 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025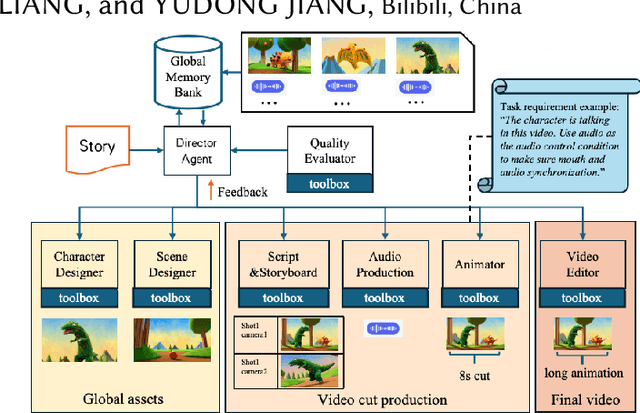
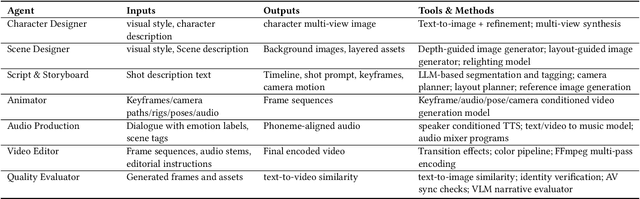

We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025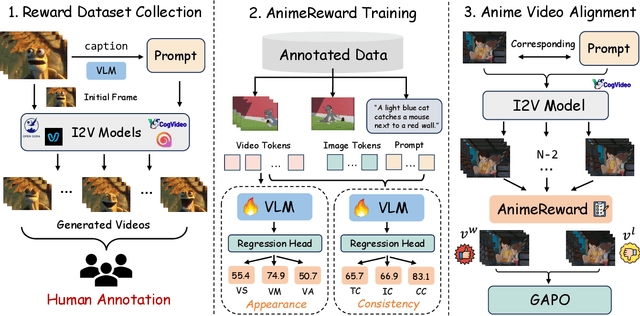

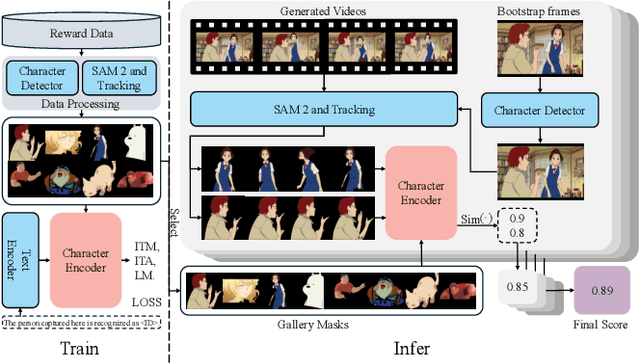
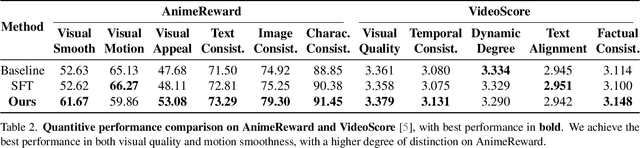
Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
Cross Attention Based Style Distribution for Controllable Person Image Synthesis
Aug 01, 2022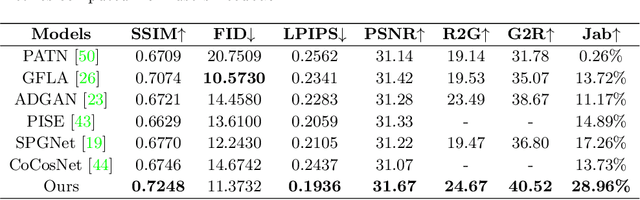
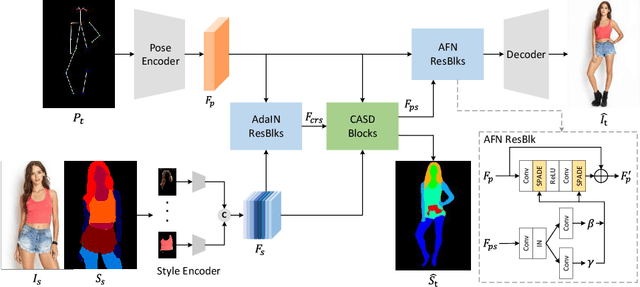
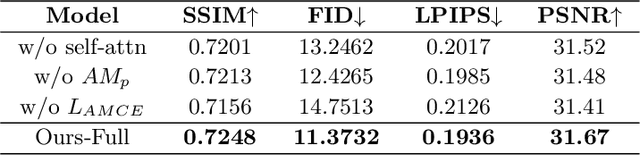
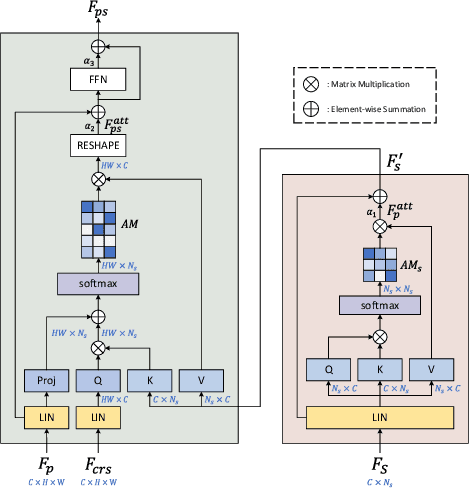
Controllable person image synthesis task enables a wide range of applications through explicit control over body pose and appearance. In this paper, we propose a cross attention based style distribution module that computes between the source semantic styles and target pose for pose transfer. The module intentionally selects the style represented by each semantic and distributes them according to the target pose. The attention matrix in cross attention expresses the dynamic similarities between the target pose and the source styles for all semantics. Therefore, it can be utilized to route the color and texture from the source image, and is further constrained by the target parsing map to achieve a clearer objective. At the same time, to encode the source appearance accurately, the self attention among different semantic styles is also added. The effectiveness of our model is validated quantitatively and qualitatively on pose transfer and virtual try-on tasks.
ID-Unet: Iterative Soft and Hard Deformation for View Synthesis
Mar 18, 2021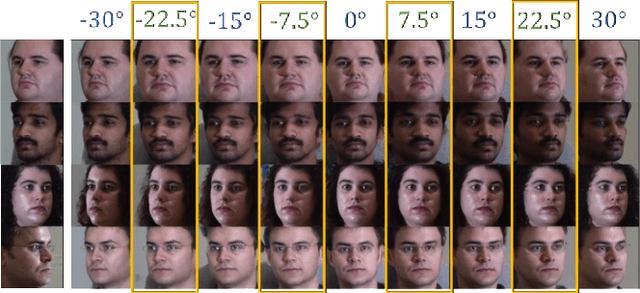
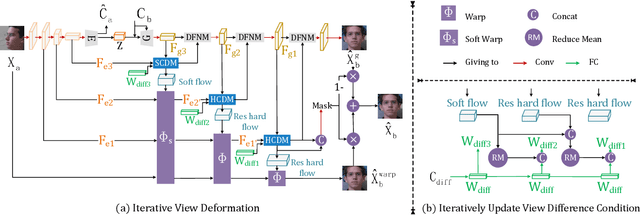
View synthesis is usually done by an autoencoder, in which the encoder maps a source view image into a latent content code, and the decoder transforms it into a target view image according to the condition. However, the source contents are often not well kept in this setting, which leads to unnecessary changes during the view translation. Although adding skipped connections, like Unet, alleviates the problem, but it often causes the failure on the view conformity. This paper proposes a new architecture by performing the source-to-target deformation in an iterative way. Instead of simply incorporating the features from multiple layers of the encoder, we design soft and hard deformation modules, which warp the encoder features to the target view at different resolutions, and give results to the decoder to complement the details. Particularly, the current warping flow is not only used to align the feature of the same resolution, but also as an approximation to coarsely deform the high resolution feature. Then the residual flow is estimated and applied in the high resolution, so that the deformation is built up in the coarse-to-fine fashion. To better constrain the model, we synthesize a rough target view image based on the intermediate flows and their warped features. The extensive ablation studies and the final results on two different data sets show the effectiveness of the proposed model.
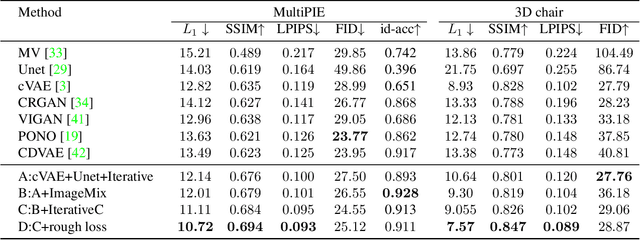
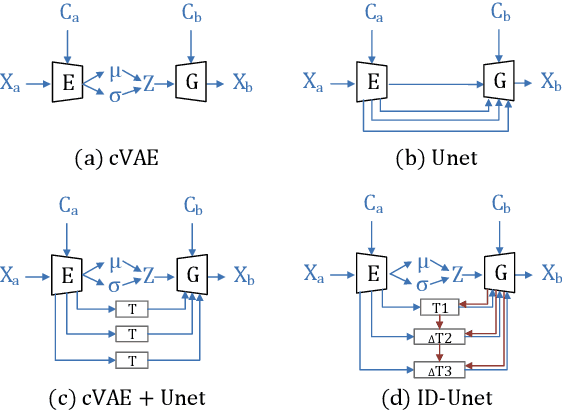
Novel View Synthesis on Unpaired Data by Conditional Deformable Variational Auto-Encoder
Jul 21, 2020

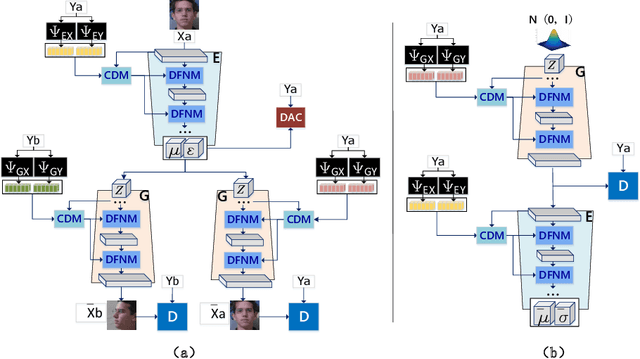
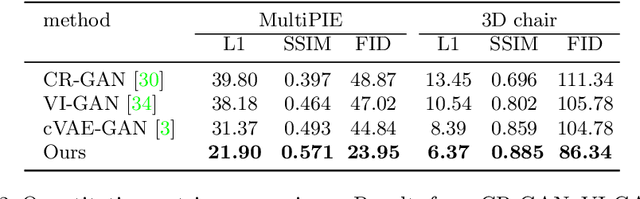
Novel view synthesis often needs the paired data from both the source and target views. This paper proposes a view translation model under cVAE-GAN framework without requiring the paired data. We design a conditional deformable module (CDM) which uses the view condition vectors as the filters to convolve the feature maps of the main branch in VAE. It generates several pairs of displacement maps to deform the features, like the 2D optical flows. The results are fed into the deformed feature based normalization module (DFNM), which scales and offsets the main branch feature, given its deformed one as the input from the side branch. Taking the advantage of the CDM and DFNM, the encoder outputs a view-irrelevant posterior, while the decoder takes the code drawn from it to synthesize the reconstructed and the viewtranslated images. To further ensure the disentanglement between the views and other factors, we add adversarial training on the code. The results and ablation studies on MultiPIE and 3D chair datasets validate the effectiveness of the framework in cVAE and the designed module.