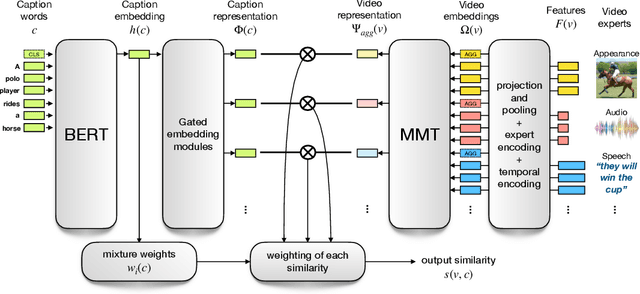
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.
Comprehensive Soccer Video Understanding: Towards Human-comparable Video Understanding System in Constrained Environment
Dec 13, 2019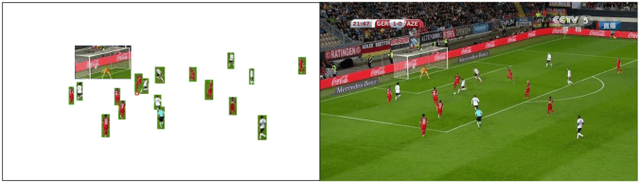
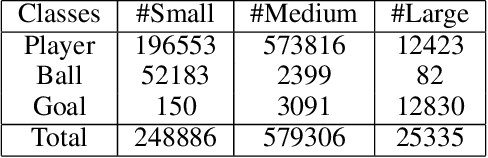
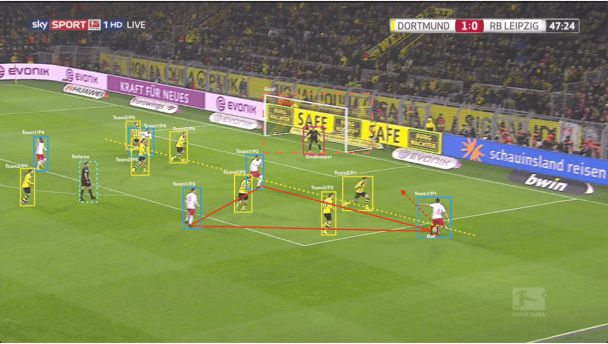
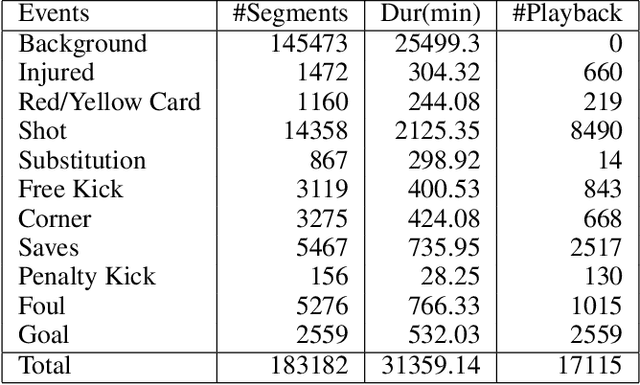
Comprehensive video understanding, a challenging task in computer vision to understand videos like humans, has been explored in ways including object detection and tracking, action classification. However, most works for video understanding mainly focus on isolated aspects of video analysis, yet ignore the inner correlation among those tasks. Sports games videos can serve as a perfect research object with restrictive conditions, while complex and challenging enough to study the core problems in computer vision comprehensively. In this paper, we propose a new soccer video database named SoccerDB with the benchmark of object detection, action recognition, temporal action detection, and highlight detection. We further survey a collection of strong baselines on SoccerDB, which have demonstrated state-of-the-art performance on each independent task in recent years. We believe that the release of SoccerDB will tremendously advance researches of combining different tasks in closed form around the comprehensive video understanding problem. Our dataset and code will be published after the paper accepted.
Comprehensive Video Understanding: Video summarization with content-based video recommender design
Oct 30, 2019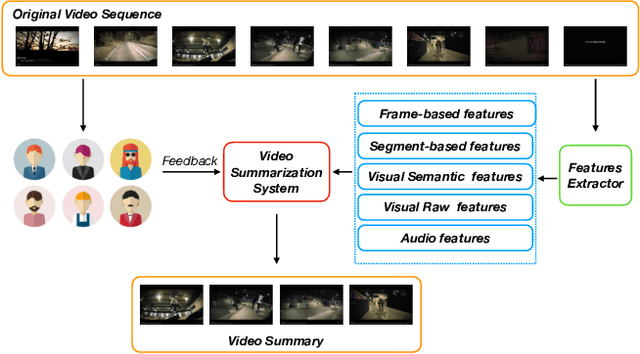
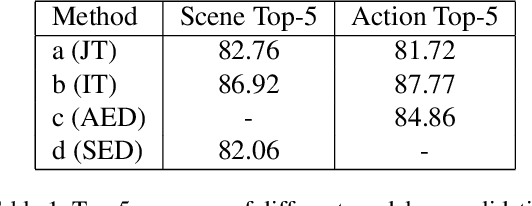
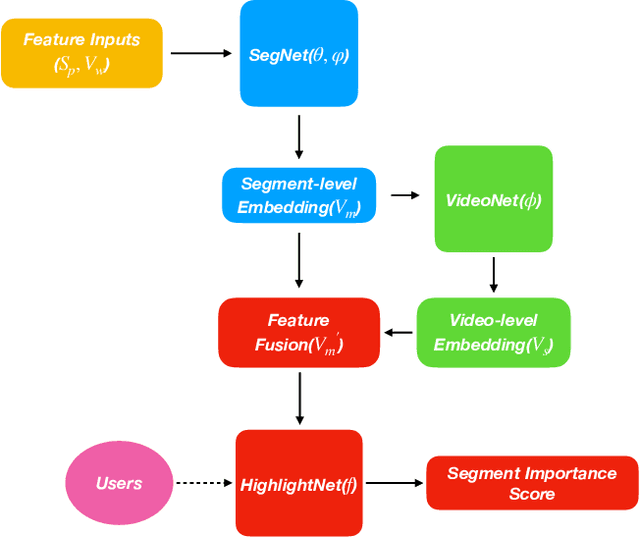
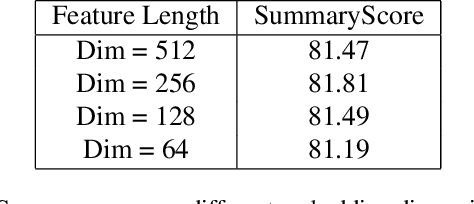
Video summarization aims to extract keyframes/shots from a long video. Previous methods mainly take diversity and representativeness of generated summaries as prior knowledge in algorithm design. In this paper, we formulate video summarization as a content-based recommender problem, which should distill the most useful content from a long video for users who suffer from information overload. A scalable deep neural network is proposed on predicting if one video segment is a useful segment for users by explicitly modelling both segment and video. Moreover, we accomplish scene and action recognition in untrimmed videos in order to find more correlations among different aspects of video understanding tasks. Also, our paper will discuss the effect of audio and visual features in summarization task. We also extend our work by data augmentation and multi-task learning for preventing the model from early-stage overfitting. The final results of our model win the first place in ICCV 2019 CoView Workshop Challenge Track.