 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDE: Task-Isolated Diffusion for Unified Video Editing and Generation
Jun 06, 2026Recent advances in Diffusion Transformers have driven rapid progress in video generation and editing, yet these capabilities are still handled by separate, task-specific models. Building a unified framework that supports diverse video tasks remains an open challenge: existing unified attempts either require dedicated auxiliary encoders or lack explicit mechanisms to distinguish heterogeneous conditioning tokens, struggling when the number and type of visual conditions vary across tasks. We propose TIDE, a unified framework that integrates instruction-based editing, reference-guided editing, and multi-reference generation. At its core, we introduce per-token task embeddings that assign each input token a task-specific identifier, enabling the model to explicitly disambiguate target, source, and reference tokens. To simultaneously capture high-level semantic understanding and fine-grained structural fidelity, we design a dual-path conditioning scheme that couples a vision-language model with a VAE latent path for complementary signals. We further devise a multi-task progressive training strategy that incrementally introduces tasks of increasing complexity, effectively harmonizing diverse objectives and enabling smooth generalization across heterogeneous task distributions. Extensive experiments on multiple video editing and generation benchmarks demonstrate that TIDE achieves state-of-the-art performance across all evaluated tasks. Our project page is available at https://LittleWork123.github.io/tide.
SEAL: Can Saturated Benchmarks Be Revived by LLM-as-a-Meta-Judge?
May 28, 2026Widely used language-model benchmarks are increasingly saturated, with frontier systems often receiving near-tied scores that standard metrics cannot resolve. Rather than constructing harder alternatives, we ask whether existing tasks can be made informative again through improved evaluation over the same candidate outputs. Therefore, we present Seeded Elimination with Adaptive LLM-as-a-Meta-Judge, a self-improving evaluation protocol for extracting latent ranking signal from saturated benchmarks. SEAL seeds candidate outputs into a single elimination and evaluates each match with task-level principles plus self-improving checklist criteria. We evaluate SEAL on multiple saturated benchmarks covering code generation, mathematical reasoning, knowledge-intensive question answering, and tool-use agent task completion. Across these settings, SEAL improves the ranking-accuracy--latency trade-off over competing protocols, attaining 0.83--1.00 Spearman agreement with full pairwise judging and 4/4 top-1 agreement, while requiring only 11.89 calls per task compared with 28.00 for full pairwise evaluation.
DirectorBench: Diagnosing Long-Form Video Generation with Personalized Multi-Agent Evaluation
May 28, 2026Long-form video generation is rapidly moving from short, single-scene synthesis toward minute-long, multi-shot creation with narrative structure, cinematic control, audio, and cross-modal synchronization. However, evaluating such videos remains challenging, since existing benchmarks largely focus on local visual quality, short-horizon temporal consistency, or generic prompt alignment, and provide limited diagnosis of workflow failures and user-dependent preferences. We introduce DirectorBench, a personalized multi-agent diagnostic benchmark for long-form video generation. DirectorBench evaluates generated videos with respect to 80 structured metadata entries, 7 user profiles, and 40 checkpoint criteria across 5 dimensions: script, visual, audio, cross-modal, and stability. Instead of reducing quality to a single aggregate score, DirectorBench localizes checkpoint-level bottlenecks and supports profile-aware evaluation. We evaluate 4 long-form video generation workflows, 6 base LLMs, and 7 user profiles. Across workflows, DirectorBench reveals a between-unit bottleneck: transition quality averages only 0.256 and reaches 0.356 for the best workflow, while prompt-level user demand fulfillment averages 0.71. We further conduct human evaluation with 14 annotators to validate the alignment between DirectorBench and human judgment. The results show that DirectorBench captures human-perceptible quality differences and reveals workflow- and profile-dependent failure modes that are hidden by aggregate scoring. These findings highlight the importance of diagnostic and profile-aware benchmarking for long-form video generation.
AniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025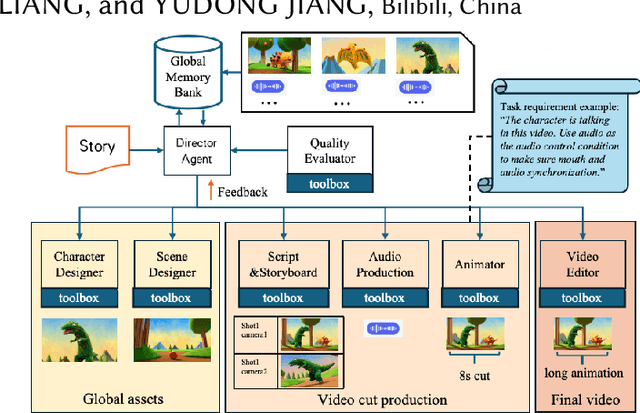
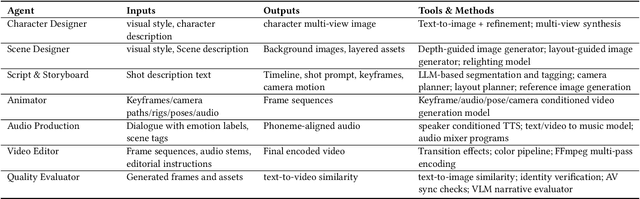

We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025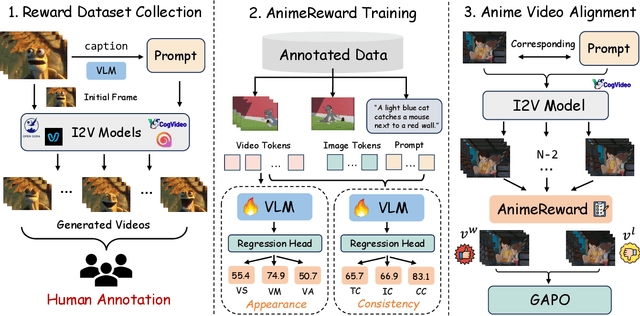

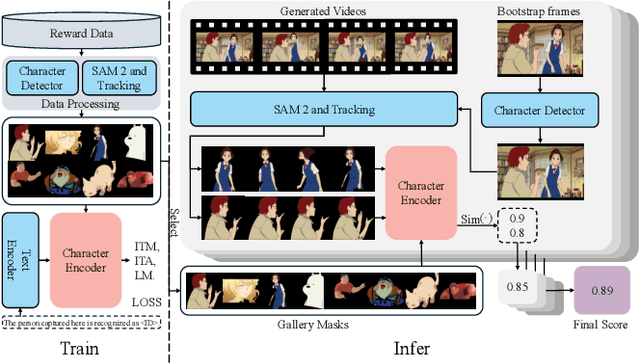
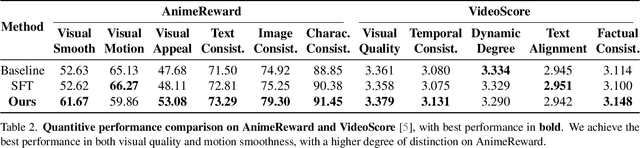
Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
TensorOpt: Exploring the Tradeoffs in Distributed DNN Training with Auto-Parallelism
Apr 16, 2020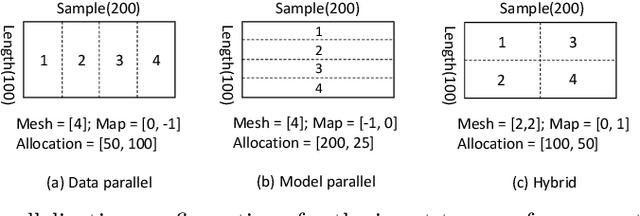
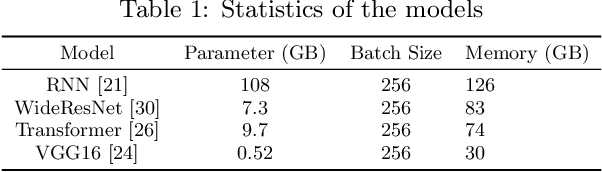
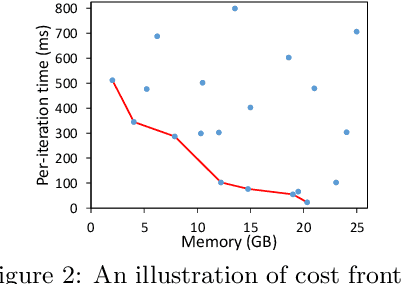

A good parallelization strategy can significantly improve the efficiency or reduce the cost for the distributed training of deep neural networks (DNNs). Recently, several methods have been proposed to find efficient parallelization strategies but they all optimize a single objective (e.g., execution time, memory consumption) and produce only one strategy. We propose FT, an efficient algorithm that searches for an optimal set of parallelization strategies to allow the trade-off among different objectives. FT can adapt to different scenarios by minimizing the memory consumption when the number of devices is limited and fully utilize additional resources to reduce the execution time. For popular DNN models (e.g., vision, language), an in-depth analysis is conducted to understand the trade-offs among different objectives and their influence on the parallelization strategies. We also develop a user-friendly system, called TensorOpt, which allows users to run their distributed DNN training jobs without caring the details of parallelization strategies. Experimental results show that FT runs efficiently and provides accurate estimation of runtime costs, and TensorOpt is more flexible in adapting to resource availability compared with existing frameworks.