 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSplit-PU: Hardness-aware Training Strategy for Positive-Unlabeled Learning
Nov 30, 2022
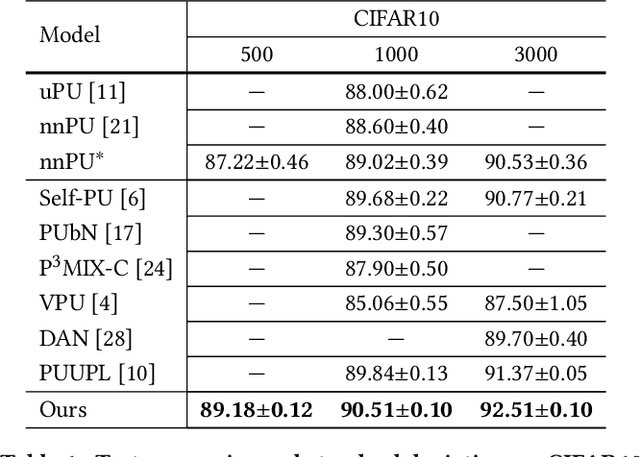
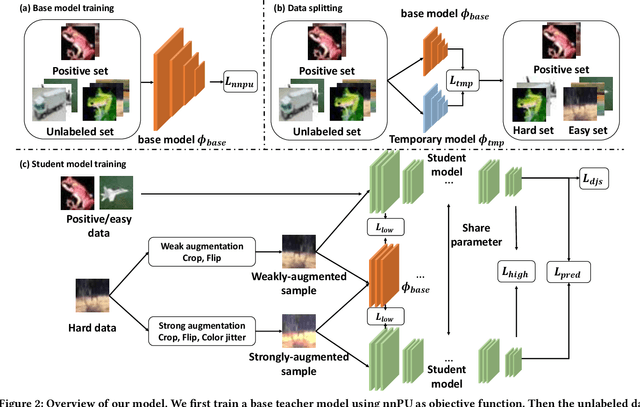
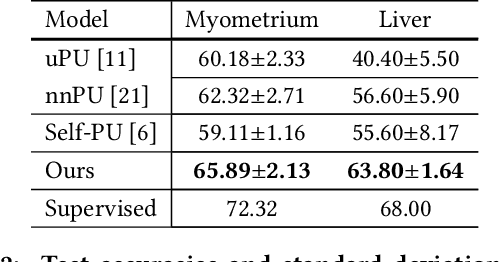
Positive-Unlabeled (PU) learning aims to learn a model with rare positive samples and abundant unlabeled samples. Compared with classical binary classification, the task of PU learning is much more challenging due to the existence of many incompletely-annotated data instances. Since only part of the most confident positive samples are available and evidence is not enough to categorize the rest samples, many of these unlabeled data may also be the positive samples. Research on this topic is particularly useful and essential to many real-world tasks which demand very expensive labelling cost. For example, the recognition tasks in disease diagnosis, recommendation system and satellite image recognition may only have few positive samples that can be annotated by the experts. These methods mainly omit the intrinsic hardness of some unlabeled data, which can result in sub-optimal performance as a consequence of fitting the easy noisy data and not sufficiently utilizing the hard data. In this paper, we focus on improving the commonly-used nnPU with a novel training pipeline. We highlight the intrinsic difference of hardness of samples in the dataset and the proper learning strategies for easy and hard data. By considering this fact, we propose first splitting the unlabeled dataset with an early-stop strategy. The samples that have inconsistent predictions between the temporary and base model are considered as hard samples. Then the model utilizes a noise-tolerant Jensen-Shannon divergence loss for easy data; and a dual-source consistency regularization for hard data which includes a cross-consistency between student and base model for low-level features and self-consistency for high-level features and predictions, respectively.
The Report on China-Spain Joint Clinical Testing for Rapid COVID-19 Risk Screening by Eye-region Manifestations
Sep 18, 2021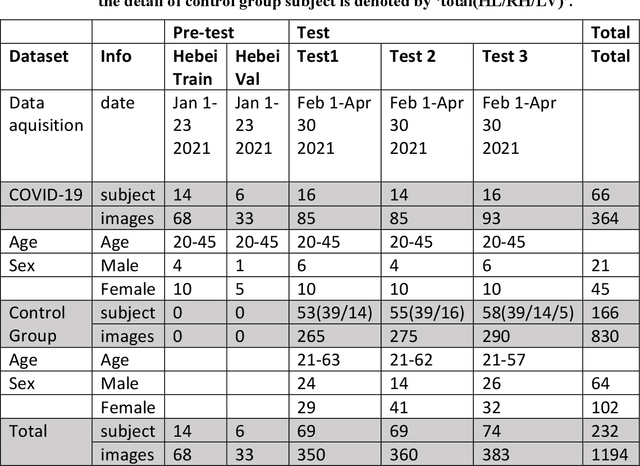

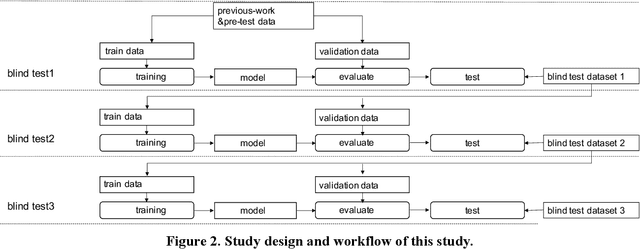
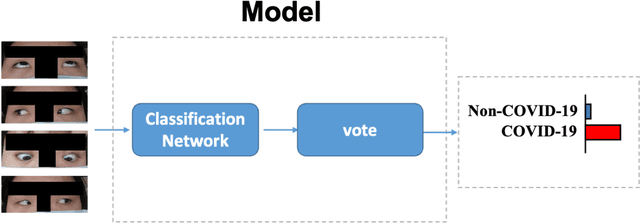
Background: The worldwide surge in coronavirus cases has led to the COVID-19 testing demand surge. Rapid, accurate, and cost-effective COVID-19 screening tests working at a population level are in imperative demand globally. Methods: Based on the eye symptoms of COVID-19, we developed and tested a COVID-19 rapid prescreening model using the eye-region images captured in China and Spain with cellphone cameras. The convolutional neural networks (CNNs)-based model was trained on these eye images to complete binary classification task of identifying the COVID-19 cases. The performance was measured using area under receiver-operating-characteristic curve (AUC), sensitivity, specificity, accuracy, and F1. The application programming interface was open access. Findings: The multicenter study included 2436 pictures corresponding to 657 subjects (155 COVID-19 infection, 23.6%) in development dataset (train and validation) and 2138 pictures corresponding to 478 subjects (64 COVID-19 infections, 13.4%) in test dataset. The image-level performance of COVID-19 prescreening model in the China-Spain multicenter study achieved an AUC of 0.913 (95% CI, 0.898-0.927), with a sensitivity of 0.695 (95% CI, 0.643-0.748), a specificity of 0.904 (95% CI, 0.891 -0.919), an accuracy of 0.875(0.861-0.889), and a F1 of 0.611(0.568-0.655). Interpretation: The CNN-based model for COVID-19 rapid prescreening has reliable specificity and sensitivity. This system provides a low-cost, fully self-performed, non-invasive, real-time feedback solution for continuous surveillance and large-scale rapid prescreening for COVID-19. Funding: This project is supported by Aimomics (Shanghai) Intelligent