 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025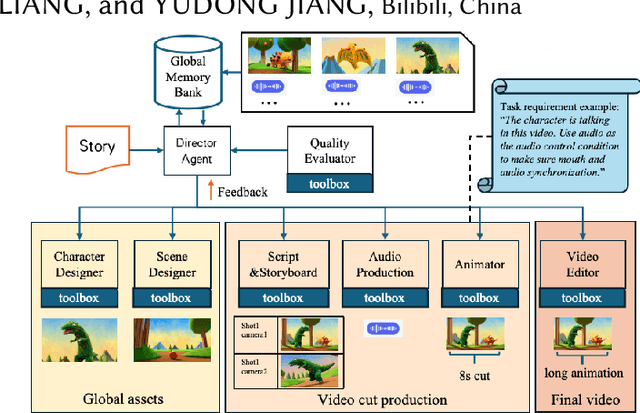
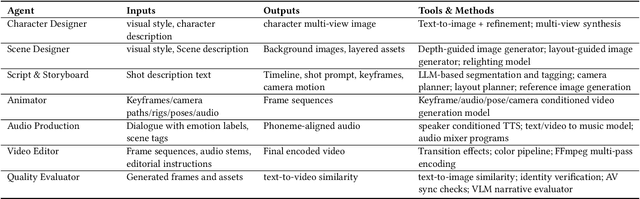

We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.
Aligning Anime Video Generation with Human Feedback
Apr 14, 2025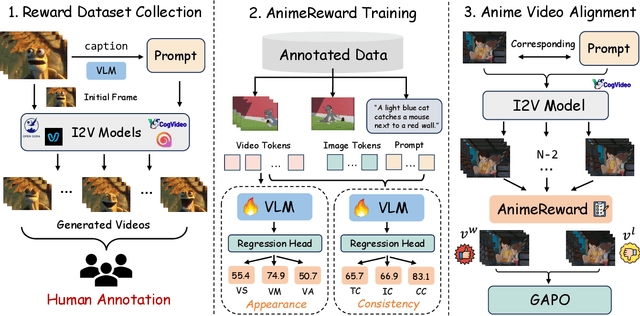

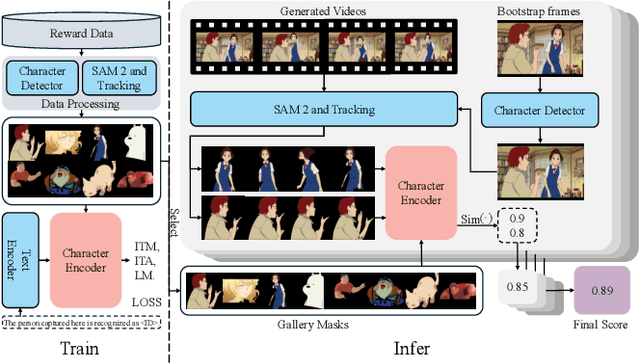
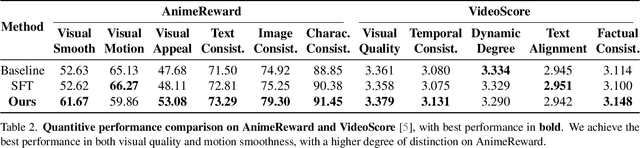
Anime video generation faces significant challenges due to the scarcity of anime data and unusual motion patterns, leading to issues such as motion distortion and flickering artifacts, which result in misalignment with human preferences. Existing reward models, designed primarily for real-world videos, fail to capture the unique appearance and consistency requirements of anime. In this work, we propose a pipeline to enhance anime video generation by leveraging human feedback for better alignment. Specifically, we construct the first multi-dimensional reward dataset for anime videos, comprising 30k human-annotated samples that incorporating human preferences for both visual appearance and visual consistency. Based on this, we develop AnimeReward, a powerful reward model that employs specialized vision-language models for different evaluation dimensions to guide preference alignment. Furthermore, we introduce Gap-Aware Preference Optimization (GAPO), a novel training method that explicitly incorporates preference gaps into the optimization process, enhancing alignment performance and efficiency. Extensive experiment results show that AnimeReward outperforms existing reward models, and the inclusion of GAPO leads to superior alignment in both quantitative benchmarks and human evaluations, demonstrating the effectiveness of our pipeline in enhancing anime video quality. Our dataset and code will be publicly available.
AniSora: Exploring the Frontiers of Animation Video Generation in the Sora Era
Dec 19, 2024



Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. Our evaluation benchmark will be publicly available at https://github.com/bilibili/Index-anisora.
Exploring the Frontiers of Animation Video Generation in the Sora Era: Method, Dataset and Benchmark
Dec 13, 2024Animation has gained significant interest in the recent film and TV industry. Despite the success of advanced video generation models like Sora, Kling, and CogVideoX in generating natural videos, they lack the same effectiveness in handling animation videos. Evaluating animation video generation is also a great challenge due to its unique artist styles, violating the laws of physics and exaggerated motions. In this paper, we present a comprehensive system, AniSora, designed for animation video generation, which includes a data processing pipeline, a controllable generation model, and an evaluation dataset. Supported by the data processing pipeline with over 10M high-quality data, the generation model incorporates a spatiotemporal mask module to facilitate key animation production functions such as image-to-video generation, frame interpolation, and localized image-guided animation. We also collect an evaluation benchmark of 948 various animation videos, the evaluation on VBench and human double-blind test demonstrates consistency in character and motion, achieving state-of-the-art results in animation video generation. %We also collect an evaluation benchmark of 948 various animation videos, with specifically developed metrics for animation video generation. Our model access API and evaluation benchmark will be publicly available.
Clustered-patch Element Connection for Few-shot Learning
Apr 20, 2023



Weak feature representation problem has influenced the performance of few-shot classification task for a long time. To alleviate this problem, recent researchers build connections between support and query instances through embedding patch features to generate discriminative representations. However, we observe that there exists semantic mismatches (foreground/ background) among these local patches, because the location and size of the target object are not fixed. What is worse, these mismatches result in unreliable similarity confidences, and complex dense connection exacerbates the problem. According to this, we propose a novel Clustered-patch Element Connection (CEC) layer to correct the mismatch problem. The CEC layer leverages Patch Cluster and Element Connection operations to collect and establish reliable connections with high similarity patch features, respectively. Moreover, we propose a CECNet, including CEC layer based attention module and distance metric. The former is utilized to generate a more discriminative representation benefiting from the global clustered-patch features, and the latter is introduced to reliably measure the similarity between pair-features. Extensive experiments demonstrate that our CECNet outperforms the state-of-the-art methods on classification benchmark. Furthermore, our CEC approach can be extended into few-shot segmentation and detection tasks, which achieves competitive performances.
SpatialFormer: Semantic and Target Aware Attentions for Few-Shot Learning
Mar 15, 2023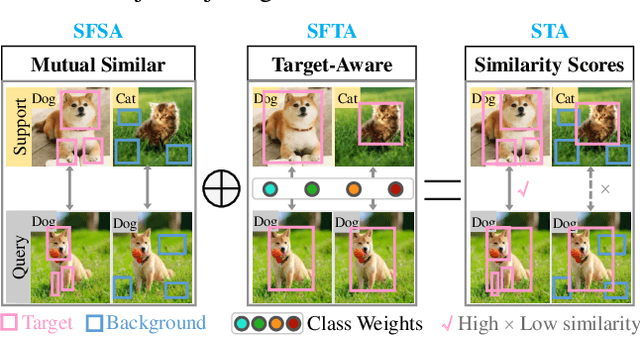

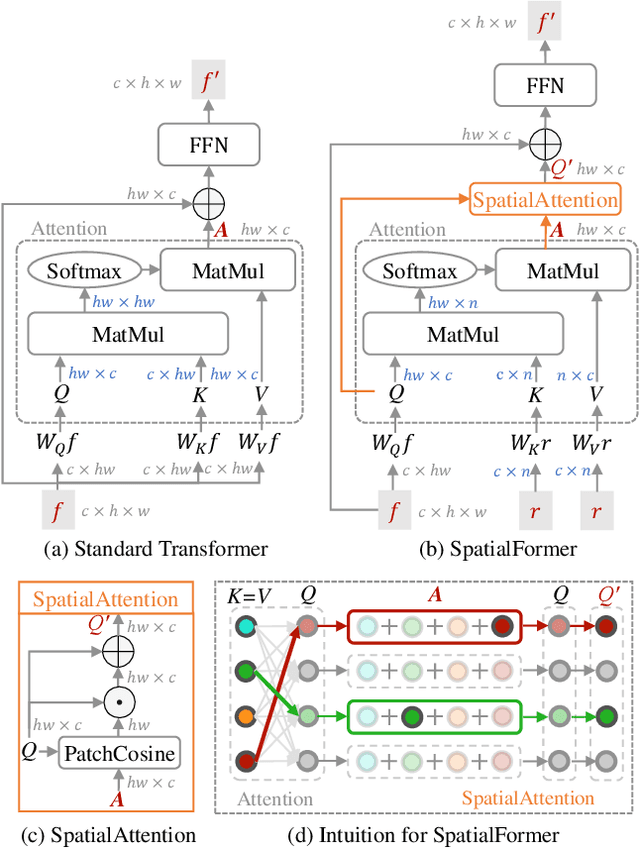

Recent Few-Shot Learning (FSL) methods put emphasis on generating a discriminative embedding features to precisely measure the similarity between support and query sets. Current CNN-based cross-attention approaches generate discriminative representations via enhancing the mutually semantic similar regions of support and query pairs. However, it suffers from two problems: CNN structure produces inaccurate attention map based on local features, and mutually similar backgrounds cause distraction. To alleviate these problems, we design a novel SpatialFormer structure to generate more accurate attention regions based on global features. Different from the traditional Transformer modeling intrinsic instance-level similarity which causes accuracy degradation in FSL, our SpatialFormer explores the semantic-level similarity between pair inputs to boost the performance. Then we derive two specific attention modules, named SpatialFormer Semantic Attention (SFSA) and SpatialFormer Target Attention (SFTA), to enhance the target object regions while reduce the background distraction. Particularly, SFSA highlights the regions with same semantic information between pair features, and SFTA finds potential foreground object regions of novel feature that are similar to base categories. Extensive experiments show that our methods are effective and achieve new state-of-the-art results on few-shot classification benchmarks.
Exploring Efficient Few-shot Adaptation for Vision Transformers
Jan 06, 2023The task of Few-shot Learning (FSL) aims to do the inference on novel categories containing only few labeled examples, with the help of knowledge learned from base categories containing abundant labeled training samples. While there are numerous works into FSL task, Vision Transformers (ViTs) have rarely been taken as the backbone to FSL with few trials focusing on naive finetuning of whole backbone or classification layer.} Essentially, despite ViTs have been shown to enjoy comparable or even better performance on other vision tasks, it is still very nontrivial to efficiently finetune the ViTs in real-world FSL scenarios. To this end, we propose a novel efficient Transformer Tuning (eTT) method that facilitates finetuning ViTs in the FSL tasks. The key novelties come from the newly presented Attentive Prefix Tuning (APT) and Domain Residual Adapter (DRA) for the task and backbone tuning, individually. Specifically, in APT, the prefix is projected to new key and value pairs that are attached to each self-attention layer to provide the model with task-specific information. Moreover, we design the DRA in the form of learnable offset vectors to handle the potential domain gaps between base and novel data. To ensure the APT would not deviate from the initial task-specific information much, we further propose a novel prototypical regularization, which maximizes the similarity between the projected distribution of prefix and initial prototypes, regularizing the update procedure. Our method receives outstanding performance on the challenging Meta-Dataset. We conduct extensive experiments to show the efficacy of our model.
Split-PU: Hardness-aware Training Strategy for Positive-Unlabeled Learning
Nov 30, 2022
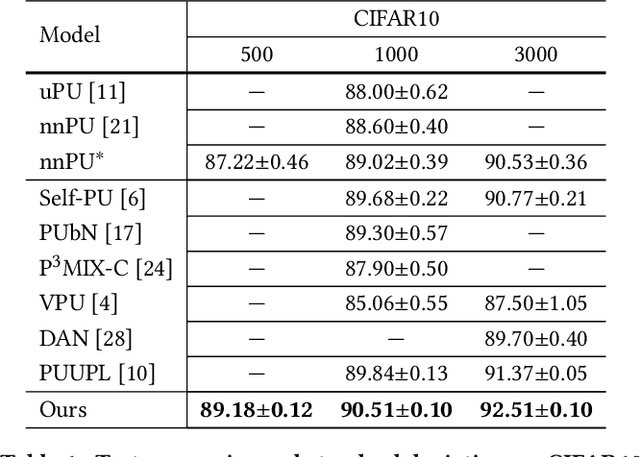
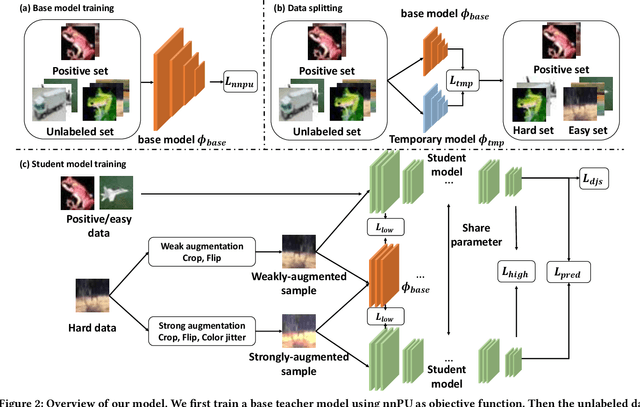
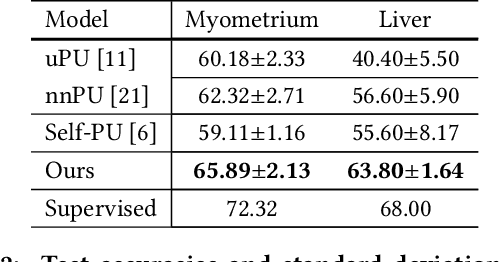
Positive-Unlabeled (PU) learning aims to learn a model with rare positive samples and abundant unlabeled samples. Compared with classical binary classification, the task of PU learning is much more challenging due to the existence of many incompletely-annotated data instances. Since only part of the most confident positive samples are available and evidence is not enough to categorize the rest samples, many of these unlabeled data may also be the positive samples. Research on this topic is particularly useful and essential to many real-world tasks which demand very expensive labelling cost. For example, the recognition tasks in disease diagnosis, recommendation system and satellite image recognition may only have few positive samples that can be annotated by the experts. These methods mainly omit the intrinsic hardness of some unlabeled data, which can result in sub-optimal performance as a consequence of fitting the easy noisy data and not sufficiently utilizing the hard data. In this paper, we focus on improving the commonly-used nnPU with a novel training pipeline. We highlight the intrinsic difference of hardness of samples in the dataset and the proper learning strategies for easy and hard data. By considering this fact, we propose first splitting the unlabeled dataset with an early-stop strategy. The samples that have inconsistent predictions between the temporary and base model are considered as hard samples. Then the model utilizes a noise-tolerant Jensen-Shannon divergence loss for easy data; and a dual-source consistency regularization for hard data which includes a cross-consistency between student and base model for low-level features and self-consistency for high-level features and predictions, respectively.
PatchMix Augmentation to Identify Causal Features in Few-shot Learning
Nov 29, 2022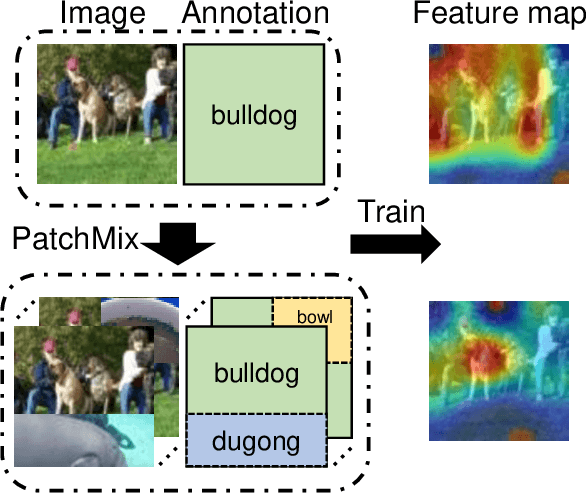
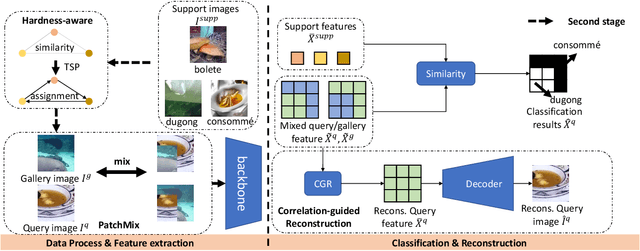
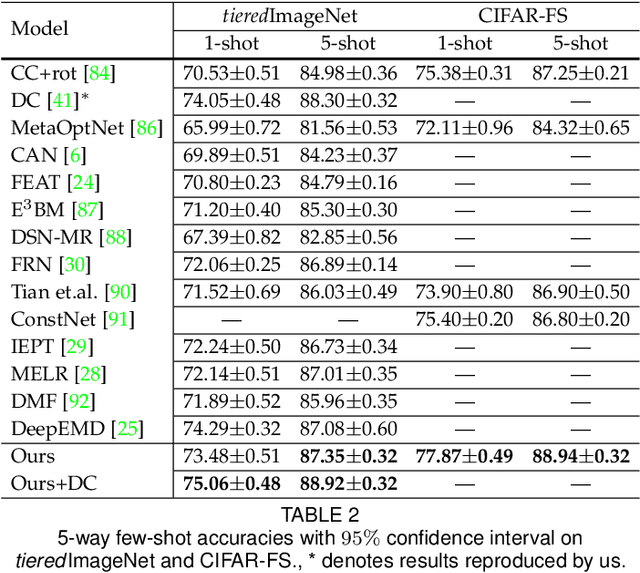
The task of Few-shot learning (FSL) aims to transfer the knowledge learned from base categories with sufficient labelled data to novel categories with scarce known information. It is currently an important research question and has great practical values in the real-world applications. Despite extensive previous efforts are made on few-shot learning tasks, we emphasize that most existing methods did not take into account the distributional shift caused by sample selection bias in the FSL scenario. Such a selection bias can induce spurious correlation between the semantic causal features, that are causally and semantically related to the class label, and the other non-causal features. Critically, the former ones should be invariant across changes in distributions, highly related to the classes of interest, and thus well generalizable to novel classes, while the latter ones are not stable to changes in the distribution. To resolve this problem, we propose a novel data augmentation strategy dubbed as PatchMix that can break this spurious dependency by replacing the patch-level information and supervision of the query images with random gallery images from different classes from the query ones. We theoretically show that such an augmentation mechanism, different from existing ones, is able to identify the causal features. To further make these features to be discriminative enough for classification, we propose Correlation-guided Reconstruction (CGR) and Hardness-Aware module for instance discrimination and easier discrimination between similar classes. Moreover, such a framework can be adapted to the unsupervised FSL scenario.
tSF: Transformer-based Semantic Filter for Few-Shot Learning
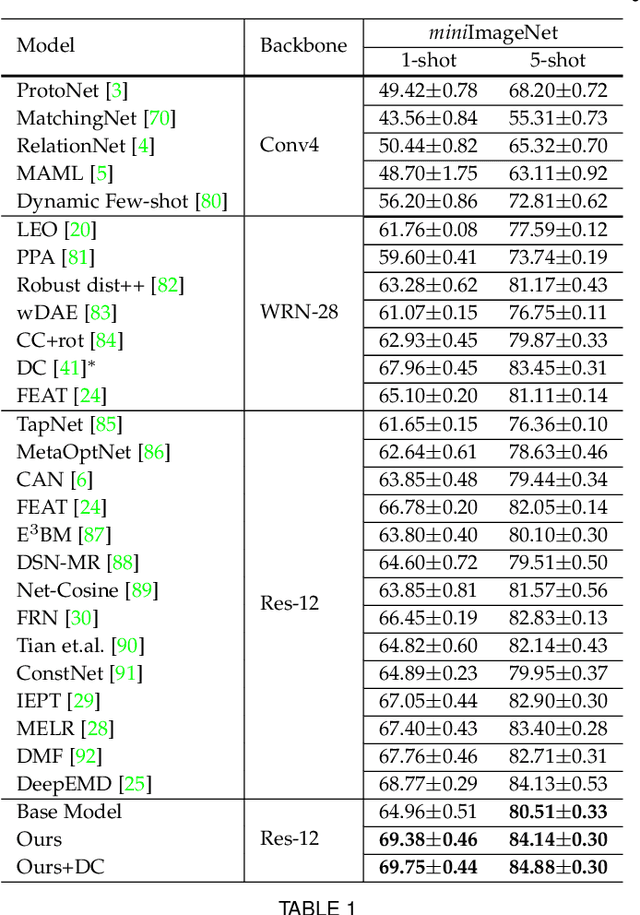
Nov 02, 2022Few-Shot Learning (FSL) alleviates the data shortage challenge via embedding discriminative target-aware features among plenty seen (base) and few unseen (novel) labeled samples. Most feature embedding modules in recent FSL methods are specially designed for corresponding learning tasks (e.g., classification, segmentation, and object detection), which limits the utility of embedding features. To this end, we propose a light and universal module named transformer-based Semantic Filter (tSF), which can be applied for different FSL tasks. The proposed tSF redesigns the inputs of a transformer-based structure by a semantic filter, which not only embeds the knowledge from whole base set to novel set but also filters semantic features for target category. Furthermore, the parameters of tSF is equal to half of a standard transformer block (less than 1M). In the experiments, our tSF is able to boost the performances in different classic few-shot learning tasks (about 2% improvement), especially outperforms the state-of-the-arts on multiple benchmark datasets in few-shot classification task.